As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Criar um vocabulário personalizado usando uma tabela
Usar um formato de tabela é a forma preferencial de criar um vocabulário personalizado. As tabelas de vocabulário devem consistir em quatro colunas (Phrase, SoundsLike, IPA, and DisplayAs), que pode ser incluído em qualquer pedido:
| Phrase | SoundsLike | IPA | DisplayAs |
|---|---|---|---|
|
Obrigatório. Cada linha na tabela deve conter uma entrada nessa coluna. Não use espaços nessa coluna. Se a entrada tiver várias palavras, separe cada uma com um hífen (-). Por exemplo, Para acrônimos, todas as letras pronunciadas devem ser separadas por um ponto. O ponto final também precisa ser pronunciado. Se o acrônimo estiver no plural, você deverá usar um hífen entre ele e o “s”. Por exemplo, 'CLI' é Se a frase consistir em uma palavra e um acrônimo, esses dois componentes devem ser separados por um hífen. Por exemplo, “DynamoDB” é Não inclua dígitos nessa coluna; os números devem ser escritos por extenso. Por exemplo, “VX02Q” é |
|
|
Opcional. As linhas nessa coluna podem ser deixadas vazias. Não é possível usar espaços nessa coluna. Define como você deseja que a entrada apareça na saída da transcrição. Por exemplo, Se uma linha nessa coluna estiver vazia, Amazon Transcribe usa o conteúdo da Você pode incluir dígitos ( |
Fatores a observar ao criar a tabela:
-
Sua tabela deve conter todos os quatro cabeçalhos de coluna (Phrase, SoundsLike, IPA, and DisplayAs). A
Phrasecoluna deve conter uma entrada em cada linha. A capacidade de fornecer entradas de pronúncia por meioIPAe nãoSoundsLikeé mais suportada, e você pode deixar a coluna vazia. Todos os valores nessas colunas serão ignorados. -
Cada coluna deve ser delineada com TAB ou vírgula (,); isso se aplica a todas as linhas do arquivo de vocabulário personalizado. Se uma linha tiver colunas vazias, você também deverá incluir um delineador (TAB ou vírgula) para cada coluna.
-
Os espaços só são permitidos nas colunas
IPAeDisplayAs. Não use espaços para separar colunas. -
IPAe nãoSoundsLikesão mais compatíveis com o vocabulário personalizado. Por favor, deixe a coluna vazia. Todos os valores nessas colunas serão ignorados. Nós removeremos o suporte para essa coluna futuramente. -
A coluna
DisplayAsaceita símbolos e caracteres especiais (por exemplo, C++). Todas as outras colunas permitem os caracteres listados na página de conjunto de caracteres do seu idioma. -
Se quiser incluir números na coluna
Phrase, você deve soletrá-los. Só é possível usar dígitos (0-9) na colunaDisplayAs. -
Você deve salvar a tabela como um arquivo de texto simples (*.txt) no formato
LF. Se você usar qualquer outro formato, comoCRLF, seu vocabulário personalizado não poderá ser processado. -
Você deve carregar seu arquivo de vocabulário personalizado em um Amazon S3 bucket e processá-lo
CreateVocabularyantes de incluí-lo em uma solicitação de transcrição. Consulte Criar tabelas de vocabulário personalizado para ver as instruções.
nota
Insira acrônimos ou outras palavras cujas letras devem ser pronunciadas individualmente como letras únicas separadas por pontos (A.B.C.). Para inserir a forma plural de um acrônimo, como '', separe o ABCs 's' do acrônimo com um hífen (). A.B.C.-s É possível usar letras maiúsculas ou minúsculas para definir um acrônimo. Nem todos os idiomas aceitam acrônimos. Consulte Idiomas oferecidos e recursos específicos do idioma.
Veja um exemplo de tabela de vocabulário personalizado (em que [TAB] representa um caractere de tabulação):
Phrase[TAB]SoundsLike[TAB]IPA[TAB]DisplayAs
Los-Angeles[TAB][TAB][TAB]Los Angeles
Eva-Maria[TAB][TAB][TAB]
A.B.C.-s[TAB][TAB][TAB]ABCs
Amazon-dot-com[TAB][TAB][TAB]Amazon.com
C.L.I.[TAB][TAB][TAB]CLI
Andorra-la-Vella[TAB][TAB][TAB]Andorra la Vella
Dynamo-D.B.[TAB][TAB][TAB]DynamoDB
V.X.-zero-two[TAB][TAB][TAB]VX02
V.X.-zero-two-Q.[TAB][TAB][TAB]VX02QPara maior clareza visual, apresentamos a mesma tabela com colunas alinhadas. Não adicione espaços entre as colunas na tabela de vocabulário personalizado; a tabela deve ficar desalinhada, como no exemplo anterior.
Phrase [TAB]SoundsLike [TAB]IPA [TAB]DisplayAs
Los-Angeles [TAB] [TAB] [TAB]Los Angeles
Eva-Maria [TAB] [TAB] [TAB]
A.B.C.-s [TAB] [TAB] [TAB]ABCs
amazon-dot-com [TAB] [TAB] [TAB]amazon.com
C.L.I. [TAB] [TAB] [TAB]CLI
Andorra-la-Vella[TAB] [TAB] [TAB]Andorra la Vella
Dynamo-D.B. [TAB] [TAB] [TAB]DynamoDB
V.X.-zero-two [TAB] [TAB] [TAB]VX02
V.X.-zero-two-Q.[TAB] [TAB] [TAB]VX02QCriar tabelas de vocabulário personalizado
Para processar uma tabela de vocabulário personalizada para uso com Amazon Transcribe, veja os exemplos a seguir:
-
Faça login no AWS Management Console
. -
No painel de navegação, selecione Vocabulário personalizado. Isso abre a página Vocabulário personalizado, na qual você pode visualizar os vocabulários existentes ou criar um.
-
Selecione Criar vocabulário.
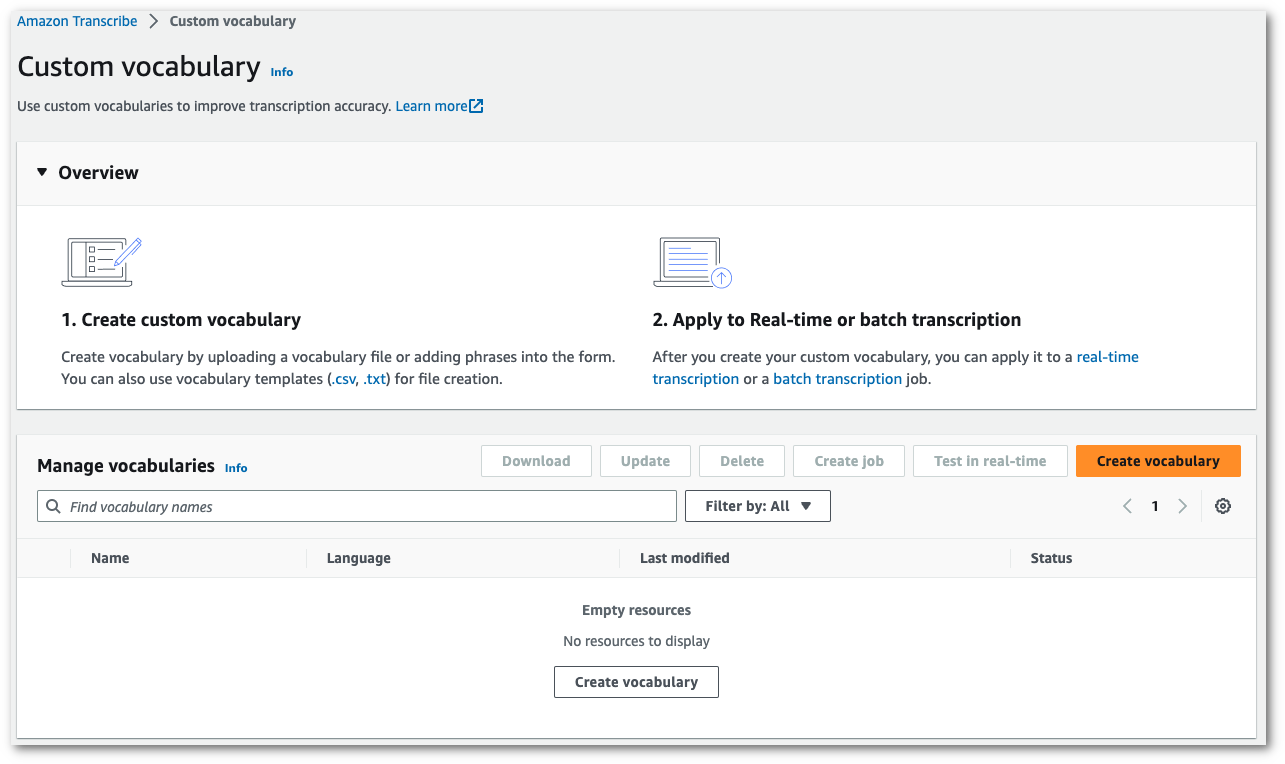
Isso abre a página Criar vocabulário. Insira um nome para o novo vocabulário personalizado.
Aqui, você tem três opções:
-
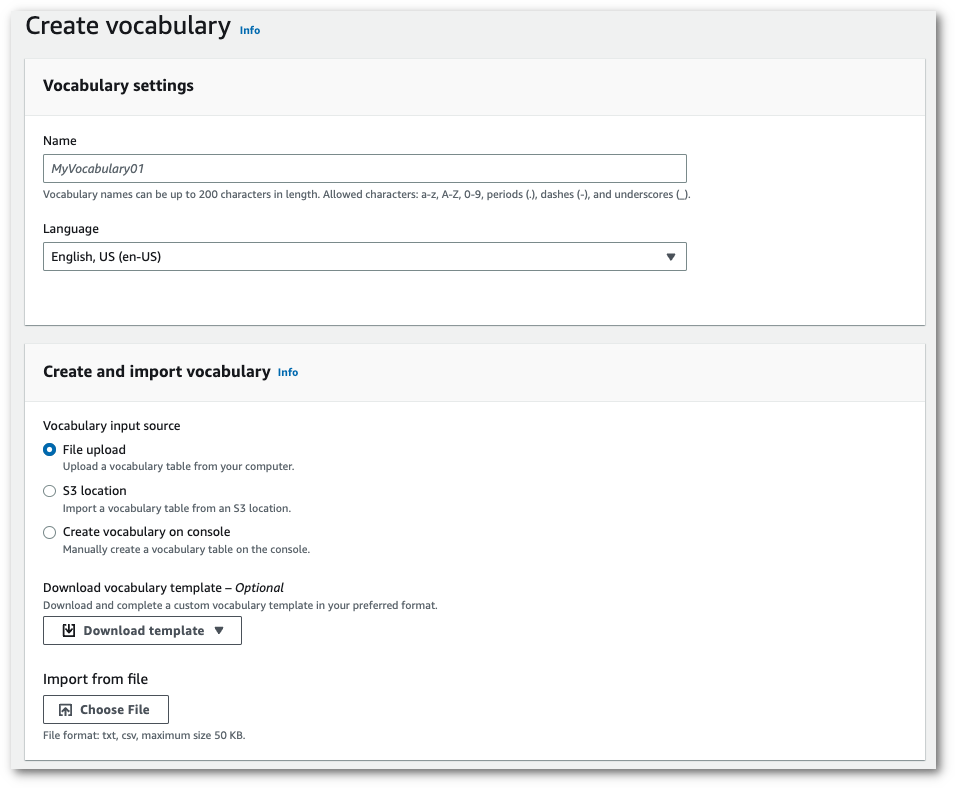
Carregue um arquivo txt ou csv de seu computador.
Você pode criar o vocabulário personalizado do zero ou baixar um modelo para ajudar você a começar. O vocabulário é preenchido automaticamente no painel Visualize e edite o vocabulário.
-
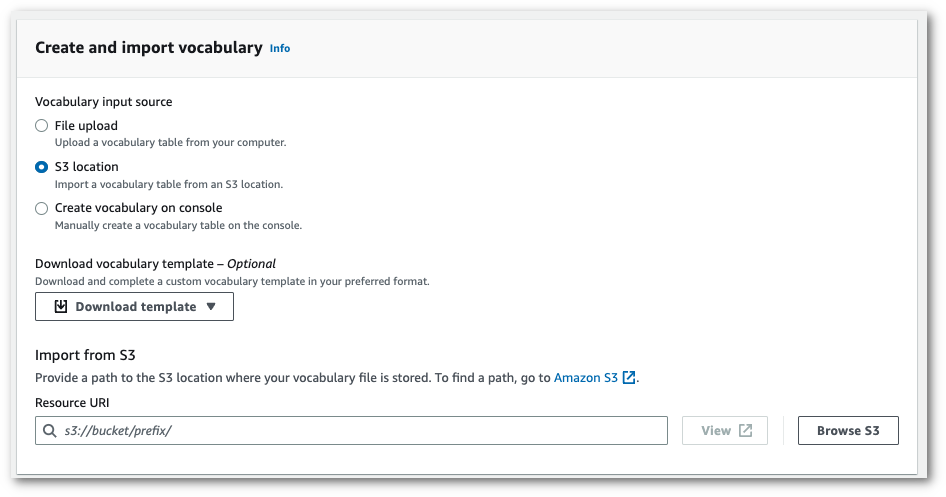
Importe um arquivo txt ou csv de um Amazon S3 local.
Você pode criar o vocabulário personalizado do zero ou baixar um modelo para ajudar você a começar. Carregue o arquivo do vocabulário finalizado em um bucket do Amazon S3 e especifique o URI dele em sua solicitação. O vocabulário é preenchido automaticamente no painel Visualize e edite o vocabulário.
-
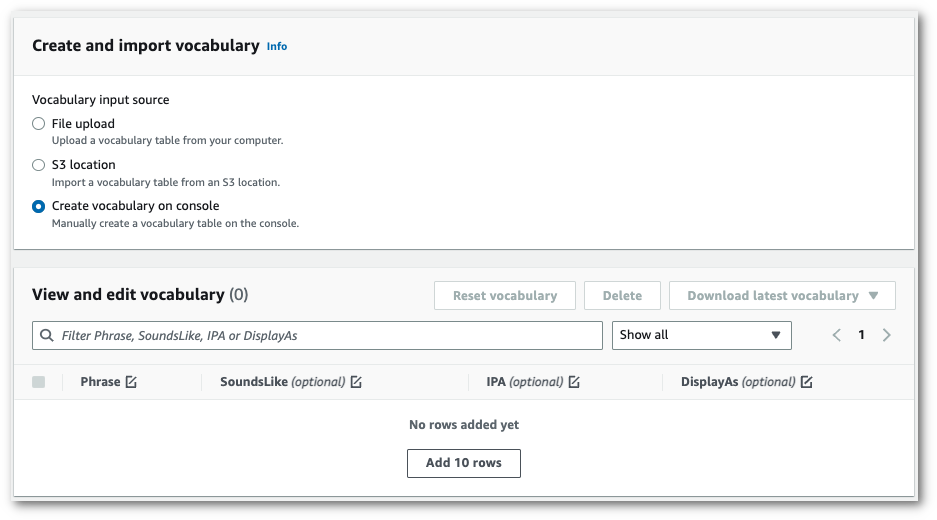
Crie manualmente o vocabulário no console.
Role até o painel Visualize e edite o vocabulário e selecione Adicionar 10 linhas. Agora você pode inserir termos manualmente.
-
-
É possível editar o vocabulário no painel Visualize e edite o vocabulário. Para fazer alterações, clique na entrada que deseja modificar.
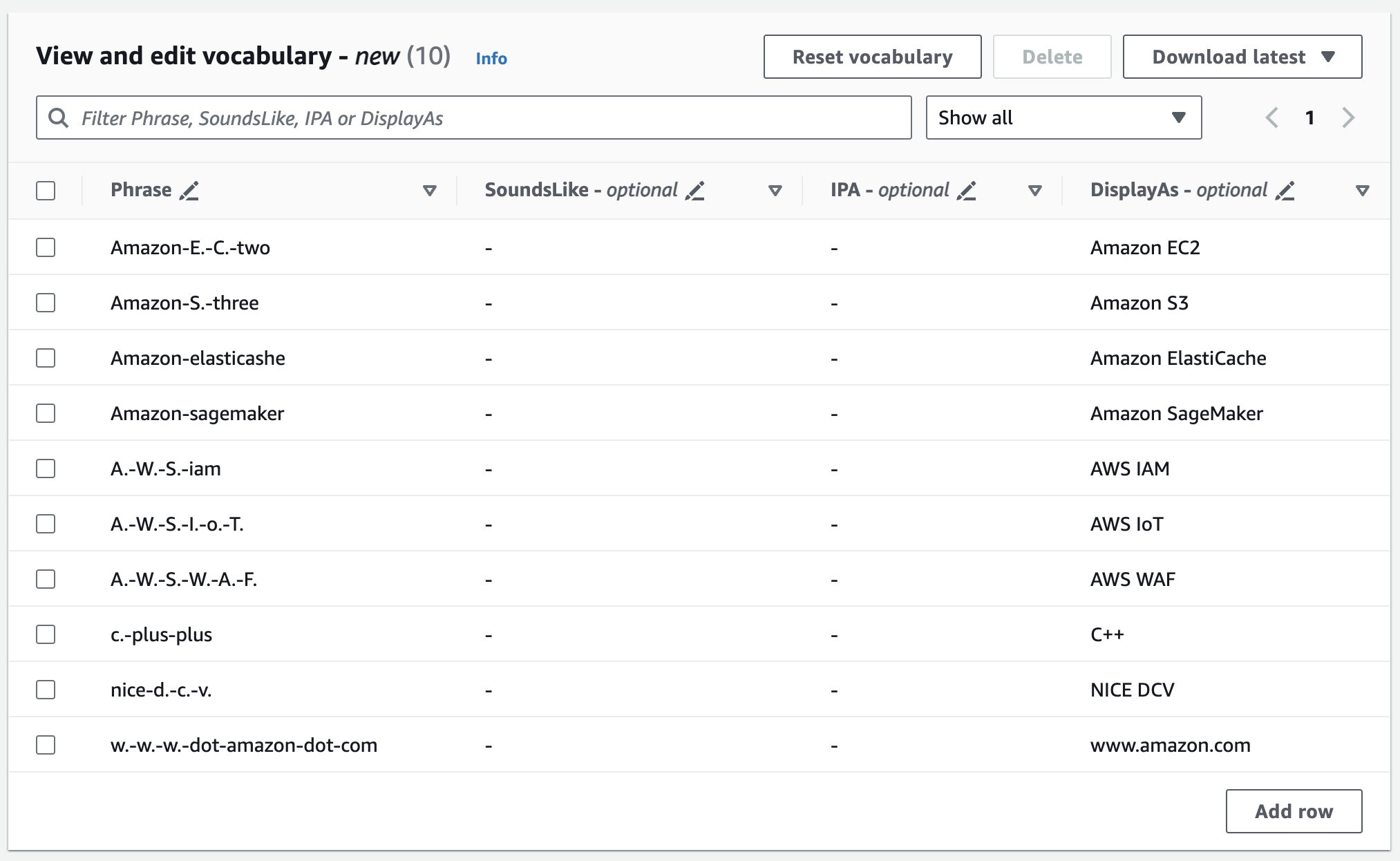
Se cometer um erro, você receberá uma mensagem de erro detalhada para poder corrigir qualquer problema antes de processar o vocabulário. Observe que, se você não corrigir todos os erros antes de selecionar Criar vocabulário, a solicitação de vocabulário falhará.
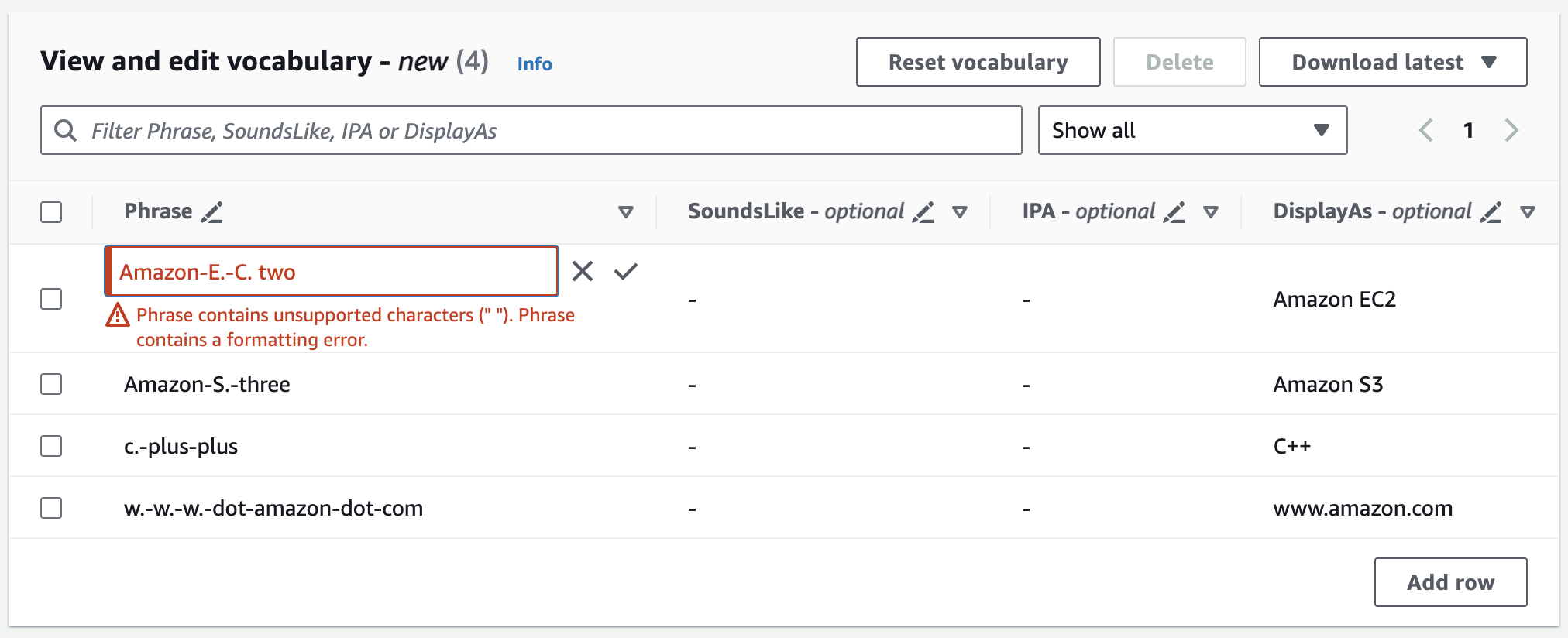
Selecione a marca de seleção (✓) para salvar as alterações ou o “X” para descartá-las.
-
Se preferir, adicione tags ao vocabulário personalizado. Depois que você preencher todos os campos e estiver contente com o vocabulário, selecione Criar vocabulário na parte inferior da página. Isso leva você de volta à página Vocabulário personalizado, onde é possível ver o status do vocabulário personalizado. Quando o status muda de “Pendente” para “Pronto”, o vocabulário personalizado pode ser usado com uma transcrição.

-
Se o status mudar para “Falhou”, selecione o nome do vocabulário personalizado para acessar a página de informações.
Há um banner Motivo da falha na parte superior dessa página que fornece informações sobre o motivo da falha do vocabulário personalizado. Corrija o erro no arquivo de texto e tente novamente.
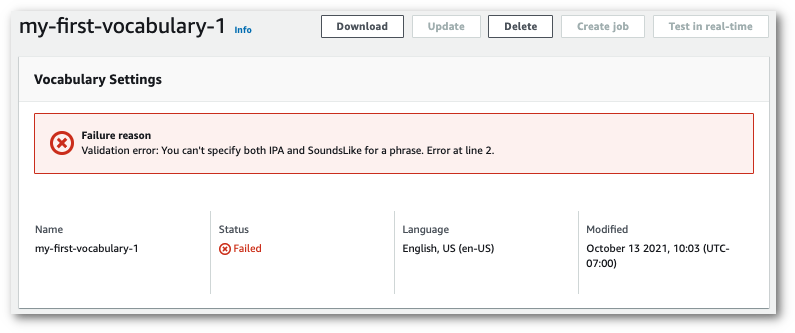
Este exemplo usa o comando create-vocabulary com um arquivo de vocabulário em formato de tabela. Para obter mais informações, consulte CreateVocabulary.
Para usar um vocabulário personalizado existente em um trabalho de transcrição, defina o VocabularyName no Settingscampo ao chamar a StartTranscriptionJoboperação ou, a partir do AWS Management Console, escolha o vocabulário personalizado na lista suspensa.
aws transcribe create-vocabulary \ --vocabulary-namemy-first-vocabulary\ --vocabulary-file-uri s3://amzn-s3-demo-bucket/my-vocabularies/my-vocabulary-file.txt \ --language-codeen-US
Veja a seguir outro exemplo usando o comando create-vocabulary e um corpo de solicitação que cria o vocabulário personalizado.
aws transcribe create-vocabulary \ --cli-input-json file://filepath/my-first-vocab-table.json
O arquivo my-first-vocab-table.json contém o seguinte corpo da solicitação.
{ "VocabularyName": "my-first-vocabulary", "VocabularyFileUri": "s3://amzn-s3-demo-bucket/my-vocabularies/my-vocabulary-table.txt", "LanguageCode": "en-US" }
Assim que VocabularyState muda de PENDING para READY, seu vocabulário personalizado estará pronto para ser usado com uma transcrição. Execute o comando para visualizar o status atual do vocabulário personalizado:
aws transcribe get-vocabulary \ --vocabulary-namemy-first-vocabulary
Este exemplo usa o AWS SDK for Python (Boto3) para criar um vocabulário personalizado a partir de uma tabela usando o método create_vocabularyCreateVocabulary.
Para usar um vocabulário personalizado existente em um trabalho de transcrição, defina o VocabularyName no Settingscampo ao chamar a StartTranscriptionJoboperação ou, a partir do AWS Management Console, escolha o vocabulário personalizado na lista suspensa.
Para obter exemplos adicionais de uso do AWS SDKs, incluindo exemplos específicos de recursos, cenários e entre serviços, consulte o capítulo. Exemplos de código para o Amazon Transcribe usando AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') vocab_name = "my-first-vocabulary" response = transcribe.create_vocabulary( LanguageCode = 'en-US', VocabularyName = vocab_name, VocabularyFileUri = 's3://amzn-s3-demo-bucket/my-vocabularies/my-vocabulary-table.txt' ) while True: status = transcribe.get_vocabulary(VocabularyName = vocab_name) if status['VocabularyState'] in ['READY', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
nota
Se você criar um novo Amazon S3 bucket para seus arquivos de vocabulário personalizados, certifique-se de que a IAM função que faz a CreateVocabularysolicitação tenha permissões para acessar esse bucket. Se o perfil não tiver as permissões corretas, sua solicitação falhará. Opcionalmente, você pode especificar uma IAM função em sua solicitação incluindo o DataAccessRoleArn parâmetro. Para obter mais informações sobre IAM funções e políticas em Amazon Transcribe, consulteAmazon Transcribe exemplos de políticas baseadas em identidade.
