As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como avaliar o modelo
Agora que você treinou e implantou um modelo usando o Amazon SageMaker AI, avalie o modelo para garantir que ele gere previsões precisas sobre novos dados. Para avaliação de modelos, use o conjunto de dados de teste que você criou em Preparar conjuntos de dados.
Avalie o modelo implantado nos serviços de hospedagem de SageMaker IA
Para avaliar o modelo e usá-lo na produção, invoque o endpoint com o conjunto de dados de teste e verifique se as inferências obtidas retornam a precisão de destino que você deseja alcançar.
Como avaliar o modelo
-
Configure a função a seguir para prever cada linha do conjunto de teste. No código de exemplo a seguir, o argumento
rowsé especificar o número de linhas a serem previstas por vez. Você pode alterar o valor para realizar uma inferência em lote que utilize totalmente o recurso de hardware da instância.import numpy as np def predict(data, rows=1000): split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1)) predictions = '' for array in split_array: predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')]) return np.fromstring(predictions[1:], sep=',') -
Execute o código a seguir para fazer predições do conjunto de dados de teste e traçar um histograma. Você precisa usar somente as colunas de atributos do conjunto de dados de teste, excluindo a 0ª coluna para os valores reais.
import matplotlib.pyplot as plt predictions=predict(test.to_numpy()[:,1:]) plt.hist(predictions) plt.show()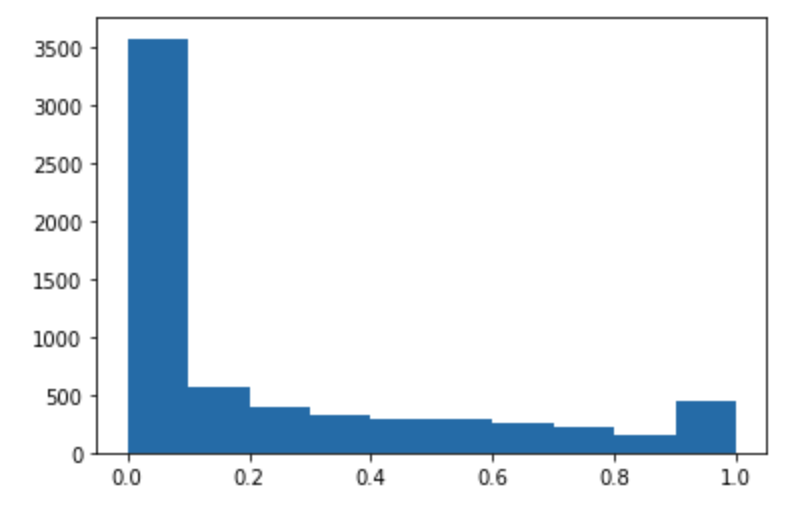
-
Os valores previstos são do tipo flutuante. Para determinar
TrueouFalsecom base nos valores flutuantes, você precisa definir um valor limite. Conforme mostrado no código de exemplo a seguir, use a Scikit-learn biblioteca para retornar as métricas de confusão de saída e o relatório de classificação com um limite de 0,5.import sklearn cutoff=0.5 print(sklearn.metrics.confusion_matrix(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0))) print(sklearn.metrics.classification_report(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0)))Isso deve retornar a seguinte matriz de confusão:
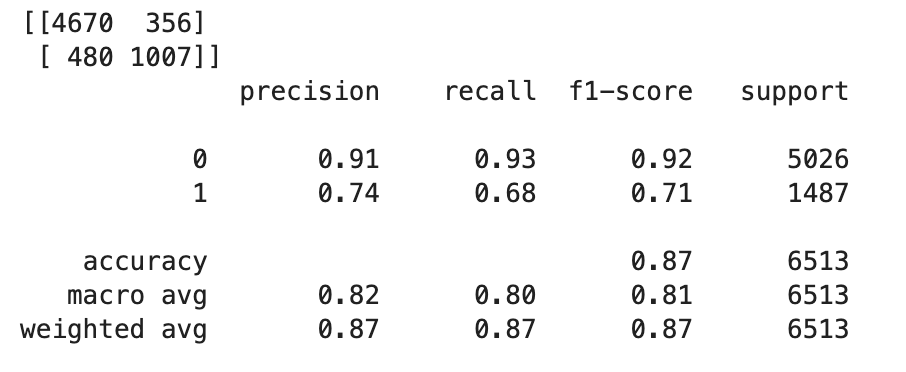
-
Para encontrar o melhor ponto de corte com o conjunto de testes fornecido, calcule a função de perda de log da regressão logística. A função de perda de logs é definida como a probabilidade logarítmica negativa de um modelo logístico que retorna probabilidades de predição para seus rótulos de verdade básica. O código de exemplo a seguir calcula numericamente e iterativamente os valores de perda de log (
-(y*log(p)+(1-y)log(1-p)), ondeyestá o rótulo verdadeiro epé uma estimativa de probabilidade da amostra de teste correspondente. Ele retorna um gráfico de perda de logs versus corte.import matplotlib.pyplot as plt cutoffs = np.arange(0.01, 1, 0.01) log_loss = [] for c in cutoffs: log_loss.append( sklearn.metrics.log_loss(test.iloc[:, 0], np.where(predictions > c, 1, 0)) ) plt.figure(figsize=(15,10)) plt.plot(cutoffs, log_loss) plt.xlabel("Cutoff") plt.ylabel("Log loss") plt.show()Isso deve retornar a seguinte: curva de perda de logs.
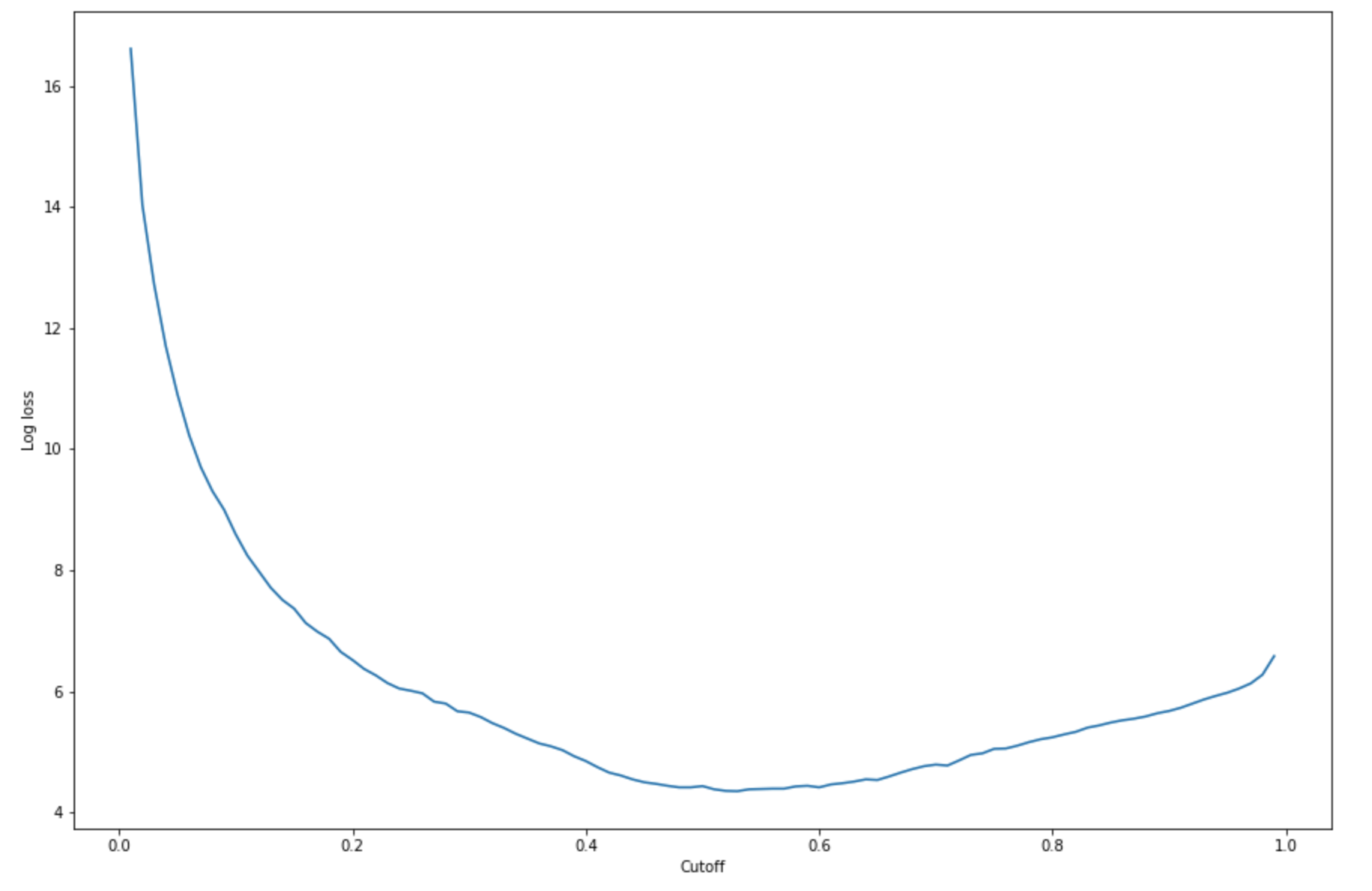
-
Encontre os pontos mínimos da curva de erro usando as
minfunções NumPyargmine:print( 'Log loss is minimized at a cutoff of ', cutoffs[np.argmin(log_loss)], ', and the log loss value at the minimum is ', np.min(log_loss) )Isso deve retornar:
Log loss is minimized at a cutoff of 0.53, and the log loss value at the minimum is 4.348539186773897.Em vez de computar e minimizar a função de perda de log, você pode estimar uma função de custo como alternativa. Por exemplo, se você quiser treinar um modelo para realizar uma classificação binária para um problema empresarial, como um problema de Predição de fragmentos de clientes, você pode definir pesos para os elementos da matriz de confusão e calcular a função de custo adequadamente.
Agora você treinou, implantou e avaliou seu primeiro modelo em SageMaker IA.
dica
Para monitorar a qualidade do modelo, a qualidade dos dados e o desvio de tendências, use o Amazon SageMaker Model Monitor e o SageMaker AI Clarify. Para saber mais, consulte Amazon SageMaker Model Monitor, Monitore Data Quality, Monitore Model Quality, Monitore Bias Drift e Monitore Feature Attribution Drift.
dica
Para obter uma análise humana de predições de ML de baixa confiança ou uma amostra aleatória de predições, use os fluxos de trabalho de análise humana com IA aumentada da Amazon. Para obter mais informações, consulte Usando o Amazon IA aumentada para análise humana.
