O Amazon Redshift deixará de oferecer suporte ao uso de UDFs em Python após 30 de junho de 2026. Começaremos a aplicar essa alteração em fases. Consulte mais informações sobre os detalhes do fim da vida útil do Python e as opções de migração na publicação do blog
Conceitos básicos de data warehouse do Amazon Redshift sem servidor
Se estiver usando o Amazon Redshift Serverless pela primeira vez, recomendamos que leia as seguintes seções que ajudarão a começar a usar o Amazon Redshift Serverless. O fluxo básico do Amazon Redshift sem servidor é criar recursos de tecnologia sem servidor, conectar-se ao Amazon Redshift sem servidor, carregar dados de amostra e executar consultas aos dados. Neste guia, você pode escolher carregar dados de amostra do Amazon Redshift sem servidor ou de um bucket do Amazon S3. Os dados de amostra são usados em toda a documentação do Amazon Redshift para demonstrar os recursos. Para começar a usar data warehouses provisionados do Amazon Redshift, consulte Conceitos básicos de data warehouses provisionados do Amazon Redshift.
Inscrever-se para uma Conta da AWS
Para começar a usar a AWS, você precisa de uma Conta da AWS. Para ter informações sobre a criação de uma Conta da AWS, consulte Comece a usar uma Conta da AWS no Guia de referência do AWS Gerenciamento de contas.
Criar um data warehouse com o Amazon Redshift sem servidor
Na primeira vez que fizer login no console do Amazon Redshift sem servidor, você será solicitado a acessar a experiência de conceitos básicos, que pode ser usada para criar e gerenciar recursos de tecnologia sem servidor. Neste guia, você criará recursos de tecnologia sem servidor usando as configurações padrão do Amazon Redshift sem servidor.
Para ter um controle mais detalhado da configuração, selecione Customize settings (Personalizar configurações).
nota
O Redshift sem servidor exige uma Amazon VPC com três sub-redes em três zonas de disponibilidade diferentes. O Redshift sem servidor também exige pelo menos três endereços IP disponíveis. Antes de continuar, garanta que a Amazon VPC utilizada para o Redshift sem servidor tenha três sub-redes em três zonas de disponibilidade diferentes e pelo menos três endereços IP disponíveis antes de continuar. Para ter mais informações sobre como criar sub-redes em uma Amazon VPC, consulte Criar uma sub-rede no Manual do usuário da Amazon Virtual Private Cloud. Para ter mais informações sobre endereços IP em uma Amazon VPC, consulte Endereçamento IP para suas VPCs e sub-redes.
Como utilizar as configurações padrão:
Faça login no AWS Management Console e abra o console do Amazon Redshift em https://console.aws.amazon.com/redshiftv2/
. Selecione Experimente o Amazon Redshift sem servidor.
-
Em Configuration (Configuração), selecione Use default settings (Usar configurações padrão). O Amazon Redshift sem servidor cria um namespace padrão com um grupo de trabalho padrão associado a esse namespace. Escolha Save configuration.
nota
Namespace é um conjunto de objetos e usuários do banco de dados. Os namespaces agrupam todos os recursos que você usa no Redshift sem servidor, como esquemas, tabelas, usuários, unidades de compartilhamento de dados e snapshots.
Grupo de trabalho é um conjunto de recursos computacionais. Os grupos de trabalho abrigam os recursos computacionais que o Redshift sem servidor usa para executar tarefas computacionais.
A captura de tela a seguir mostra as configurações padrão para o Amazon Redshift sem servidor.
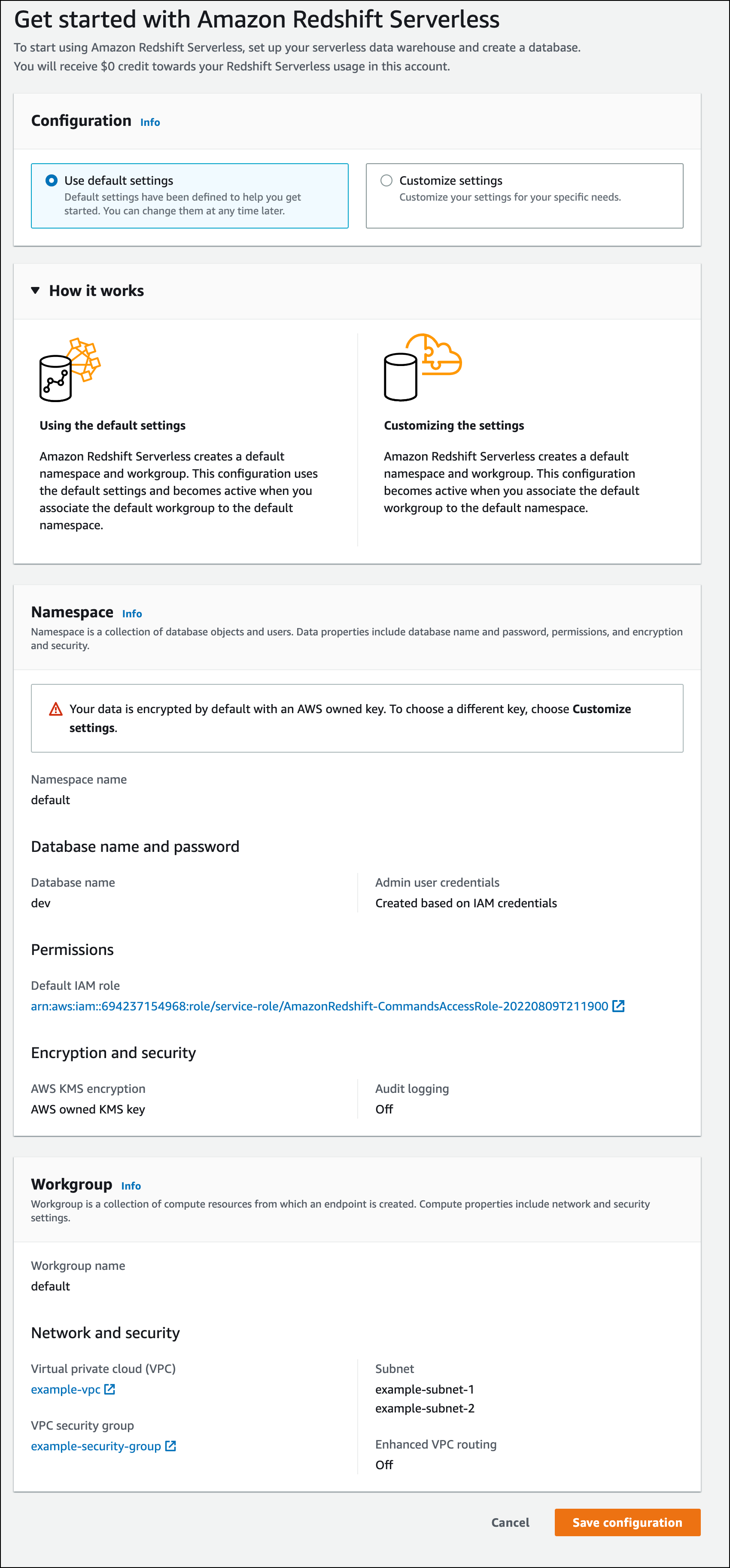
-
Após a conclusão da configuração, escolha Continue (Continuar) para acessar o Serverless dashboard (Painel do Serverless). Você pode ver que o grupo de trabalho e o namespace de tecnologia sem servidor estão disponíveis.
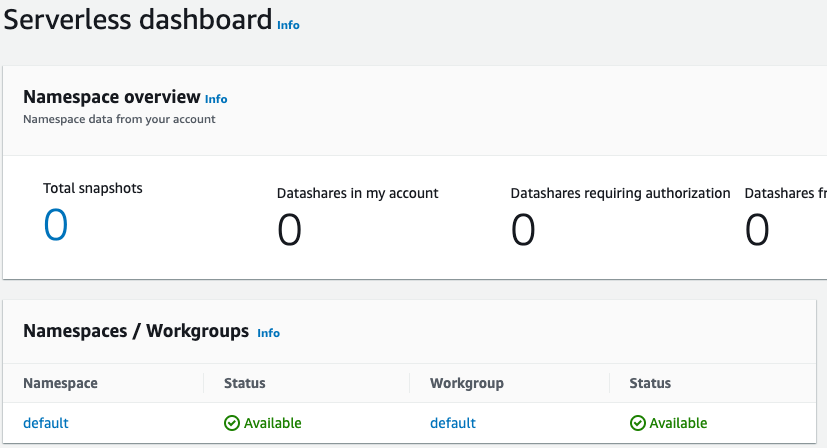
nota
Se o Redshift sem servidor não criar o grupo de trabalho com êxito, você poderá fazer o seguinte:
Solucione todos os erros relatados pelo Redshift sem servidor, como ter poucas sub-redes na Amazon VPC.
Exclua o namespace selecionando default-namespace no painel do Redshift sem servidor e, depois, escolhendo Ações, Excluir namespace. A exclusão de um namespace leva alguns minutos.
Quando você abre o console do Redshift sem servidor novamente, a tela de boas-vindas é exibida.
Carregar dados de exemplo
Agora que você configurou seu data warehouse com o Amazon Redshift sem servidor, pode usar o editor de consultas v2 do Amazon Redshift para carregar dados de amostra.
-
Para iniciar o editor de consultas v2 pelo console do Amazon Redshift sem servidor, escolha Consultar dados. Quando você invoca o editor de consultas v2 no console do Amazon Redshift, abre-se uma nova guia no navegador com o editor de consultas. O editor de consultas v2 se conecta da máquina cliente ao ambiente do Amazon Redshift Serverless.
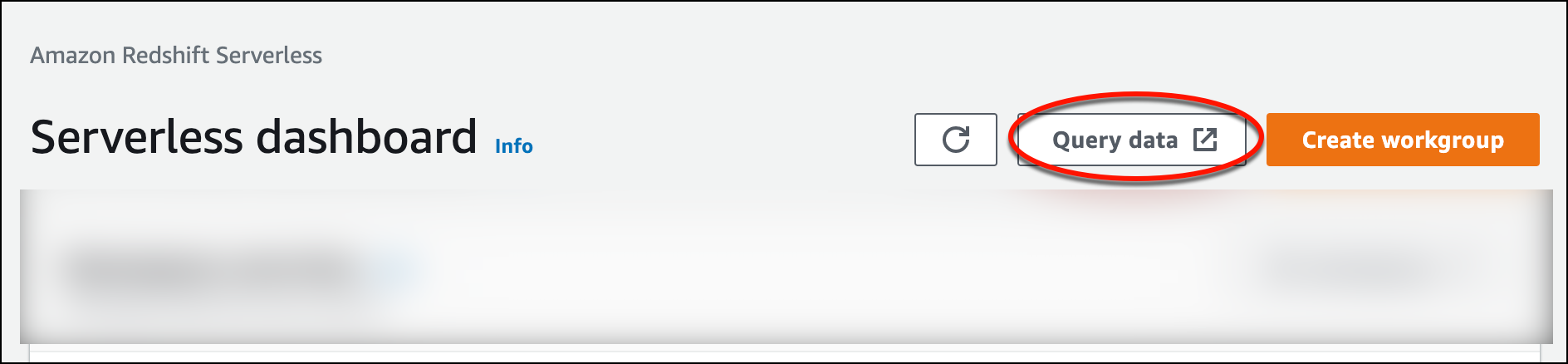
-
Para este guia, você usará sua conta de administrador da AWS e a conta padrão AWS KMS key. Para ter informações sobre como configurar o Editor de Consultas v2, inclusive quais permissões são necessárias, consulte Configurar sua Conta da AWS no Guia de gerenciamento do Amazon Redshift. Para ter informações sobre como configurar o Amazon Redshift para usar uma chave gerenciada pelo cliente ou para alterar a chave do KMS usada pelo Amazon Redshift, consulte Alterar a chave do AWS KMS para um namespace.
-
Para se conectar a um grupo de trabalho, escolha o nome do grupo de trabalho no painel de exibição em árvore.
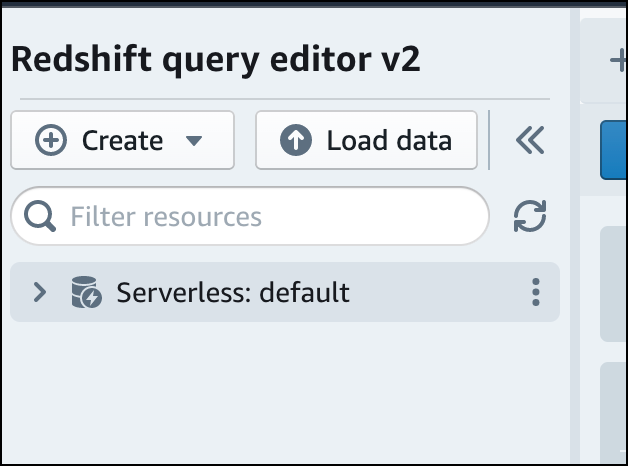
-
Ao se conectar a um novo grupo de trabalho pela primeira vez no editor de consultas v2, selecione o tipo de autenticação que deseja usar para se conectar ao grupo de trabalho. Para este guia, mantenha a seleção de Usuário federado e escolha Criar conexão.
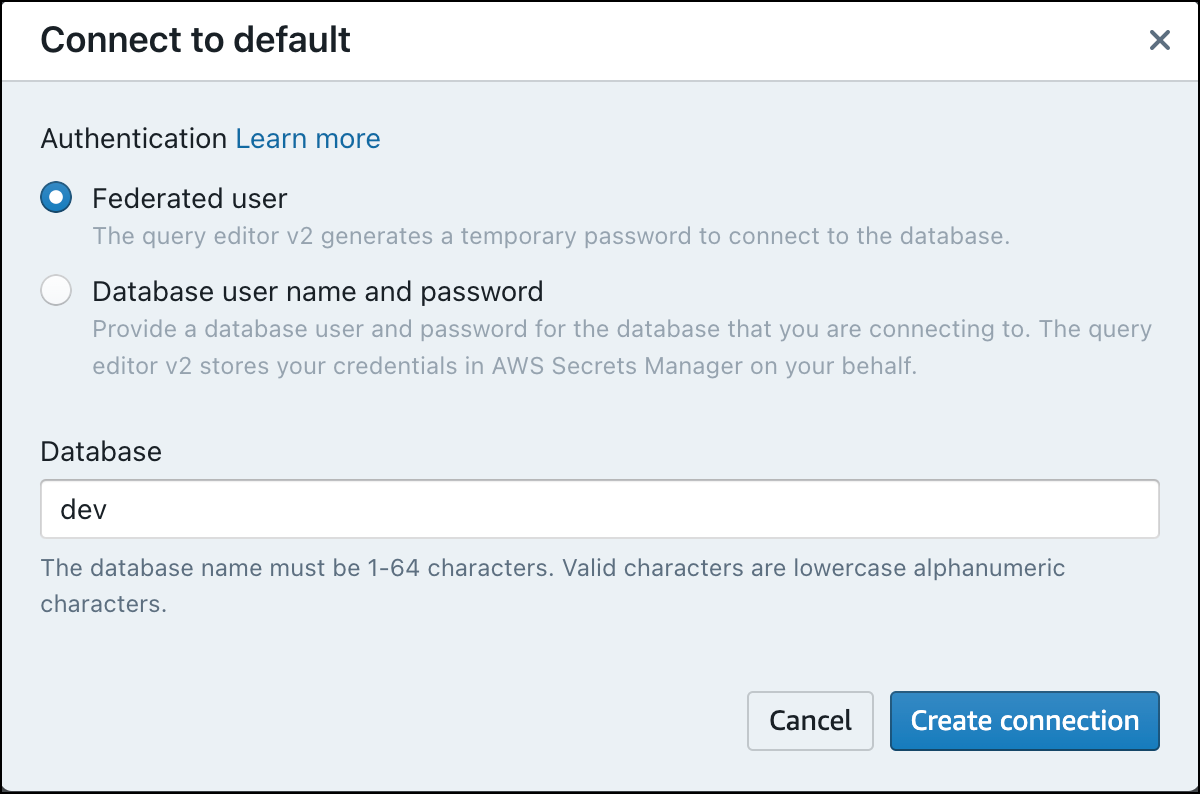
Depois de se conectar, você poderá optar por carregar dados de amostra do Amazon Redshift sem servidor ou de um bucket do Amazon S3.
-
No grupo de trabalho padrão do Amazon Redshift Serverless, expanda o banco de dados sample_data_dev. Há três esquemas de amostra correspondentes a três conjuntos de dados de amostra que você pode carregar no banco de dados do Amazon Redshift sem servidor. Escolha o conjunto de dados de amostra que você deseja carregar e selecione Abrir caderno de exemplo.
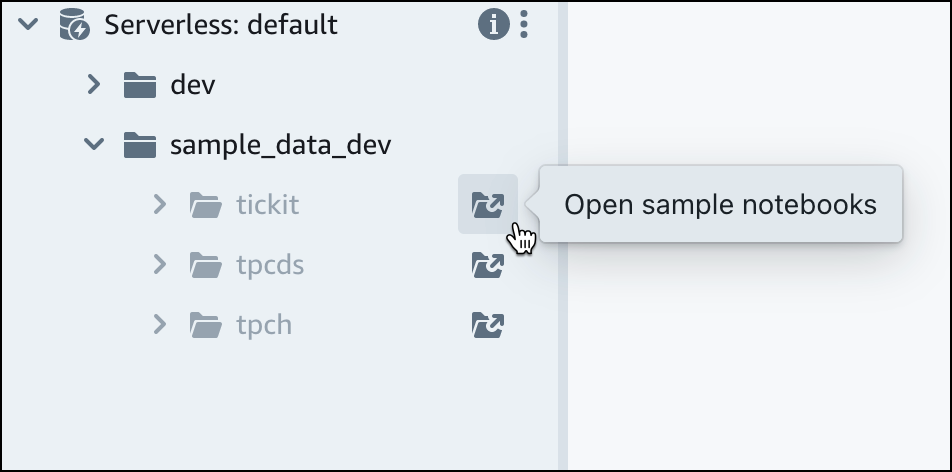
nota
Caderno SQL é um contêiner das células SQL e Markdown. É possível usar cadernos para organizar, anotar e compartilhar vários comandos SQL em um único documento.
-
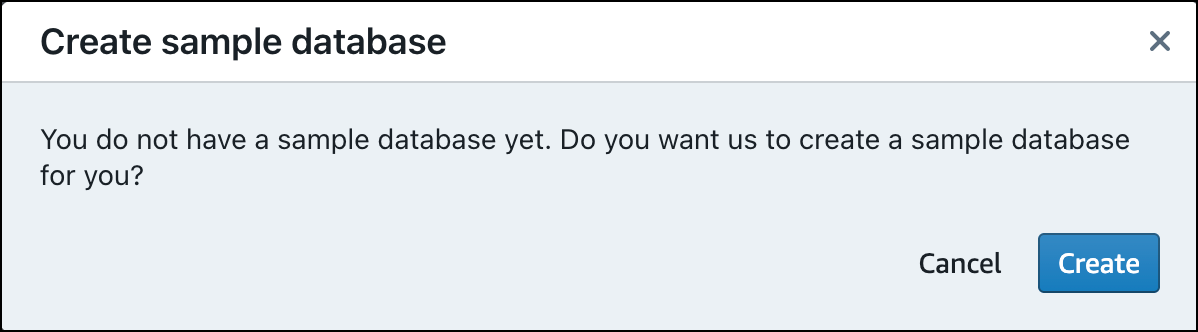
Ao carregar dados pela primeira vez, o editor de consultas v2 solicitará que você crie um banco de dados de amostra. Escolha Criar.
Executar consultas de amostra
Depois de configurar o Amazon Redshift sem servidor, você pode começar a usar um conjunto de dados de amostra no Amazon Redshift sem servidor. O Amazon Redshift sem servidor carrega automaticamente o conjunto de dados de amostra, como o conjunto de dados “tickit”, e você pode consultar os dados imediatamente.
-
Quando o Amazon Redshift sem servidor terminar de carregar os dados de amostra, todas as consultas de amostra serão carregadas no editor. Você pode escolher Executar tudo para executar todas as consultas dos cadernos de amostra.
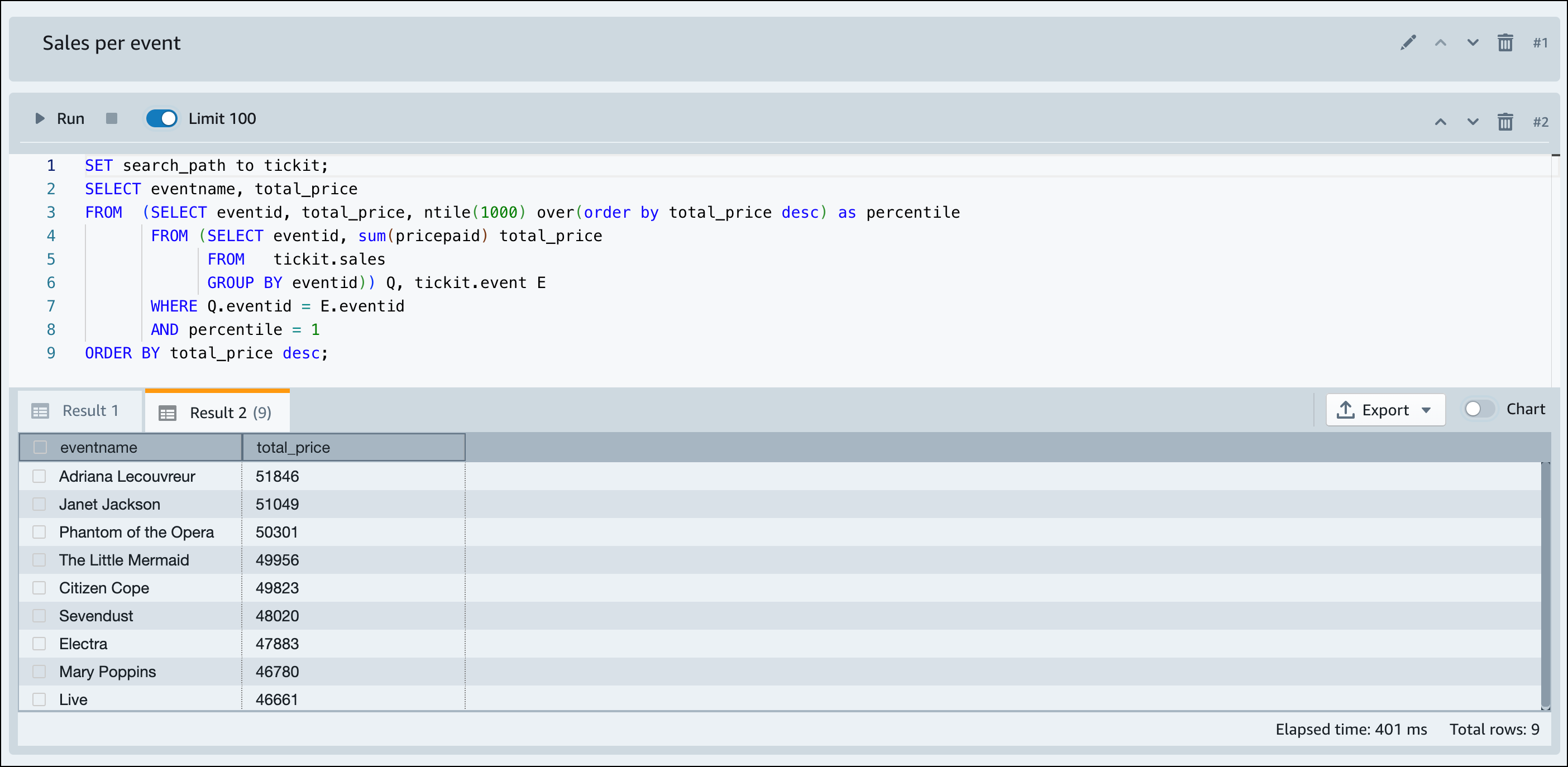
Você também pode exportar os resultados como um arquivo JSON ou CSV, ou exibir os resultados em um gráfico.

Você também pode carregar dados de um bucket do Amazon S3. Para saber mais, consulte Carregar dados do Amazon S3.
Carregar dados do Amazon S3
Depois de criar seu data warehouse, você poderá carregar dados do Amazon S3.
Neste ponto, você tem um banco de dados chamado dev. Em seguida, crie algumas tabelas no banco de dados, faça upload de dados nelas e tente fazer uma consulta. Para sua conveniência, os dados de amostra que você carrega estão disponíveis em um bucket do Amazon S3.
-
Para carregar dados do Amazon S3, primeiro você deve criar um perfil do IAM com as permissões necessárias e anexá-lo ao seu namespace de tecnologia sem servidor. Para fazer isso, retorne ao console do Redshift sem servidor e escolha Configuração do namespace. No menu de navegação, escolha seu namespace e selecione Segurança e criptografia. Escolha Gerenciar funções do IAM.
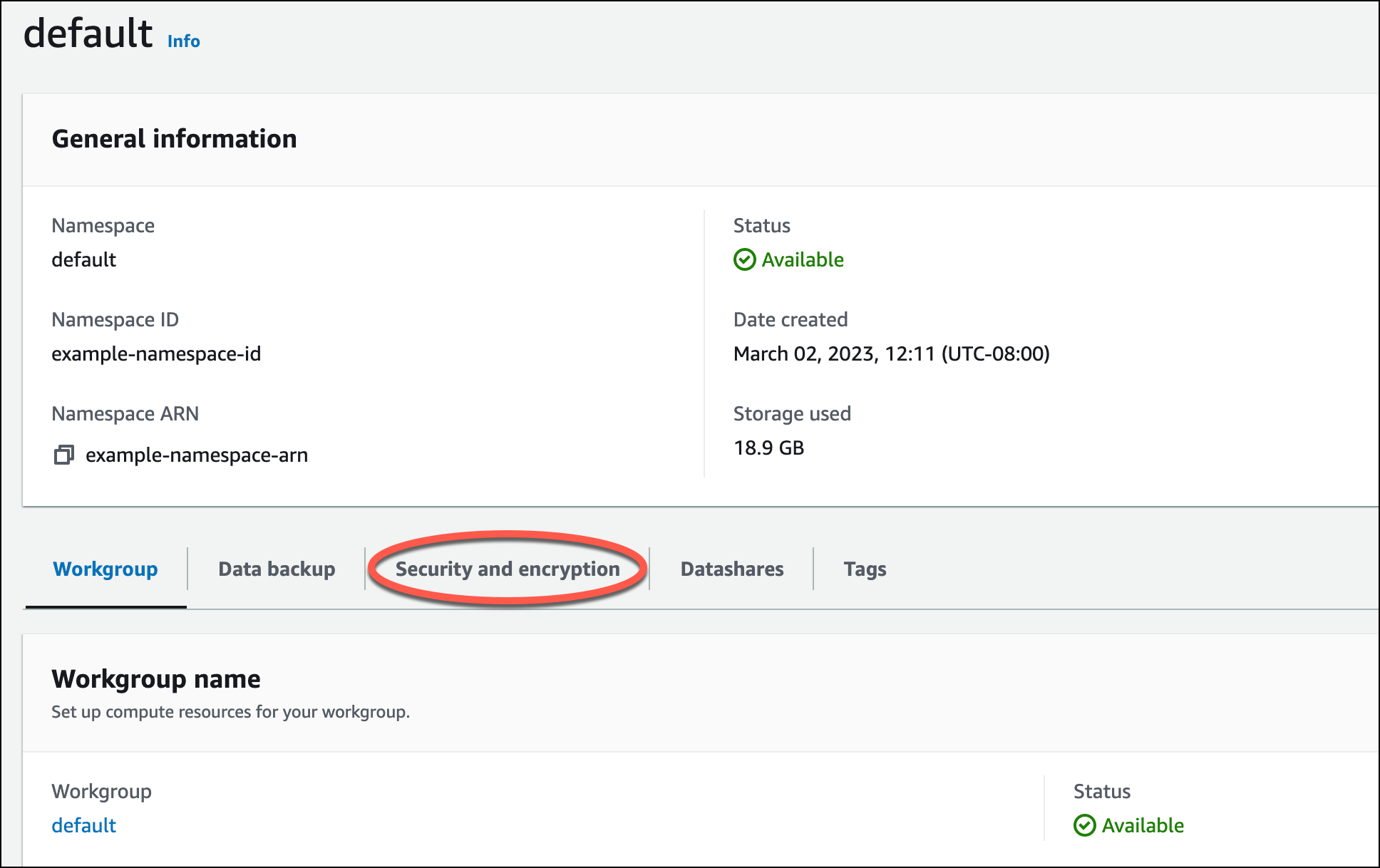
Expanda o menu Gerenciar perfis do IAM e escolha Criar perfil do IAM.
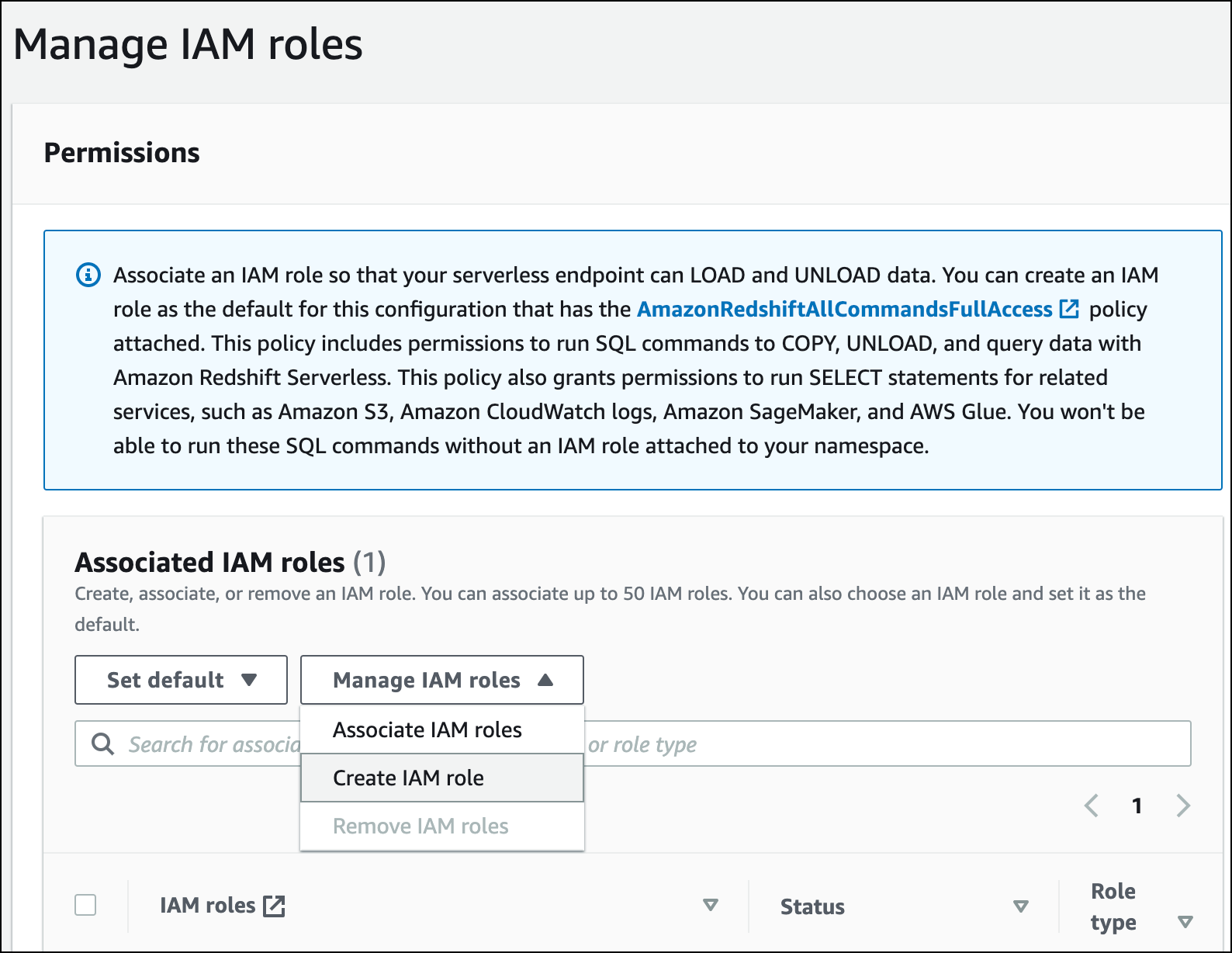
Escolha o nível de acesso ao bucket do S3 que você deseja conceder a esse perfil e selecione Criar perfil do IAM como padrão.

-
Escolha Salvar alterações. Agora é possível carregar dados de amostra do Amazon S3.
As etapas a seguir usam dados em um bucket público do S3 no Amazon Redshift, mas você pode replicar as mesmas etapas usando seu próprio bucket do S3 e comandos SQL.
Carregar dados de amostra do Amazon S3
-
No editor de consultas v2, escolha
 Adicionar e selecione Caderno para criar um caderno SQL.
Adicionar e selecione Caderno para criar um caderno SQL.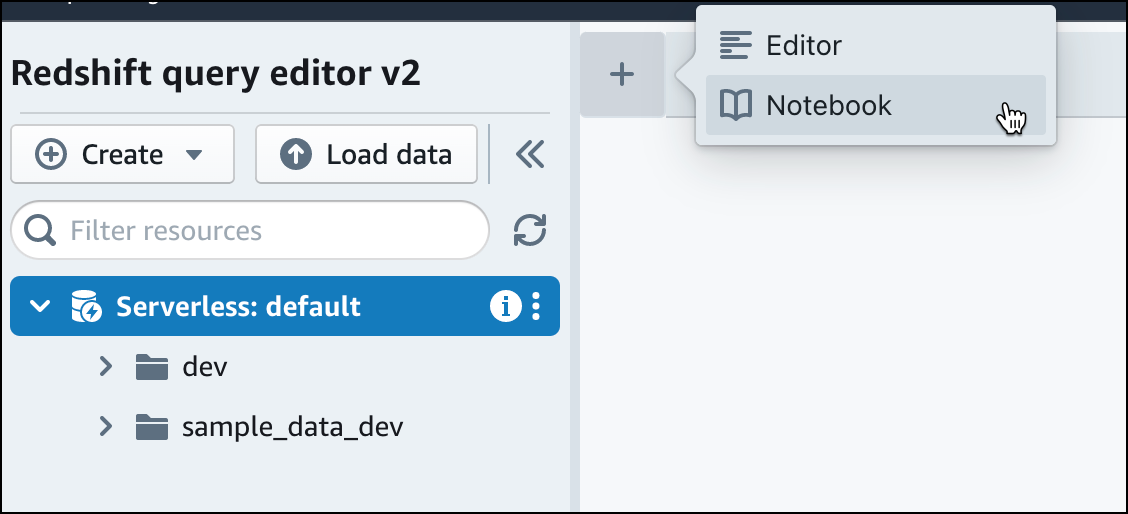
-
Mude para o banco de dados
dev.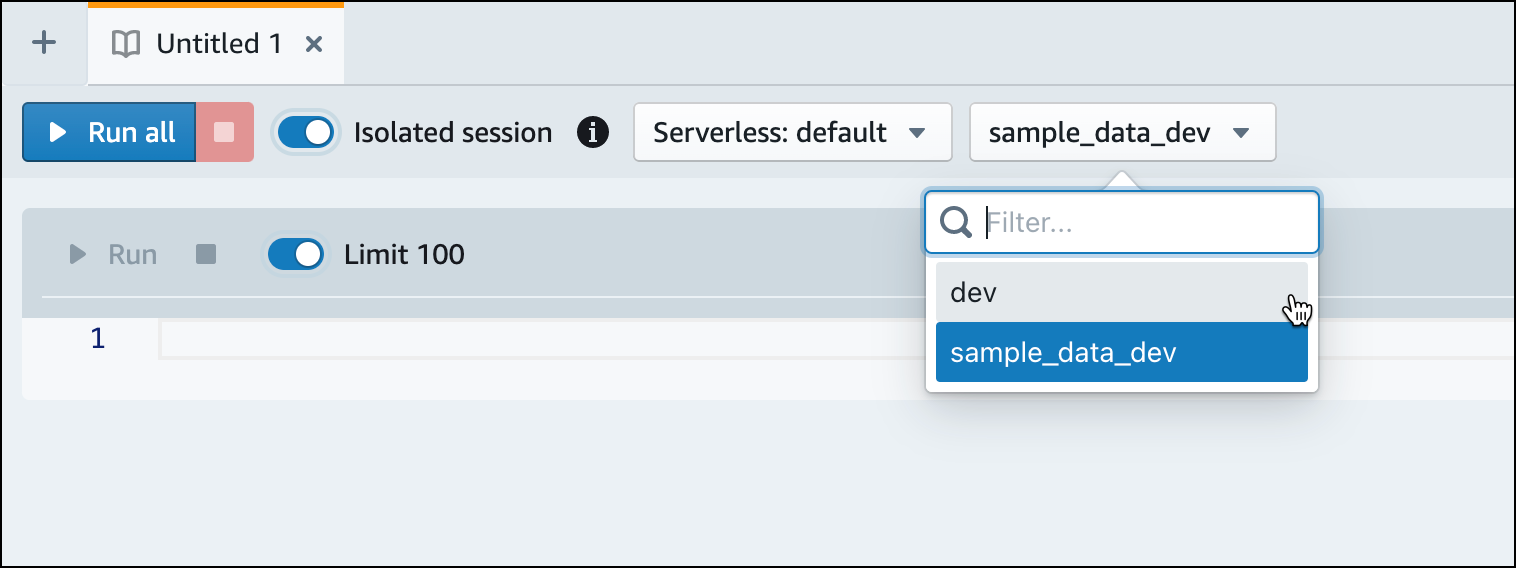
-
Crie tabelas.
Se você estiver usando o editor de consultas v2, copie e execute as instruções de criação de tabelas a seguir para criar tabelas no banco de dados
dev. Para obter mais informações sobre a sintaxe, consulte CREATE TABLE no Guia do desenvolvedor de banco de dados do Amazon Redshift.create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp); -
No editor de consultas v2, crie uma célula SQL em seu caderno.
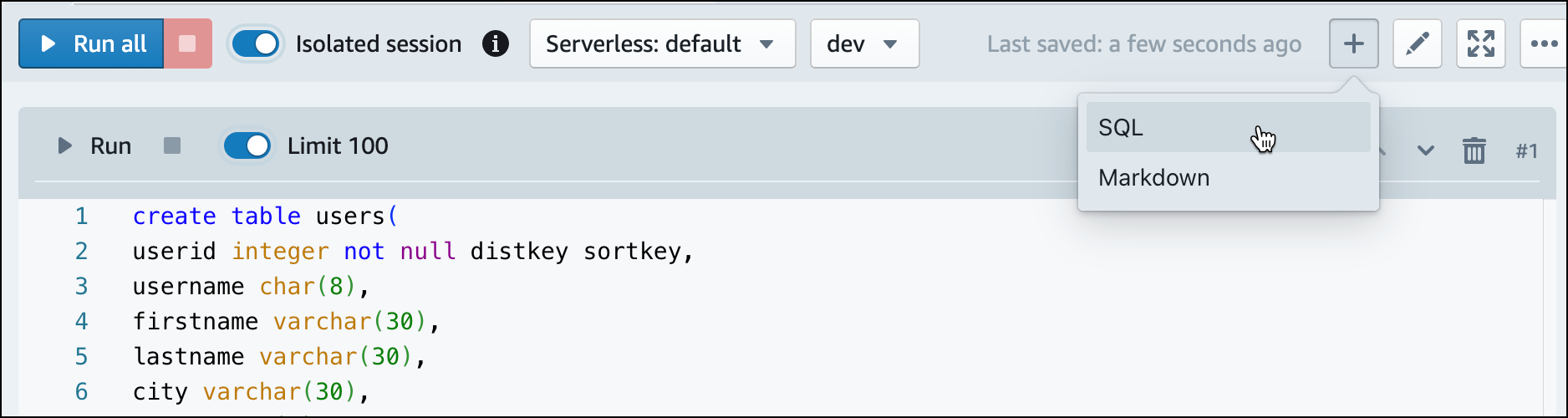
-
Agora use o comando COPY no editor de consultas v2 para carregar grandes conjuntos de dados do Amazon S3 ou Amazon DynamoDB no Amazon Redshift. Para obter mais informações sobre sintaxe de COPY, consulte COPY no Guia do desenvolvedor de banco de dados do Amazon Redshift.
Você pode executar o comando COPY com alguns dados de amostra disponíveis em um bucket público do S3. Execute os comandos a seguir no editor de consultas v2.
COPY users FROM 's3://redshift-downloads/tickit/allusers_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY event FROM 's3://redshift-downloads/tickit/allevents_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY sales FROM 's3://redshift-downloads/tickit/sales_tab.txt' DELIMITER '\t' TIMEFORMAT 'MM/DD/YYYY HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; -
Depois de carregar os dados, crie outra célula SQL em seu caderno e tente realizar algumas consultas. Para obter mais informações sobre como trabalhar com o comando SELECT, consulte SELECT no Guia do desenvolvedor do Amazon Redshift. Para entender a estrutura e os esquemas dos dados de amostra, explore o uso do editor de consultas v2.
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; -- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc;
Agora que você carregou dados e executou algumas consultas de amostra, já pode explorar outras áreas do Amazon Redshift sem servidor. Confira a lista a seguir para saber mais sobre como você pode usar o Amazon Redshift sem servidor.
-
Você pode carregar dados de um bucket do Amazon S3. Para obter mais informações, consulte Carregar dados do Amazon S3.
-
É possível usar o editor de consultas v2 para carregar dados de um arquivo local separado por caracteres de até 5 MB. Para obter mais informações, consulte Carregar dados de um arquivo local.
-
Você pode se conectar ao Amazon Redshift sem servidor com ferramentas SQL de terceiros com o driver JDBC e ODBC. Para obter mais informações, consulte Conectar-se ao Amazon Redshift sem servidor.
-
Também é possível usar a API de dados do Amazon Redshift para se conectar ao Amazon Redshift Serverless. Para obter mais informações, consulte Usar a API de dados do Amazon Redshift
. -
Você pode usar seus dados no Amazon Redshift sem servidor com o Redshift ML para criar modelos de machine learning com o comando CREATE MODEL. Consulte Tutorial: Como criar modelos de rotatividade de clientes para aprender a criar um modelo de ML do Redshift.
-
Você pode consultar dados de um data lake do Amazon S3 sem carregar nenhum dado no Amazon Redshift sem servidor. Para obter mais informações, consulte Consultar um data lake.
