As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Minimize a sobrecarga de planejamento
Conforme discutido nos principais tópicos do Apache Spark, o driver do Spark gera o plano de execução. Com base nesse plano, as tarefas são atribuídas ao executor do Spark para processamento distribuído. No entanto, o driver do Spark pode se tornar um gargalo se houver um grande número de arquivos pequenos ou se ele AWS Glue Data Catalog contiver um grande número de partições. Para identificar a alta sobrecarga de planejamento, avalie as seguintes métricas.
CloudWatch métricas
Verifique a CPUcarga e a utilização da memória nas seguintes situações:
-
A CPUcarga do driver Spark e a utilização da memória são registradas como altas. Normalmente, o driver do Spark não processa seus dados, portanto, a CPU carga e a utilização da memória não aumentam. No entanto, se a fonte de dados do Amazon S3 tiver muitos arquivos pequenos, listar todos os objetos do S3 e gerenciar um grande número de tarefas pode fazer com que a utilização dos recursos seja alta.
-
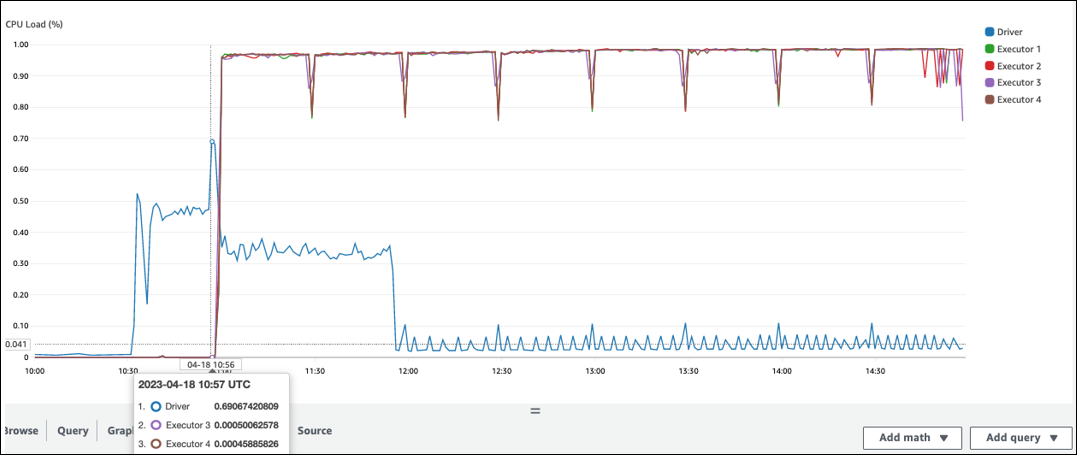
Há uma grande lacuna antes do início do processamento no executor do Spark. No exemplo de captura de tela a seguir, a CPU carga do executor do Spark está muito baixa até 10:57, mesmo que o trabalho tenha começado às 10:00. AWS Glue Isso indica que o driver do Spark pode estar demorando muito para gerar um plano de execução. Neste exemplo, recuperar o grande número de partições no Catálogo de Dados e listar o grande número de arquivos pequenos no driver do Spark está demorando muito.
IU do Spark
Na guia Job na interface do Spark, você pode ver o horário de envio. No exemplo a seguir, o driver do Spark iniciou o job0 às 10:56:46, embora o trabalho tenha começado às 10:00:00. AWS Glue

Você também pode ver as Tarefas (para todos os estágios): Suceeded/Total time na guia Job. Nesse caso, o número de tarefas é registrado como58100. Conforme explicado na seção Amazon S3 da página de tarefas do Parallelize, o número de tarefas corresponde aproximadamente ao número de objetos do S3. Isso significa que há cerca de 58.100 objetos no Amazon S3.
Para obter mais detalhes sobre esse trabalho e o cronograma, consulte a guia Estágio. Se você observar um gargalo com o driver do Spark, considere as seguintes soluções:
-
Quando o Amazon S3 tem muitas partições, considere a orientação sobre particionamento excessivo na seção Muitas partições do Amazon S3 da página Reduzir a quantidade de varredura de dados. Ative os índices de AWS Glue partição se houver muitas partições para reduzir a latência na recuperação de metadados de partição do Catálogo de Dados. Para obter mais informações, consulte Melhorar o desempenho da consulta usando índices de AWS Glue partição
. -
Quando JDBC tiver muitas partições, diminua o
hashpartitionvalor. -
Quando o DynamoDB tiver muitas partições, diminua o valor.
dynamodb.splits -
Quando os trabalhos de streaming tiverem muitas partições, diminua o número de fragmentos.
