As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
geração aumentada via recuperação
Os modelos de base geralmente são treinados offline, tornando o modelo independente de quaisquer dados criados após o treinamento do modelo. Além disso, os modelos de base são treinados em corpora de domínio muito gerais, tornando-os menos eficazes para tarefas específicas do domínio. Você pode usar a geração aumentada via recuperação (RAG) para recuperar dados de fora de um modelo de base e aumentar seus prompts adicionando os dados recuperados relevantes no contexto. Para obter mais informações sobre as arquiteturas do modelo RAG, consulte Geração aumentada via recuperação para tarefas de PNL com uso intensivo de conhecimento
Com o RAG, os dados externos usados para aumentar suas solicitações podem vir de várias fontes de dados, como repositórios de documentos, bancos de dados ou. APIs A primeira etapa é converter seus documentos e quaisquer consultas do usuário em um formato compatível para realizar a pesquisa de relevância. Para tornar os formatos compatíveis, uma coleção de documentos ou biblioteca de conhecimento e consultas enviadas pelo usuário são convertidas em representações numéricas usando modelos de linguagem de incorporação. A incorporação é o processo pelo qual o texto recebe representação numérica em um espaço vetorial. As arquiteturas do modelo RAG comparam as incorporações das consultas do usuário no vetor da biblioteca de conhecimento. O prompt original do usuário é então anexado com o contexto relevante de documentos semelhantes na biblioteca de conhecimento. Esse prompt aumentada é então enviada para o modelo de base. Você pode atualizar as bibliotecas de conhecimento e suas incorporações relevantes de forma assíncrona.
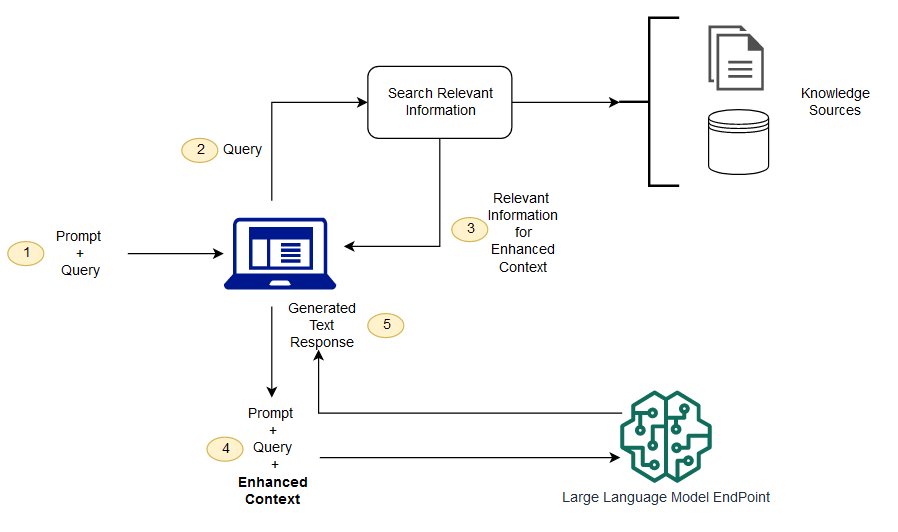
Para ajudar a aumentar o prompt, o documento recuperado deve ser grande o suficiente para conter um contexto útil, e pequeno o suficiente para caber no tamanho máximo da sequência do prompt. Você pode usar JumpStart modelos específicos de tarefas, como o modelo General Text Embeddings (GTE) da Hugging Face, para fornecer as incorporações para seus prompts e documentos da biblioteca de conhecimento. Depois de comparar o prompt e as incorporações dos documentos para encontrar aqueles mais relevantes, crie um novo prompt com o contexto adicional. Em seguida, passe o prompt aumentado para um modelo de geração de texto de sua escolha.
Cadernos de exemplo
Para obter mais informações sobre as soluções de modelos de base da RAG, consulte os seguintes cadernos de exemplos:
Você pode clonar o repositório de exemplos de SageMaker IA da Amazon
