As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Automatize a rotulagem de dados
Se você escolher, o Amazon SageMaker Ground Truth pode usar o aprendizado ativo para automatizar a rotulagem de seus dados de entrada para determinados tipos de tarefas incorporadas. A aprendizagem ativa é uma técnica de machine learning que identifica os dados que devem ser rotulados pelos trabalhadores. No Ground Truth, essa funcionalidade é chamada de rotulagem automatizada de dados. A rotulagem automatizada de dados ajuda a reduzir o custo e o tempo que se leva para rotular seu conjunto de dados em comparação com o uso somente de trabalhadores humanos. Ao usar a rotulagem automatizada, você incorre em custos SageMaker de treinamento e inferência.
Recomendamos o uso de rotulagem automatizada de dados em grandes conjuntos de dados porque as redes neurais usadas com aprendizagem ativa exigem uma quantidade significativa de dados para cada novo conjunto de dados. Normalmente, à medida que mais dados são fornecidos, o potencial de previsões de alta precisão aumenta. Os dados só serão rotulados automaticamente se a rede neural usada no modelo de rotulagem automática puder atingir um nível aceitavelmente alto de precisão. Portanto, com conjuntos de dados maiores, há mais potencial para rotular automaticamente os dados porque a rede neural pode ter precisão suficientemente alta para a rotulagem automática. A rotulagem automatizada de dados é mais apropriada quando você tem milhares de objetos de dados. O número mínimo de objetos permitidos para a rotulação automatizada de dados é de 1.250, mas é altamente recomendável fornecer um mínimo de 5.000 objetos.
A rotulagem automatizada de dados está disponível somente para os seguintes tipos de tarefa integradas do Ground Truth:
Os trabalhos de rotulagem de streaming não oferecem suporte à rotulagem automatizada de dados.
Para saber como criar um fluxo de trabalho de aprendizado ativo personalizado usando seu próprio modelo, consulte Configure um fluxo de trabalho de aprendizado ativo com seu próprio modelo.
As cotas de dados de entrada aplicam-se a trabalhos de rotulagem automatizada. Consulte Cotas de dados de entrada para obter informações sobre tamanho do conjunto de dados, tamanho dos dados de entrada e limites de resolução.
nota
Antes de usar um modelo de rotulagem automatizada na produção, é necessário ajustar ou testar o modelo, ou ambos. É possível ajustar o modelo (ou criar e ajustar outro modelo supervisionado de sua escolha) no conjunto de dados produzido pelo seu trabalho de rotulagem para otimizar a arquitetura e os hiperparâmetros do modelo. Se você decidir usar o modelo para inferência sem ajustá-lo, é altamente recomendado certificar-se de que sua precisão seja avaliada em um subconjunto representativo (por exemplo, selecionado aleatoriamente) do conjunto de dados rotulado com o Ground Truth e que ele corresponda às suas expectativas.
Como funciona
A rotulagem automatizada de dados é habilitada durante a criação de um trabalho de rotulagem. Como funciona:
-
Quando o Ground Truth inicia um trabalho de rotulação automatizada de dados, ele seleciona uma amostra aleatória de objetos de dados e a envia para trabalhadores humanos. Se mais de 10% desses objetos de dados falharem, o trabalho de rotulagem falhará. Se o trabalho de rotulagem falhar, além de revisar qualquer mensagem de erro retornada pelo Ground Truth, verifique se os dados de entrada estão sendo exibidos corretamente na interface do usuário do trabalhador, se as instruções estão claras e se você deu aos trabalhadores tempo suficiente para concluir as tarefas.
-
Quando os dados rotulados são retornados, eles são usados para criar um conjunto de treinamento e um conjunto de validação. A Ground Truth usa esses conjuntos de dados para treinar e validar o modelo usado para rotulagem automática.
-
O Ground Truth executa um trabalho de transformação de lotes, usando o modelo validado para inferência nos dados de validação. A inferência de lote produz uma pontuação de confiança e uma métrica de qualidade para cada objeto nos dados de validação.
-
O componente de rotulagem automática usará essas métricas de qualidade e pontuações de confiança para criar um limite de pontuação de confiança que garanta rótulos de qualidade.
-
O Ground Truth executa um trabalho de transformação de lotes nos dados não rotulados do conjunto de dados, usando o mesmo modelo validado para inferência. Isso produzirá uma pontuação de confiança para cada objeto.
-
O componente de rotulagem automática do Ground Truth determina se a pontuação de confiança produzida na etapa 5 para cada objeto atende ao limite necessário determinado na etapa 4. Se a pontuação de confiança atender ao limite, a qualidade esperada da rotulagem automaticamente excederá o nível de precisão solicitado e esse objeto será considerado com rotulagem automática.
-
A etapa 6 produz um conjunto de dados de dados não rotulados com pontuações de confiança. A Ground Truth seleciona pontos de dados com pontuações de baixa confiança desse conjunto de dados e os envia para trabalhadores humanos.
-
O Ground Truth usa os dados existentes rotulados por trabalhadores humanos e esses dados de rótulos adicionais de trabalhadores humanos para atualizar o modelo.
-
O processo é repetido até que o conjunto de dados seja totalmente rotulado ou até que outra condição de interrupção seja atendida. Por exemplo, a rotulagem automática será interrompida se o seu orçamento de anotação humana for atingido.
As etapas anteriores acontecem em iterações. Selecione cada guia na tabela a seguir para ver um exemplo dos processos que ocorrem em cada iteração para um trabalho de rotulagem automática de detecção de objetos. O número de objetos de dados usados em uma determinada etapa nessas imagens (por exemplo, 200) é específico para este exemplo. Se houver menos de 5.000 objetos para rotular, o tamanho do conjunto de validação será 20% de todo o conjunto de dados. Se houver mais de 5.000 objetos no conjunto de dados de entrada, o tamanho do conjunto de validação será 10% de todo o conjunto de dados. Você pode controlar o número de rótulos humanos coletados por iteração de aprendizado ativa alterando o valor MaxConcurrentTaskCount ao usar a operação de API CreateLabelingJob. Esse valor é definido como 1.000 quando você cria um trabalho de etiquetagem usando o console. No fluxo de aprendizado ativo ilustrado na guia Aprendizado ativo, esse valor é definido como 200.
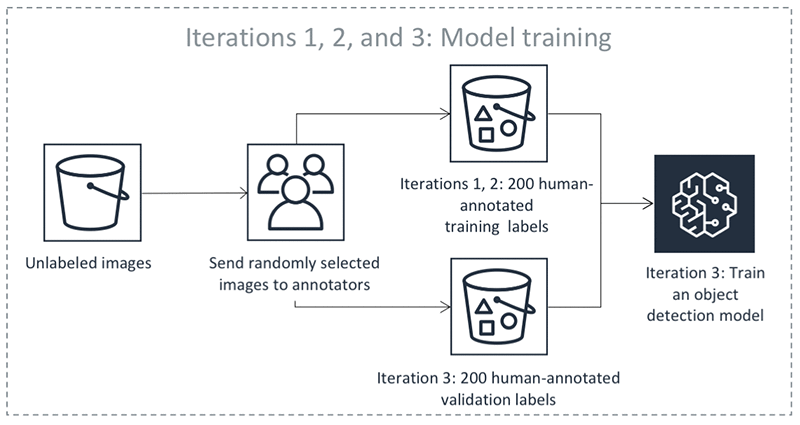
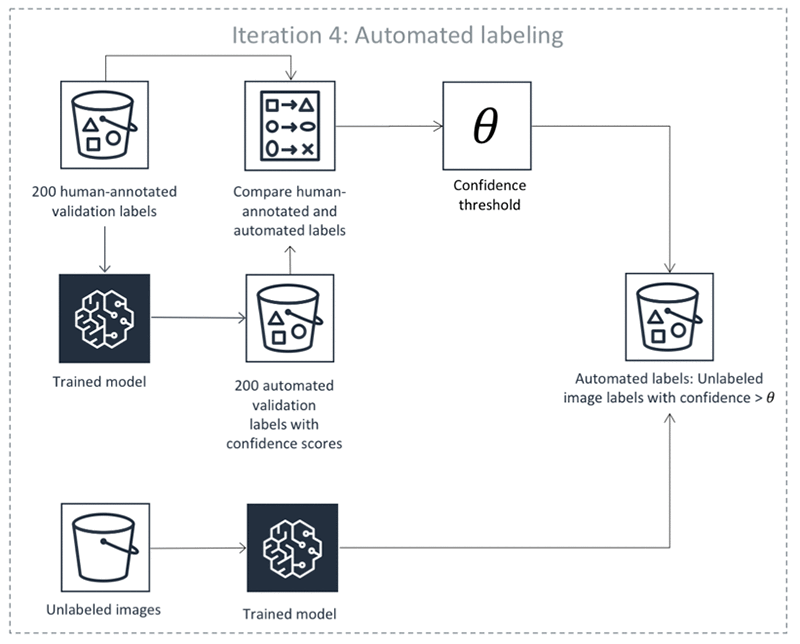
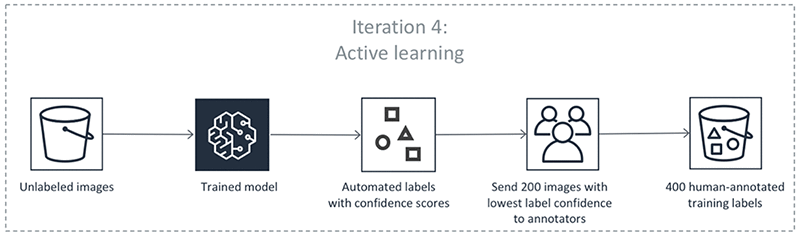
Precisão das etiquetas automatizadas
A definição de precisão depende do tipo de tarefa incorporada que você usa com a rotulagem automatizada. Para todos os tipos de tarefas, esses requisitos de precisão são predeterminados pelo Ground Truth e não podem ser configurados manualmente.
-
Para classificação de imagens e classificação de texto, o Ground Truth usa a lógica para encontrar um nível de confiança de predição de rótulos que corresponda a pelo menos 95% de precisão dos rótulos. Isso significa que o Ground Truth espera que a precisão dos rótulos automatizados seja de pelo menos 95% em comparação com os rótulos que os rotuladores humanos forneceriam para esses exemplos.
-
Para caixas delimitadoras, a média esperada de interseção sobre união (IoU)
das imagens rotuladas automaticamente é 0,6. Para encontrar a IOU média, o Ground Truth calcula a IOU média de todas as caixas previstas e perdidas na imagem para cada classe e, em seguida, calcula a média desses valores entre as classes. -
Para segmentação semântica, a IOU média esperada das imagens rotuladas automaticamente é 0,7. Para encontrar a média de IoU, o Ground Truth pega a média dos valores de IoU de todas as classes na imagem (excluindo o plano de fundo).
Em cada iteração do Aprendizado Ativo (etapas de 3 a 6 na lista acima), o limite de confiança é encontrado usando o conjunto de validação anotado por humanos para que a precisão esperada dos objetos rotulados automaticamente satisfaça certos requisitos de precisão predefinidos.
Crie uma tarefa automatizada de rotulagem de dados (console)
Para criar um trabalho de rotulagem que usa rotulagem automatizada no console SageMaker AI, use o procedimento a seguir.
Como criar um trabalho automatizado de rotulagem de dados (console)
-
Abra a seção de trabalhos da Ground Truth Labeling do console SageMaker AI:https://console.aws.amazon.com/sagemaker/groundtruth
. -
Usando Criar um trabalho de rotulagem (console) como guia, conclua as seções Job overview (Visão geral do trabalho) e Task type (Tipo de tarefa). Observe que a rotulagem automática não oferece suporte a tipos de tarefa personalizados.
-
Em Workers (Trabalhadores), escolha o tipo de força de trabalho.
-
Na mesma seção, escolha Enable automated data labeling (Habilitar rotulagem automatizada de dados).
-
Usando Configurar a ferramenta de caixa delimitadora como guia, crie instruções para trabalhadores na ferramenta de
Task Typerotulagem de seções. Por exemplo, se você selecionou Segmentação de semântica como o tipo de trabalho de rotulagem, esta seção será chamada Ferramenta de rotulagem de segmentação de semântica. -
Para visualizar as instruções e o painel do trabalhador, escolha Preview (Visualizar).
-
Escolha Criar. Isso criará e iniciará o trabalho de rotulagem e o processo de rotulagem automática.
Você pode ver seu trabalho de etiquetagem aparecer na seção Trabalhos de etiquetagem do console de SageMaker IA. Os dados de saída serão exibidos no bucket do Amazon S3 especificado durante a criação do trabalho de rotulagem. Para obter mais informações sobre o formato e a estrutura do arquivo dos dados de saída do trabalho de rotulagem, consulte Rotulando dados de saída do trabalho.
Crie um trabalho automatizado de rotulagem de dados (API)
Para criar um trabalho automatizado de rotulagem de dados usando a SageMaker API, use o LabelingJobAlgorithmsConfigparâmetro da CreateLabelingJoboperação. Para saber como iniciar um trabalho de etiquetagem usando a CreateLabelingJob operação, consulte Criar um trabalho de rotulagem (API).
Especifique o Amazon Resource Name (ARN) do algoritmo que você está usando para rotulagem automática de dados no LabelingJobAlgorithmSpecificationArnparâmetro. Escolha um dos quatro algoritmos integrados do Ground Truth com suporte para rotulagem automatizada:
Quando um trabalho de rotulagem automatizada de dados for concluído, o Ground Truth retornará o ARN do modelo usado para o trabalho. Use esse modelo como modelo inicial para tipos de tarefas de rotulagem automática semelhantes fornecendo o ARN, em formato de string, no InitialActiveLearningModelArnparâmetro. Para recuperar o ARN do modelo, use AWS Command Line Interface um comando AWS CLI() semelhante ao seguinte.
# Fetch the mARN of the model trained in the final iteration of the previous labeling job.Ground Truth pretrained_model_arn = sagemaker_client.describe_labeling_job(LabelingJobName=job_name)['LabelingJobOutput']['FinalActiveLearningModelArn']
Para criptografar dados no volume de armazenamento anexado às instâncias de computação de ML que são usadas na rotulagem automática, inclua uma chave AWS Key Management Service (AWS KMS) no VolumeKmsKeyId parâmetro. Para obter informações sobre chaves AWS KMS, consulte O que é o AWS Key Management Service? no Guia do desenvolvedor do AWS Key Management Service.
Para ver um exemplo que usa a CreateLabelingJoboperação para criar um trabalho automatizado de rotulagem de dados, consulte o exemplo object_detection_tutorial na seção AI Examples SageMaker , Ground Truth Labeling Jobs de uma instância de notebook de IA. SageMaker Para saber como criar e abrir uma instância de bloco de anotações, consulte Crie uma instância de SageMaker notebook da Amazon. Para saber como acessar notebooks de exemplo de SageMaker IA, consulteCadernos de exemplo de acesso.
EC2 Instâncias da Amazon necessárias para rotulagem automatizada de dados
A tabela a seguir lista as instâncias do Amazon Elastic Compute Cloud (Amazon EC2) que você precisa para executar a rotulagem automática de dados para trabalhos de treinamento e inferência em lote.
| Tipo de trabalho de rotulagem automatizada de dados | Tipo de instância de treinamento | Tipo de instância de inferência |
|---|---|---|
|
Classificação de imagens |
ml.p3.2xlarge* |
ml.c5.xlarge |
|
Detecção de objetos (caixa delimitadora) |
ml.p3.2xlarge* |
ml.c5.4xlarge |
|
Classificação de texto |
ml.c5.2xlarge |
ml.m4.xlarge |
|
Segmentação semântica |
ml.p3.2xlarge* |
ml.p3.2xlarge* |
* Na região Ásia-Pacífico (Mumbai) (ap-south-1), use ml.p2.8xlarge no lugar.
O Ground Truth gerencia as instâncias usadas para trabalhos de rotulagem automatizada de dados. Ele cria, configura e encerra as instâncias conforme necessário para executar o trabalho. Essas instâncias não aparecem no seu painel de EC2 instâncias da Amazon.
Configure um fluxo de trabalho de aprendizado ativo com seu próprio modelo
Você pode criar um fluxo de trabalho de aprendizado ativo com seu próprio algoritmo para executar treinamentos e inferências nesse fluxo de trabalho para rotular automaticamente seus dados. O notebook bring_your_own_model_for_sagemaker_labeling_workflows_with_active_learning.ipynb demonstra isso usando o algoritmo integrado de IA,. SageMaker BlazingText Esse notebook fornece uma AWS CloudFormation pilha que você pode usar para executar esse fluxo de trabalho usando AWS Step Functions. Você pode encontrar o notebook e os arquivos de suporte neste GitHub repositório.
Você também pode encontrar esse caderno no repositório de exemplos de SageMaker IA. Consulte Use exemplos de cadernos para saber como encontrar um exemplo de caderno de SageMaker inteligência artificial da Amazon.
