Realizar uma prova de conceito (POC) para o Amazon Redshift
O Amazon Redshift, um conhecido data warehouse na nuvem, oferece um serviço totalmente gerenciado baseado em nuvem que se integra ao data lake do Amazon Simple Storage Service de uma organização, fluxos de trabalho em tempo real, fluxos de trabalho de machine learning (ML), fluxos de trabalho transacionais e muito mais. As seções a seguir orientam você no processo de realização de uma prova de conceito (POC) no Amazon Redshift. As informações aqui ajudam você a definir metas para a POC e aproveitam as ferramentas que podem automatizar o provisionamento e a configuração de serviços para a POC.
nota
Tenha uma cópia dessas informações em PDF no link Execute sua própria POC do Redshift na página Recursos do Amazon Redshift
Ao fazer uma POC do Amazon Redshift, você testa, comprova e adota recursos que vão desde recursos de segurança de ponta, escalabilidade elástica, facilidade de integração e ingestão e opções flexíveis de arquitetura de dados descentralizada.

Siga estas etapas para realizar uma POC bem-sucedida.
Etapa 1: Definir o escopo da POC

Ao realizar uma POC, você pode optar por usar seus próprios dados ou usar conjuntos de dados de referência. Ao optar por seus próprios dados, você executa suas próprias consultas nos dados. Com os dados de referência, são fornecidas consultas de exemplo com a referência. Consulte Usar conjuntos de dados de amostra para obter mais detalhes se você achar que ainda não é o momento certo para realizar uma POC com seus próprios dados.
Geralmente, recomendamos usar duas semanas de dados para uma POC do Amazon Redshift.
Primeiro, faça o seguinte:
Identifique seus requisitos comerciais e funcionais e, seguida, trabalhe de trás para frente. Exemplos comuns são: desempenho mais rápido, custos mais baixos, teste de uma nova workload ou um novo recurso ou comparação entre o Amazon Redshift e outro data warehouse.
Estabeleça metas específicas para que se tornem os critérios de sucesso para a POC. Por exemplo, com base no desempenho mais rápido, crie uma lista dos cinco principais processos que você deseja acelerar e inclua os tempos de execução atuais com o tempo de execução necessário. Podem ser relatórios, consultas, processos de ETL, ingestão de dados ou qualquer um de seus pontos problemáticos atuais.
Identifique o escopo e os artefatos específicos necessários para executar os testes. Quais conjuntos de dados você precisa migrar ou ingerir continuamente no Amazon Redshift e quais consultas e processos são necessários para executar os testes e avaliar os critérios de sucesso? Há duas maneiras de fazer isso:
Traga seus próprios dados
Para testar seus próprios dados, crie uma lista mínima viável de artefatos de dados necessários para testar seus critérios de sucesso. Por exemplo, se seu data warehouse atual tem 200 tabelas, mas os relatórios que você deseja testar precisam apenas de 20, sua POC pode ser realizada mais rapidamente usando somente o subconjunto menor de tabelas.
Usar conjuntos de dados de amostra
Se você não tiver seus próprios conjuntos de dados prontos, mesmo assim poderá começar a realizar uma POC no Amazon Redshift usando os conjuntos de dados de referência padrão do setor, como TPC-DS
ou TPC-H , e executar consultas de exemplo de referência para aproveitar o potencial do Amazon Redshift. Depois de criados, esses conjuntos de dados podem ser acessados por meio do data warehouse do Amazon Redshift. Para obter instruções detalhadas sobre como acessar esses conjuntos de dados e consultas de exemplo, consulte Etapa 2: Iniciar o Amazon Redshift.
Etapa 2: Iniciar o Amazon Redshift

O Amazon Redshift acelera seu tempo de obtenção de insights com armazenamento de dados rápido, fácil, seguro e em grande escalar. Você pode começar rapidamente iniciando seu warehouse no console do Redshift sem servidor
Configurar o Amazon Redshift sem servidor
Na primeira vez que você usa o Redshift sem servidor, o console conduz você pelas etapas necessárias para iniciar o warehouse. Você também pode ser elegível para receber um crédito pelo uso do Redshift sem servidor em sua conta. Para obter mais informações sobre a escolha de um teste gratuito, consulteTeste gratuito do Amazon Redshift
Se você já iniciou o Redshift sem servidor em sua conta, siga as etapas em Criar um grupo de trabalho com um namespace no Guia de gerenciamento do Amazon Redshift. Depois que o warehouse estiver disponível, você poderá optar por carregar os dados de amostra disponíveis no Amazon Redshift. Para obter mais informações sobre o Editor de Consultas do Amazon Redshift v2, acesse Carregar dados de exemplo no Guia de gerenciamento do Amazon Redshift.
Se você estiver trazendo seus próprios dados, e não carregando o conjunto de dados de amostra, consulte Etapa 3: Carregar os dados.
Etapa 3: Carregar os dados

Depois de iniciar o Redshift sem servidor, a etapa seguinte é carregar os dados para a POC. Se você estiver carregando um arquivo CSV simples, ingerindo dados semiestruturados do S3 ou transmitindo dados diretamente, o Amazon Redshift oferece a flexibilidade de mover os dados da fonte para as tabelas do Amazon Redshift com rapidez e facilidade.
Escolha um dos métodos a seguir para carregar os dados.
Carregar um arquivo local
Para agilizar a ingestão e análise, você pode usar o Editor de Consultas do Amazon Redshift v2 para carregar facilmente arquivos de dados do seu desktop local. Ele tem capacidade para processar arquivos em vários formatos, como CSV, JSON, AVRO, PARQUET, ORC e muito mais. Para permitir que seus usuários, como um administrador, carreguem dados de um desktop local usando o editor de consultas v2, é necessário especificar um bucket comum do Amazon S3 e a conta do usuário deve ser configurada com as permissões adequadas. Você pode acompanhar a publicação Data load made easy and secure in Amazon Redshift using Query Editor V2
Carregar um arquivo do Amazon S3
Para carregar dados de um bucket do Amazon S3 no Amazon Redshift, primeiro use o comando COPY e especifique o local de origem do Amazon S3 e a tabela de destino do Amazon Redshift. Os perfis do IAM e as permissões devem estar configurados adequadamente para permitir que o Amazon Redshift acesse o bucket designado do Amazon S3. Siga o Tutorial: Carregar dados do Amazon S3 para obter orientações detalhadas. Você também pode escolher a opção Carregar dados no editor de consultas v2 para carregar dados diretamente do bucket do S3.
Ingestão de dados contínua
A cópia automática (em versão de demonstração) é uma extensão do comando COPY e automatiza o carregamento contínuo de dados dos buckets do Amazon S3. Quando você cria um trabalho COPY, o Amazon Redshift detecta quando são criados arquivos do Amazon S3 em um caminho especificado e os carrega automaticamente sem sua intervenção. O Amazon Redshift monitora os arquivos carregados para verificar se eles são carregados apenas uma vez. Para obter instruções sobre como criar trabalhos de cópia, consulte COPY JOB (pré-visualização)
nota
No momento, a cópia automática está em versão de demonstração e só pode ser usada em clusters provisionados em Regiões da AWS específicas. Para criar um cluster de visualização prévia para cópia automática, consulte Carregar tabelas com ingestão contínua de arquivos do Amazon S3 (visualização prévia).
Carregar dados de streaming
A ingestão de streaming fornece ingestão de dados de fluxo de baixa latência e alta velocidade do Amazon Kinesis Data Streams
Etapa 4: Analisar os dados

Depois de criar seu grupo de trabalho e namespace do Redshift sem servidor e carregar os dados, você pode executar consultas imediatamente abrindo o Editor de consultas v2 no painel de navegação do console do Redshift sem servidor
Realizar consultas com o Editor de Consultas do Amazon Redshift v2
É possível usar o editor de consultas v2 pelo console do Amazon Redshift. Consulte Simplify your data analysis with Amazon Redshift query editor v2
Como alternativa, se você quiser executar um teste de carga como parte da POC, é possível fazê-lo seguindo as etapas a seguir para instalar e executar o Apache JMeter.
Executar um teste de carga usando o Apache JMeter
Para realizar um teste de carga e simular “N” usuários que estão enviando consultas simultaneamente ao Amazon Redshift, você pode usar o Apache JMeter
Para instalar e configurar o Apache JMeter para ser executado em seu grupo de trabalho do Redshift sem servidor, siga as instruções em Automate Amazon Redshift load testing with the AWS Analytics Automation Toolkit
Depois de concluir a personalização de suas instruções SQL e finalizar seu plano de teste, salve-o e execute-o em seu grupo de trabalho do Redshift sem servidor. Para monitorar o andamento do seu teste, abra o console do Redshift sem servidor
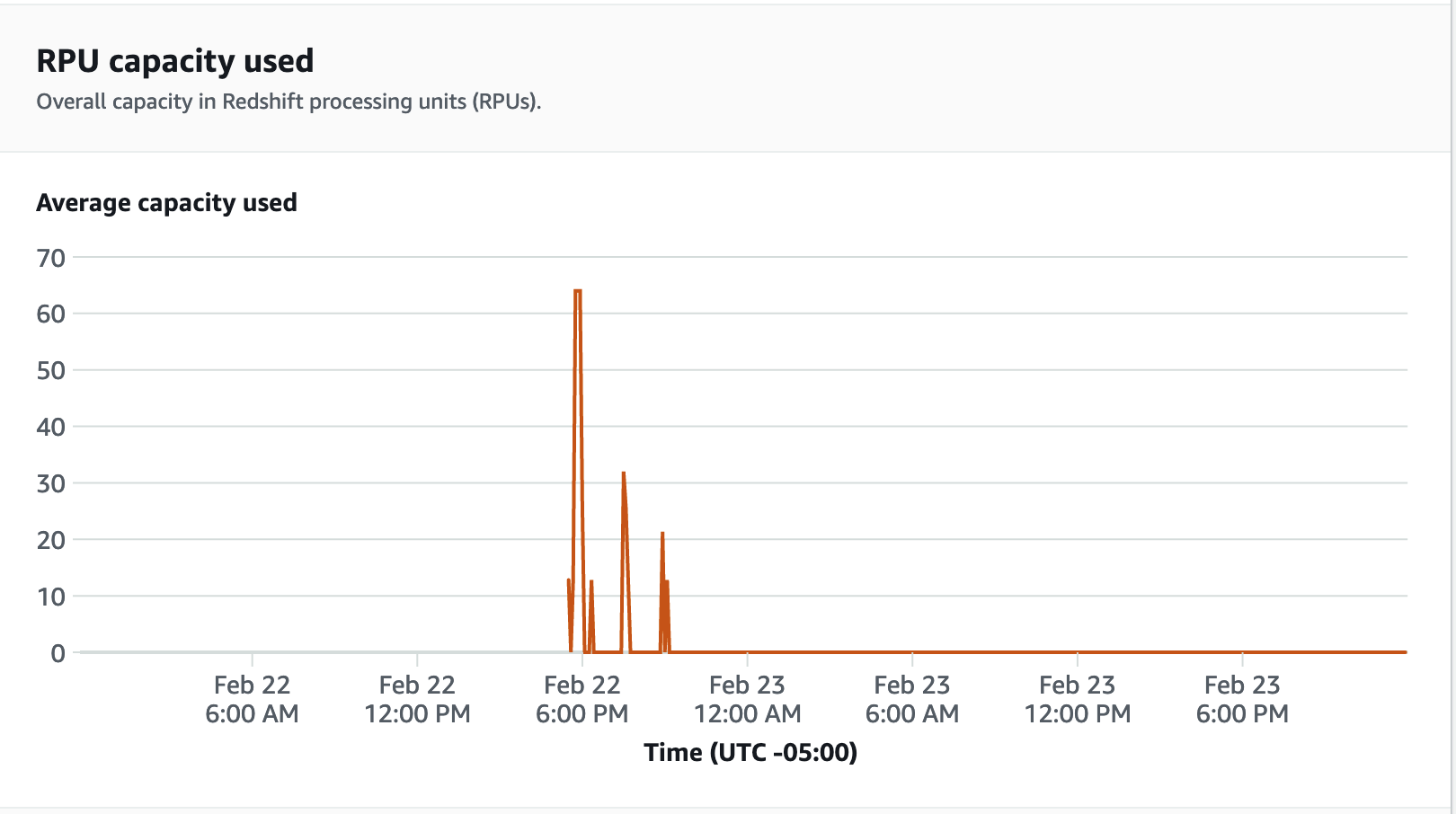
Para métricas de desempenho, escolha a guia Desempenho do banco de dados no console do Redshift sem servidor para monitorar métricas como Conexões de banco de dados e Utilização da CPU. Aqui você pode ver um grafo para monitorar a capacidade de RPU usada e observar como o Redshift sem servidor é escalado automaticamente para atender às demandas simultâneas de workload enquanto o teste de carga está sendo executado no grupo de trabalho.
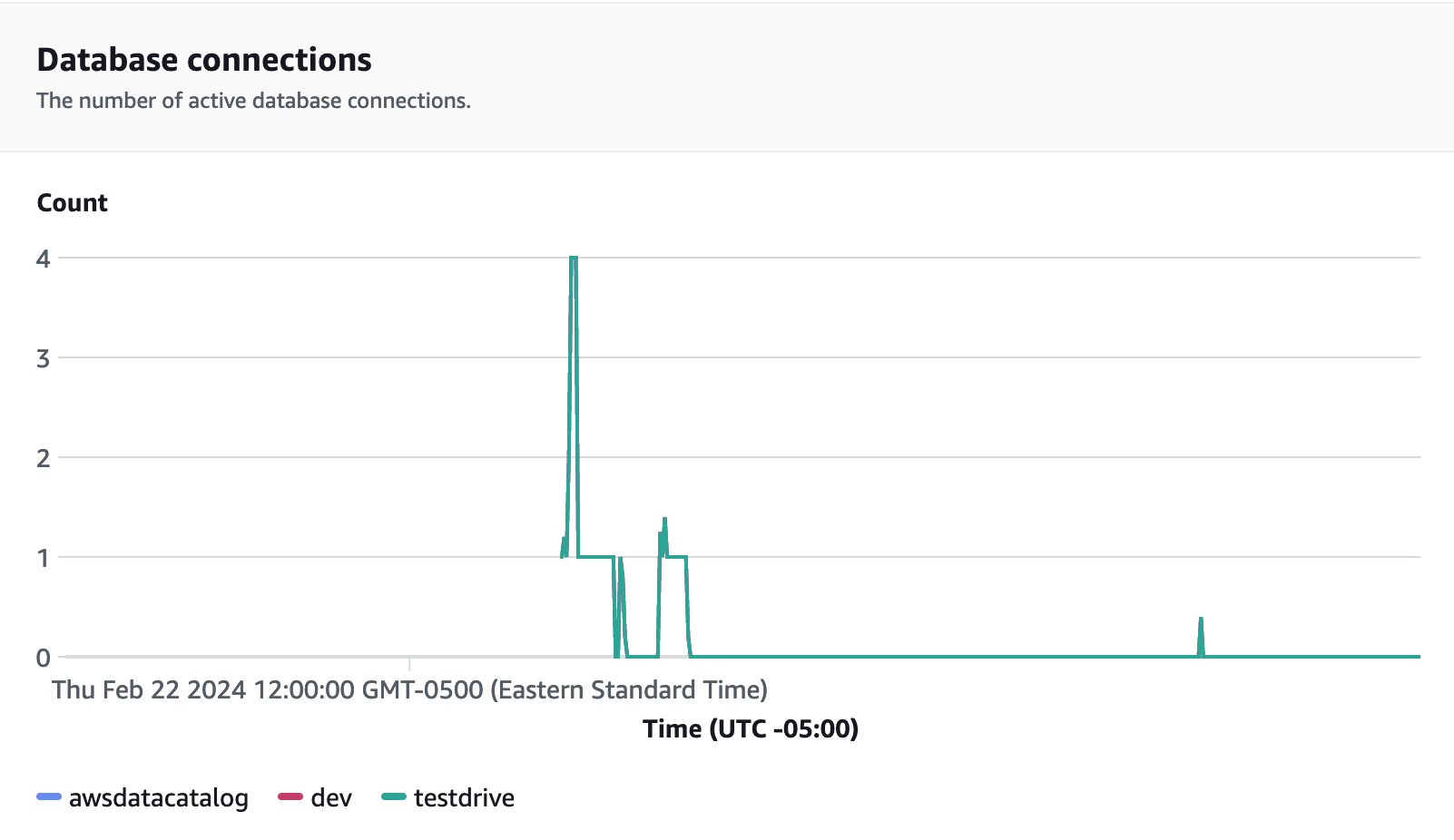
As conexões de banco de dados são outra métrica útil a ser monitorada durante a execução do teste de carga para ver como o grupo de trabalho está lidando com várias conexões simultâneas em determinado momento e atender às crescentes demandas da workload.
Etapa 5: Otimizar

O Amazon Redshift possibilita que dezenas de milhares de usuários processem exabytes de dados todos os dias e potencializem suas workloads de análise. Para isso, ele oferece uma variedade de configurações e recursos para atender a casos de uso individuais. Ao escolher entre essas opções, os clientes procuram ferramentas que os ajudem a determinar a configuração ideal de data warehouse para atender à workload do Amazon Redshift.
Test Drive
Você pode usar o Test Drive
