As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Conceitos básicos do Data Wrangler
O Amazon SageMaker Data Wrangler é um recurso do Amazon SageMaker Studio Classic. Use esta seção para saber como acessar e começar a usar o Data Wrangler. Faça o seguinte:
-
Conclua cada etapa em Pré-requisitos.
-
Siga o procedimento em Acesse o Data Wrangler para começar a usar o Data Wrangler.
Pré-requisitos
Para usar o Data Wrangler, é necessário concluir os pré-requisitos a seguir.
-
Para usar o Data Wrangler, é necessário acessar uma instância do Amazon Elastic Compute Cloud (Amazon EC2). Para obter mais informações sobre as instâncias do Amazon EC2 que você pode usar, consulte Instâncias. Para saber como visualizar suas cotas e, se necessário, solicitar um aumento de cota, consulte Service Quotas da AWS.
-
Configure as permissões obrigatórias descritas em Segurança e permissões.
-
Se sua organização estiver usando um firewall que bloqueia o tráfego de Internet, você deverá ter acesso aos seguintes URLs:
-
https://ui.prod-1.data-wrangler.sagemaker.aws/ -
https://ui.prod-2.data-wrangler.sagemaker.aws/ -
https://ui.prod-3.data-wrangler.sagemaker.aws/ -
https://ui.prod-4.data-wrangler.sagemaker.aws/
-
Para usar o Data Wrangler, você precisa de uma instância ativa do Studio Classic. Para saber como iniciar uma nova instância, consulte Visão geral do domínio Amazon SageMaker AI. Quando sua instância do Studio Classic estiver com o status Pronto, use as instruções em Acesse o Data Wrangler.
Acesse o Data Wrangler
O procedimento a seguir pressupõe que você já concluiu os Pré-requisitos.
Para acessar o Data Wrangler no Studio Classic, faça o seguinte:
-
Faça login no Studio Classic. Para obter mais informações, consulte Visão geral do domínio Amazon SageMaker AI.
-
Escolha Studio.
-
Escolha Iniciar aplicação.
-
Na lista suspensa, selecione Studio.
-
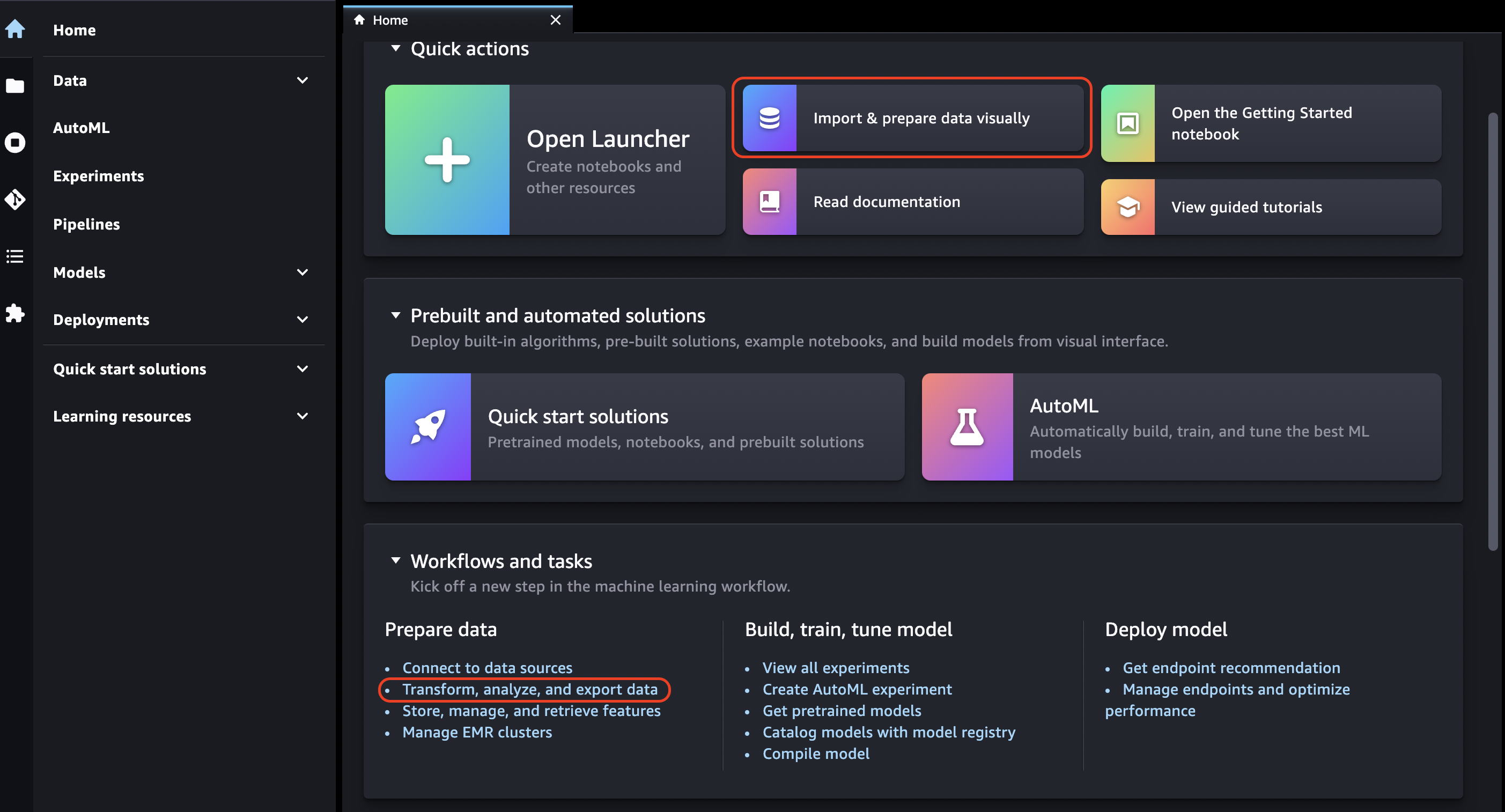
Escolha o ícone Início.
-
Escolha Dados.
-
Escolha Data Wrangler.
-
Você também pode criar um fluxo do Data Wrangler fazendo o seguinte:
-
Na barra de navegação superior, selecione Arquivo.
-
Selecione Novo.
-
Selecione Fluxo do Data Wrangler.
-
-
(Opcional) Renomeie o novo diretório e o arquivo .flow.
-
Ao criar um novo arquivo .flow no Studio Classic, você pode ver um carrossel que apresenta o Data Wrangler.
Isso pode levar alguns minutos.
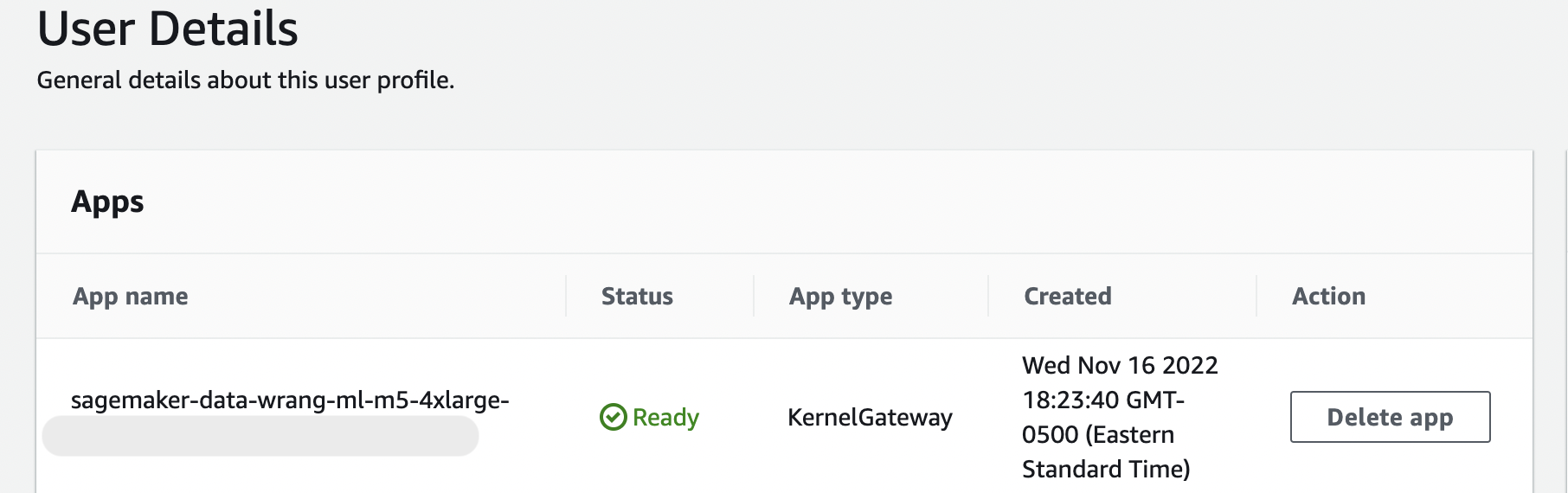
Essa mensagem persiste enquanto o KernelGatewayaplicativo na sua página de detalhes do usuário estiver pendente. Para ver o status desse aplicativo, no console de SageMaker IA na página do Amazon SageMaker Studio Classic, selecione o nome do usuário que você está usando para acessar o Studio Classic. Na página Detalhes do usuário, você vê um KernelGatewayaplicativo em Aplicativos. Espere até que o status da aplicação esteja Pronto para começar a usar o Data Wrangler. Isso pode levar cerca de 5 minutos na primeira vez que você iniciar o Data Wrangler.
-
Para começar, escolha uma fonte de dados e use-a para importar um conjunto de dados. Para saber mais, consulte Importar.
Quando você importa um conjunto de dados, ele aparece no seu fluxo de dados. Para saber mais, consulte Crie e use um fluxo do Data Wrangler.
-
Após a importação de um conjunto de dados, o Data Wrangler infere automaticamente o tipo de dados em cada coluna. Escolha + ao lado da etapa Tipos de dados e selecione Editar tipos de dados.
Importante
Após adicionar transformações na etapa Tipos de dados, você não poderá atualizar em massa os tipos de coluna usando Tipos de atualização.
-
Use o fluxo de dados para adicionar transformações e análises. Para saber mais, consulte Transformar dados e Analisar e visualizar.
-
Para exportar um fluxo de dados completo, escolha Exportar e escolha uma opção de exportação. Para saber mais, consulte Exportar.
-
Por fim, escolha o ícone Componentes e registros e selecione Data Wrangler na lista suspensa para ver todos os arquivos .flow criados por você. Você pode usar esse menu para localizar e se mover entre fluxos de dados.
Depois de iniciar o Data Wrangler, você pode usar a seção a seguir para ver um passo a passo de como você pode usar o Data Wrangler para criar um fluxo de preparação de dados com ML.
Atualizar o Data Wrangler
Recomendamos que você atualize periodicamente a aplicação Data Wrangler do Studio Classic para acessar os atributos e atualizações mais recentes. O nome da aplicação do Data Wrangler começa com sagemaker-data-wrang. Para saber como atualizar uma aplicação do Studio Classic, consulte Encerre e atualize os aplicativos do Amazon SageMaker Studio Classic.
Demonstração: Passo a passo do conjunto de dados Data Wrangler Titanic
As seções a seguir fornecem uma explicação passo a passo para ajudar você a começar a usar o Data Wrangler. Esse passo a passo pressupõe que você já tenha seguido as etapas em Acesse o Data Wrangler e tenha aberto um novo arquivo de fluxo de dados que você pretende usar para a demonstração. Talvez você queira renomear esse arquivo .flow para algo semelhante como titanic-demo.flow.
Este passo a passo usa o conjunto de dados do Titanic
Neste tutorial, você realizará as seguintes etapas:
-
Execute um destes procedimentos:
-
Abra seu fluxo do Data Wrangler e escolha Usar conjunto de dados de amostra.
-
Faça upload do conjunto de dados do Titanic
no Amazon Simple Storage Service (Amazon S3) e, em seguida, importe esse conjunto de dados para o Data Wrangler.
-
-
Analise o conjunto de dados usando as análises do Data Wrangler.
-
Defina um fluxo de dados usando as transformações de dados do Data Wrangler.
-
Exporte seu fluxo para um caderno Jupyter que pode ser usado para criar um trabalho do Data Wrangler.
-
Processe seus dados e inicie um trabalho de SageMaker treinamento para treinar um classificador binário XGBoost.
Faça upload do conjunto de dados no S3 e importe
Para começar, é possível usar um dos seguintes métodos para importar o conjunto de dados do Titanic para o Data Wrangler:
-
Importando o conjunto de dados diretamente do fluxo do Data Wrangler
-
Fazendo upload do conjunto de dados no Amazon S3 e depois importando para o Data Wrangler
Para importar o conjunto de dados diretamente para o Data Wrangler, abra o fluxo e escolha Usar conjunto de dados de amostra.
O upload do conjunto de dados no Amazon S3 e a importação para o Data Wrangler é mais próximo da experiência que você tem ao importar seus próprios dados. As informações a seguir explicam como fazer o upload do seu conjunto de dados e importá-lo.
Antes de começar a importar os dados para o Data Wrangler, baixe o conjunto de dados do Titanic
Se você for um novo usuário do Amazon S3, poderá fazer isso usando o recurso de arrastar e soltar no console do Amazon S3. Para saber como, consulte Upload de arquivos e pastas usando arrastar e soltar na Guia do usuário do Amazon Simple Storage Service.
Importante
Faça upload do seu conjunto de dados em um bucket do S3 na mesma AWS região que você deseja usar para concluir esta demonstração.
Quando seu conjunto de dados tiver sido carregado com êxito no Amazon S3, você poderá importá-lo para o Data Wrangler.
Importe o conjunto de dados do Titanic para o Data Wrangler
-
Escolha o botão Importar dados na guia Fluxo de dados ou escolha a guia Importar.
-
Selecione Amazon S3.
-
Use a tabela Importar um conjunto de dados do S3 para encontrar o bucket onde você adicionou o conjunto de dados do Titanic. Escolha o arquivo CSV do conjunto de dados do Titanic para abrir o painel Detalhes.
-
Em Detalhes, o tipo de arquivo deve ser CSV. Marque Primeira linha é cabeçalho para especificar que a primeira linha do conjunto de dados é um cabeçalho. Você também pode nomear o conjunto de dados de forma mais conveniente, como
Titanic-train. -
Escolha o botão Importar .
Quando seu conjunto de dados é importado para o Data Wrangler, ele aparece na guia Fluxo de dados. Você pode clicar duas vezes em um nó para entrar na visualização de detalhes do nó, o que permite adicionar transformações ou análises. Você pode usar o ícone de adição para acesso rápido à navegação. Na próxima seção, você usará esse fluxo de dados para adicionar etapas de análise e transformação.
Fluxo de dados
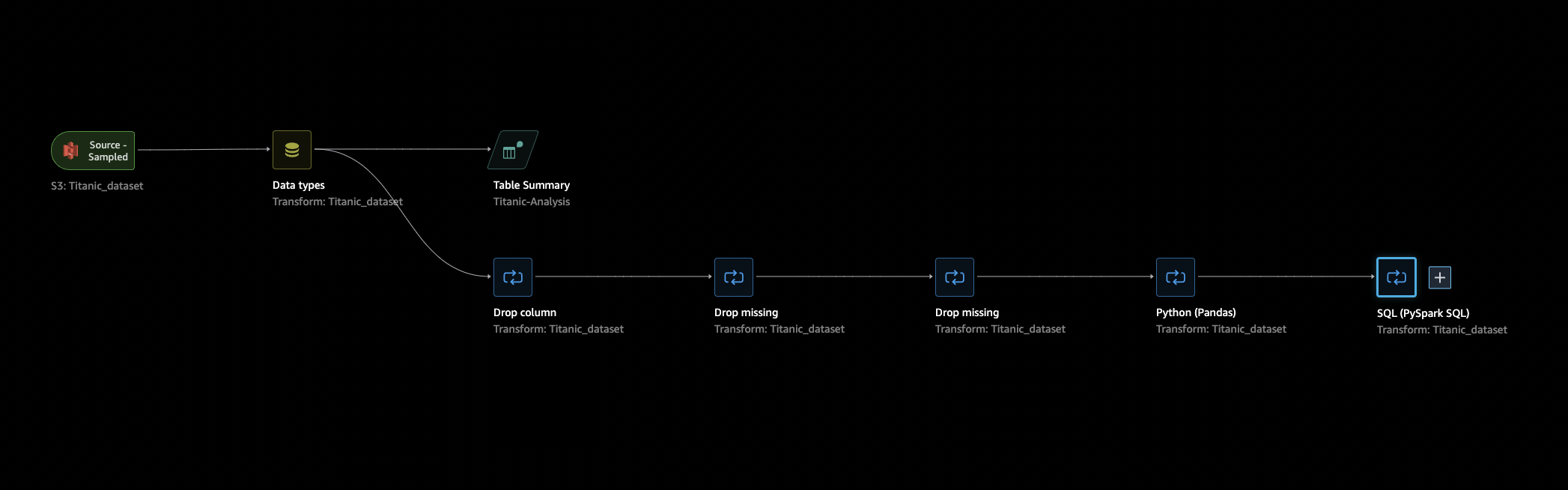
Na seção de fluxo de dados, as únicas etapas do fluxo de dados são seu conjunto de dados importado recentemente e uma etapa de tipo de dados. Depois de aplicar as transformações, você pode voltar a essa guia e ver como é o fluxo de dados. Agora, adicione algumas transformações básicas nas guias Preparar e Analisar.
Preparo e visualização
O Data Wrangler tem transformações e visualizações integradas que você pode usar para analisar, limpar e transformar seus dados.
A guia Dados da visualização de detalhes do nó lista todas as transformações integradas no painel direito, que também contém uma área onde você pode adicionar transformações personalizadas. O caso de uso a seguir mostra como usar essas transformações.
Para obter informações que possam ajudar você na exploração de dados e na engenharia de atributos, crie um relatório de qualidade dos dados e insights. As informações do relatório podem ajudar você a limpar e processar seus dados. Ele fornece informações como o número de valores ausentes e o número de valores atípicos. Caso tenha problemas com seus dados, como vazamento ou desequilíbrio de destino, o relatório de insights pode chamar sua atenção para esses problemas. Para obter mais informações sobre como criar um relatório, consulte Obtenha insights sobre dados e qualidade dos dados.
Exploração de dados
Primeiro, crie um resumo da tabela dos dados usando uma análise. Faça o seguinte:
-
Escolha o + ao lado da etapa Tipo de dados em seu fluxo de dados e selecione Adicionar análise.
-
Na área Análise, selecione Resumo da tabela na lista suspensa.
-
Dê um nome ao resumo da tabela.
-
Selecione Visualizar para visualizar a tabela que será criada.
-
Escolha Salvar para salvar em seu fluxo de dados. Ela aparecerá em Todas as análises.
Usando as estatísticas que você vê, você pode fazer observações semelhantes às seguintes sobre esse conjunto de dados:
-
A média da tarifa (média) é de cerca de US$ 33, enquanto a máxima é superior a US$ 500. Essa coluna provavelmente tem valores atípicos.
-
Este conjunto de dados usa ? para indicar valores ausentes. Várias colunas têm valores ausentes: cabine, embarcou e destino.inicial
-
A categoria de idade não tem mais de 250 valores.
Em seguida, limpe seus dados usando os insights obtidos com essas estatísticas.
Descarte de colunas não utilizadas
Usando a análise da seção anterior, limpe o conjunto de dados para prepará-lo para o treinamento. Para adicionar uma nova transformação ao seu fluxo de dados, escolha + ao lado da etapa Tipo de dados em seu fluxo de dados e escolha Adicionar transformação.
Primeiro, descarte as colunas que você não deseja utilizar para treinamento. Você pode usar a biblioteca de análise de dados do pandas
Use o procedimento a seguir para descartar as colunas não utilizadas.
Para descartar as colunas não utilizadas.
-
Abra o fluxo do Data Wrangler.
-
Há dois nós no fluxo do Data Wrangler. Escolha o + à direita do nó Tipos de dados.
-
Escolha Adicionar transformação.
-
Na coluna Todas as etapas, escolha Adicionar etapa.
-
Na lista Transformação padrão, escolha Gerenciar colunas. As transformações padrão são transformações prontas e integradas. Lembre-se de verificar se a opção Eliminar coluna está selecionada.
-
Em Colunas a serem eliminadas, verifique os seguintes nomes de colunas:
-
cabine
-
bilhete
-
name
-
sibsp
-
parch
-
destino.inicial
-
barco
-
body
-
-
Escolha Pré-visualizar.
-
Verifique se as colunas foram eliminadas e escolha Adicionar.
Para fazer isso usando o pandas, siga estas etapas:
-
Na coluna Todas as etapas, escolha Adicionar etapa.
-
Na lista Transformação personalizada, escolha Transformação personalizada.
-
Forneça um nome para sua transformação e escolha Python (Pandas) na lista suspensa.
-
Insira o seguinte script Python na caixa de código:
cols = ['name', 'ticket', 'cabin', 'sibsp', 'parch', 'home.dest','boat', 'body'] df = df.drop(cols, axis=1) -
Escolha Visualizar para visualizar a alteração e, em seguida, escolha Adicionar para adicionar a transformação.
Limpeza de valores ausentes
Agora, limpe os valores ausentes. Você pode fazer isso com o grupo de transformação Lidar com valores ausentes.
Várias colunas têm valores ausentes. Das colunas restantes, idade e tarifa contêm valores ausentes. Inspecione isso usando uma Transformação personalizada.
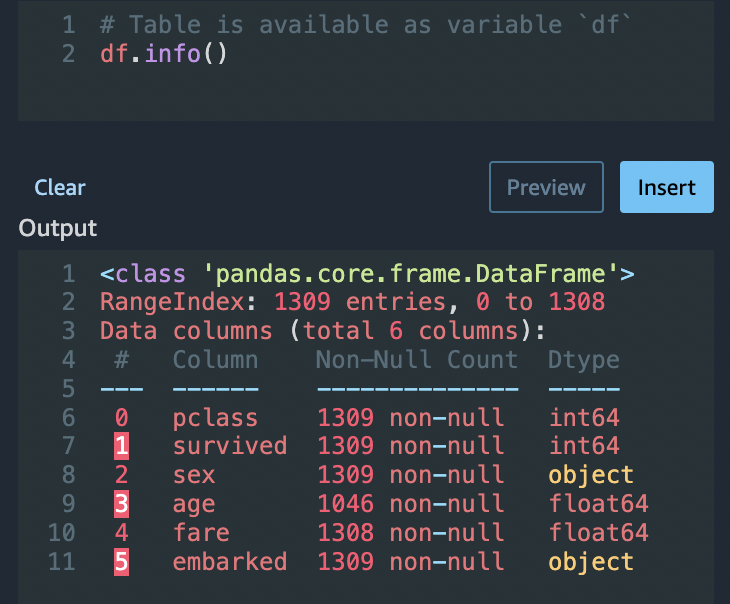
Usando a opção Python (Pandas), use o seguinte para analisar rapidamente o número de entradas em cada coluna:
df.info()
Para eliminar linhas com valores ausentes na categoria idade, faça o seguinte:
-
Escolha Processar ausentes.
-
Escolha Soltar ausentes para o Transformador.
-
Escolha idade para a coluna Entrada.
-
Escolha Visualizar para ver o novo quadro de dados e, em seguida, escolha Adicionar para adicionar a transformação ao seu fluxo.
-
Repita o mesmo processo para a tarifa.
Você pode usar df.info() na seção Transformação personalizada para confirmar que todas as linhas agora têm 1.045 valores.
Pandas personalizados: codificar
Experimente a codificação plana usando o Pandas. A codificação de dados categóricos é o processo de criação de uma representação numérica para categorias. Por exemplo, se suas categorias são Dog e Cat, você pode codificar essas informações em dois vetores: [1,0] para representar Dog, e [0,1] para representar Cat.
-
Na seção Transformação personalizada, escolha Python (Pandas) na lista suspensa.
-
Insira o seguinte na caixa de código:
import pandas as pd dummies = [] cols = ['pclass','sex','embarked'] for col in cols: dummies.append(pd.get_dummies(df[col])) encoded = pd.concat(dummies, axis=1) df = pd.concat((df, encoded),axis=1) -
Escolha Visualizar para visualizar a alteração. A versão codificada de cada coluna será adicionada ao conjunto de dados.
-
Escolha Adicionar para adicionar a transformação.
SQL personalizado: SELEÇÃO das colunas
Agora, selecione as colunas que você deseja manter usando SQL. Para esta demonstração, selecione as colunas listadas na instrução SELECT a seguir. Como sobreviveu é sua coluna-alvo para o treinamento, coloque essa coluna em primeiro lugar.
-
Na seção Transformação personalizada, selecione SQL (PySpark SQL) na lista suspensa.
-
Insira o seguinte na caixa de código:
SELECT survived, age, fare, 1, 2, 3, female, male, C, Q, S FROM df; -
Escolha Visualizar para visualizar a alteração. As colunas listadas em sua instrução
SELECTsão as únicas colunas restantes. -
Escolha Adicionar para adicionar a transformação.
Exportação para um caderno do Data Wrangler
Ao terminar de criar um fluxo de dados, você tem várias opções de exportação. A seção a seguir explica como exportar para um caderno de trabalho do Data Wrangler. Um trabalho do Data Wrangler é usado para processar seus dados usando as etapas definidas em seu fluxo de dados. Para saber mais sobre todas as opções de exportação, consulte Exportar.
Exportação para um caderno de trabalho do Data Wrangler
Quando você exporta seu fluxo de dados usando um trabalho do Data Wrangler, o processo cria automaticamente um caderno Jupyter. Esse notebook abre automaticamente na sua instância do Studio Classic e está configurado para executar um trabalho de SageMaker processamento para executar o fluxo de dados do Data Wrangler, conhecido como trabalho do Data Wrangler.
-
Salve seu fluxo de dados. Selecione Arquivo e, em seguida, selecione Salvar fluxo do Data Wrangler.
-
Volte para a guia Fluxo de dados, selecione a última etapa em seu fluxo de dados (SQL) e escolha o + para abrir a navegação.
-
Escolha Exportar e Amazon S3 (via caderno Jupyter). Isso abre um caderno Jupyter.
-
Escolha qualquer kernel do Python 3 (Ciência de Dados) para o Kernel.
-
Quando o kernel for iniciado, execute as células no caderno até Kick off SageMaker Training Job (Opcional).
-
Opcionalmente, você pode executar as células no Kick off SageMaker Training Job (Opcional) se quiser criar um trabalho de treinamento de SageMaker IA para treinar um classificador XGBoost. Você pode encontrar o custo de executar um trabalho de SageMaker treinamento na Amazon SageMaker Pricing
. Como alternativa, você pode adicionar os blocos de código encontrados em Treinamento do classificador XGBoost ao caderno e executá-los para usar a biblioteca de código aberto XGBoost
para treinar um classificador XGBoost. -
Descomente e execute a célula em Cleanup e execute-a para reverter o SDK do SageMaker Python para sua versão original.
Você pode monitorar o status do trabalho do Data Wrangler no console de SageMaker IA na guia Processamento. Além disso, você pode monitorar seu trabalho no Data Wrangler usando a Amazon. CloudWatch Para obter informações adicionais, consulte Monitorar trabalhos SageMaker de processamento da Amazon com CloudWatch registros e métricas.
Se você iniciou um trabalho de treinamento, pode monitorar seu status usando o console de SageMaker IA em Trabalhos de treinamento na seção Treinamento.
Treinamento do classificador XGBoost
Você pode treinar um classificador binário XGBoost usando um notebook Jupyter ou um Amazon Autopilot. SageMaker Você pode usar o Autopilot para treinar e ajustar modelos automaticamente nos dados transformados diretamente em seu fluxo do Data Wrangler. Para obter informações sobre o Autopilot, consulte Treine modelos automaticamente em seu fluxo de dados.
No mesmo caderno que deu início ao trabalho do Data Wrangler, você pode extrair os dados e treinar um classificador binário XGBoost usando os dados preparados com o mínimo de preparação de dados.
-
Primeiro, atualize os módulos necessários usando
pipe remova o arquivo _SUCCESS (esse último arquivo é problemático durante o uso deawswrangler).! pip install --upgrade awscli awswrangler boto sklearn ! aws s3 rm {output_path} --recursive --exclude "*" --include "*_SUCCESS*" -
Leia os dados do Amazon S3. Você pode usar
awswranglerpara ler recursivamente todos os arquivos CSV no prefixo do S3. Os dados são então divididos em atributos e rótulos. O rótulo é a primeira coluna do quadro de dados.import awswrangler as wr df = wr.s3.read_csv(path=output_path, dataset=True) X, y = df.iloc[:,:-1],df.iloc[:,-1]-
Por fim, crie DMatrices (a estrutura primitiva do XGBoost para dados) e faça uma validação cruzada usando a classificação binária XGBoost.
import xgboost as xgb dmatrix = xgb.DMatrix(data=X, label=y) params = {"objective":"binary:logistic",'learning_rate': 0.1, 'max_depth': 5, 'alpha': 10} xgb.cv( dtrain=dmatrix, params=params, nfold=3, num_boost_round=50, early_stopping_rounds=10, metrics="rmse", as_pandas=True, seed=123)
-
Encerrando o Data Wrangler
Ao terminar de usar o Data Wrangler, recomendamos que você encerre a instância em que ele é executado para evitar cobranças adicionais. Para saber como encerrar a aplicação Data Wrangler e a instância associada, consulte Encerrando o Data Wrangler.
