As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Opções de recuperação de desastres na nuvem
As estratégias de recuperação de desastres disponíveis para você na AWS podem ser amplamente categorizadas em quatro abordagens, desde o baixo custo e a baixa complexidade de fazer backups até estratégias mais complexas usando várias regiões ativas. As estratégias ativas/passivas usam um site ativo (como uma região da AWS) para hospedar a carga de trabalho e fornecer tráfego. O site passivo (como uma região diferente da AWS) é usado para recuperação. O site passivo não fornece tráfego ativamente até que um evento de failover seja acionado.
É fundamental avaliar e testar regularmente sua estratégia de recuperação de desastres para que você tenha confiança em invocá-la, caso seja necessário. Use o AWS Resilience Hub
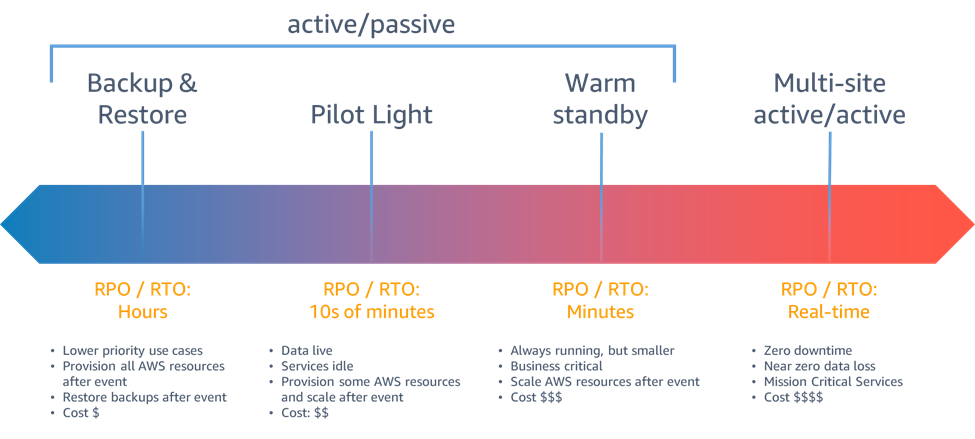
Figura 6 - Estratégias de recuperação de desastres
Para um evento de desastre baseado na interrupção ou perda de um data center físico para uma carga de trabalho bem arquitetada
Ao escolher sua estratégia e os recursos da AWS para implementá-la, lembre-se de que, dentro da AWS, geralmente dividimos os serviços no plano de dados e no plano de controle. O plano de dados é responsável por prestar serviço em tempo real, enquanto os ambientes de gerenciamento são usados para configurar o ambiente. Para máxima resiliência, você deve usar somente operações de plano de dados como parte de sua operação de failover. Isso ocorre porque os planos de dados normalmente têm metas de projeto de maior disponibilidade do que os planos de controle.
Backup e restauração
O backup e a restauração são uma abordagem adequada para mitigar a perda ou a corrupção de dados. Essa abordagem também pode ser usada para mitigar um desastre regional replicando dados para outras regiões da AWS ou para mitigar a falta de redundância para cargas de trabalho implantadas em uma única zona de disponibilidade. Além dos dados, você deve reimplantar a infraestrutura, a configuração e o código do aplicativo na região de recuperação. Para permitir que a infraestrutura seja reimplantada rapidamente sem erros, você deve sempre implantar usando a infraestrutura como código (IaC) usando serviços como AWS CloudFormation
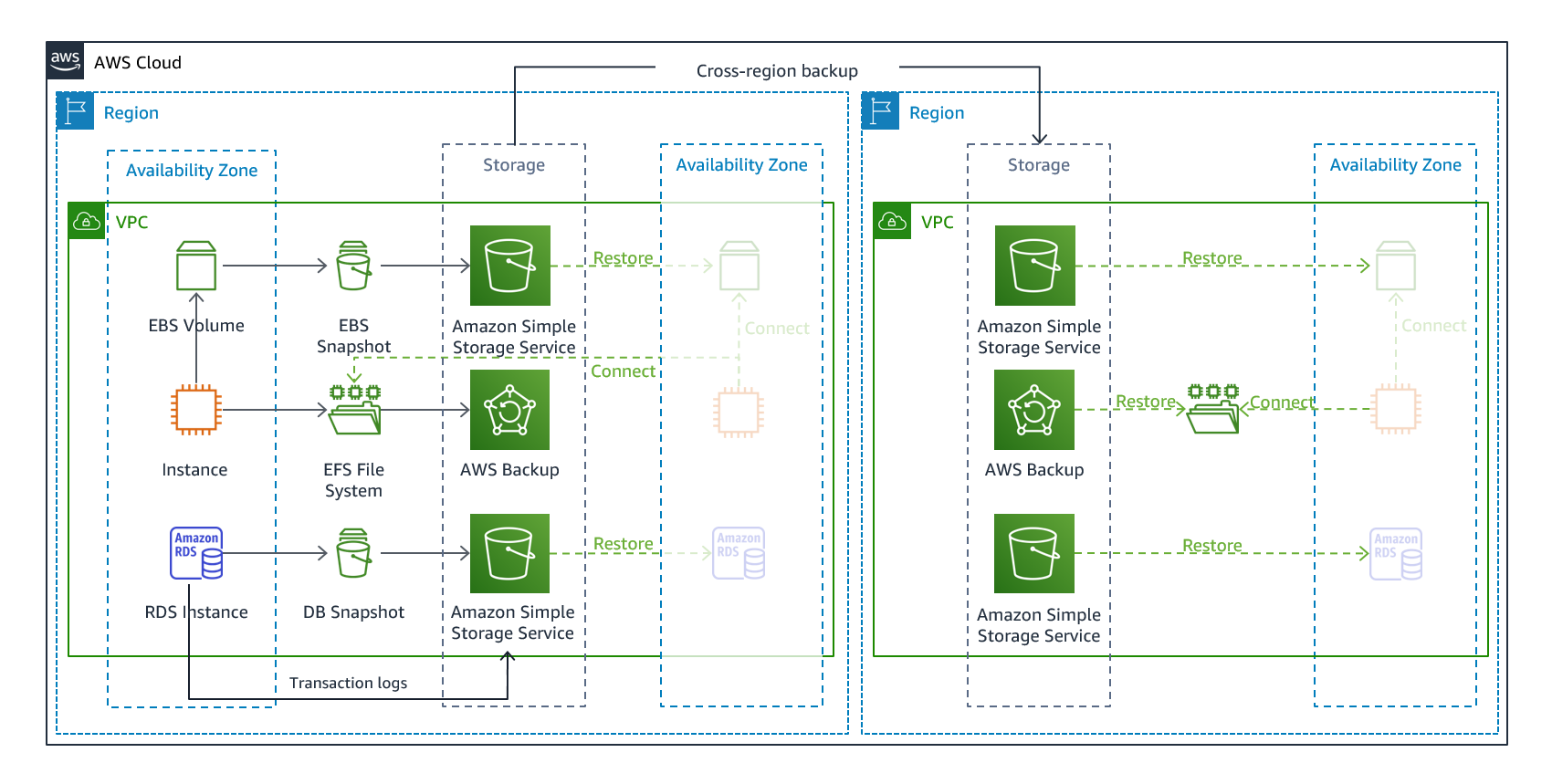
Figura 7 - Arquitetura de backup e restauração
Serviços da AWS
Seus dados de carga de trabalho exigirão uma estratégia de backup que seja executada periodicamente ou contínua. A frequência com que você executa o backup determinará seu ponto de recuperação alcançável (que deve se alinhar para atender ao seu RPO). O backup também deve oferecer uma maneira de restaurá-lo até o momento em que foi feito. O backup com point-in-time recuperação está disponível por meio dos seguintes serviços e recursos:
-
Backup do Amazon EFS (ao usar AWS Backup)
-
Amazon FSx para Windows File Server, Amazon FSx para Lustre, Amazon FSx para NetApp ONTAP e Amazon FSx para OpenZFS
Para o Amazon Simple Storage Service (Amazon S3), você pode usar o Amazon S3 Cross-Region Replication (CRR) para copiar objetos de forma assíncrona para um bucket do S3 na região de DR
AWS Backup
-
EC2Instâncias da Amazon
-
Bancos de dados Amazon Relational Database Service (Amazon RDS
) (incluindo bancos de dados Amazon Aurora ) -
Sistemas de arquivos Amazon Elastic File System (Amazon EFS)
-
Volumes do AWS Storage Gateway
-
Amazon FSx para Windows File Server, Amazon FSx para Lustre, Amazon FSx para NetApp ONTAP e Amazon FSx para OpenZFS
AWS Backup suporta a cópia de backups entre regiões, como para uma região de recuperação de desastres.
Como uma estratégia adicional de recuperação de desastres para seus dados do Amazon S3, habilite o controle de versão de objetos do S3. O controle de versão de objetos protege seus dados no S3 das consequências das ações de exclusão ou modificação, mantendo a versão original antes da ação. O controle de versão de objetos pode ser uma mitigação útil para desastres do tipo erro humano. Se você estiver usando a replicação do S3 para fazer backup de dados na sua região de DR, então, por padrão, quando um objeto é excluído no bucket de origem, o Amazon S3 adiciona um marcador de exclusão somente no bucket de origem. Essa abordagem protege os dados na região de DR contra exclusões maliciosas na região de origem.
Além dos dados, você também deve fazer backup da configuração e da infraestrutura necessárias para reimplantar sua carga de trabalho e atingir seu objetivo de tempo de recuperação (RTO). AWS CloudFormation
Todos os dados armazenados na região de recuperação de desastres como backups devem ser restaurados no momento do failover. AWS Backup oferece capacidade de restauração, mas atualmente não permite a restauração programada ou automática. Você pode implementar a restauração automática na região de DR usando o AWS SDK APIs para AWS Backup solicitar. Você pode configurar isso como um trabalho recorrente regular ou acionar a restauração sempre que um backup for concluído. A figura a seguir mostra um exemplo de restauração automática usando o Amazon Simple Notification Service (Amazon AWS Lambda
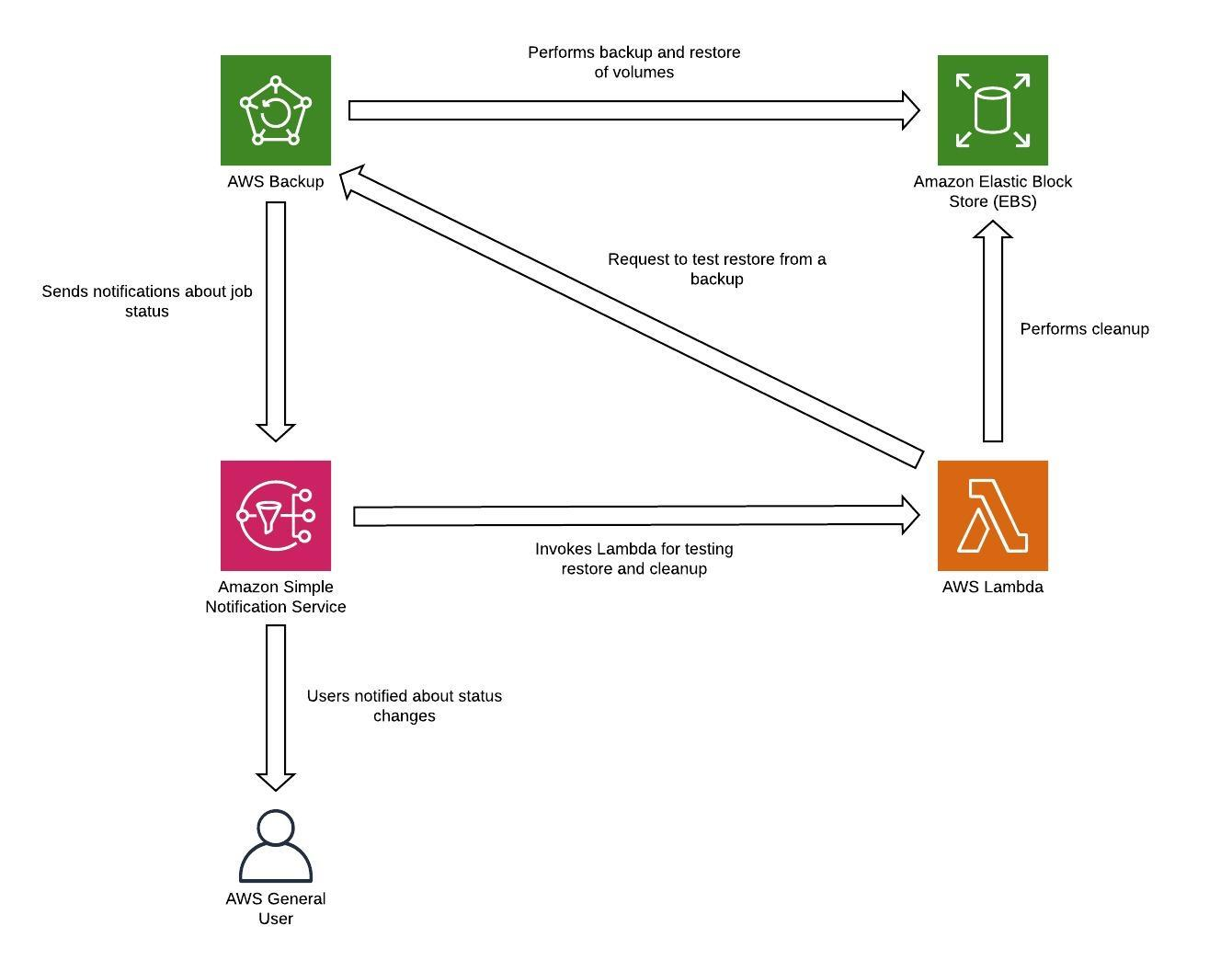
Figura 8 - Restaurando e testando backups
nota
Sua estratégia de backup deve incluir o teste dos backups. Consulte a seção Testando a recuperação de desastres para obter mais informações. Consulte o AWS Well-Architected Lab: Testando o Backup and Restore of
Luz piloto
Com a abordagem piloto leve, você replica seus dados de uma região para outra e provisiona uma cópia da sua infraestrutura principal de carga de trabalho. Os recursos necessários para permitir a replicação e o backup, como bancos de dados e armazenamento de objetos, estão sempre ativos. Outros elementos, como servidores de aplicativos, são carregados com o código e as configurações do aplicativo, mas são “desligados” e são usados somente durante testes ou quando o failover de recuperação de desastres é invocado. Na nuvem, você tem a flexibilidade de desprovisionar recursos quando não precisar deles e provisioná-los quando precisar. Uma prática recomendada para “desligado” é não implantar o recurso e, em seguida, criar a configuração e os recursos para implantá-lo (“ativar”) quando necessário. Diferentemente da abordagem de backup e restauração, sua infraestrutura principal está sempre disponível e você sempre tem a opção de provisionar rapidamente um ambiente de produção em grande escala ativando e expandindo seus servidores de aplicativos.
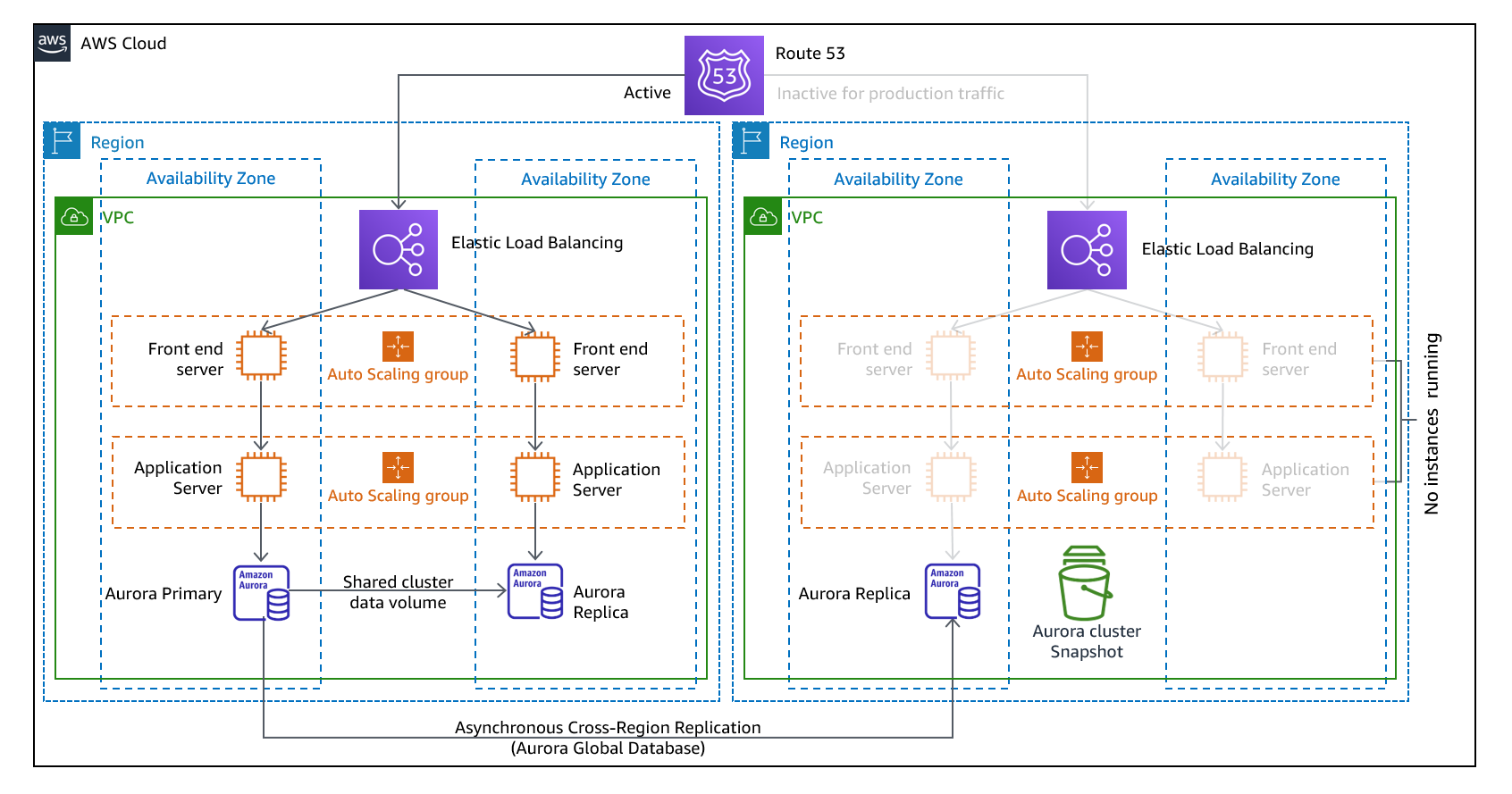
Figura 9: Arquitetura da luz piloto
Uma abordagem piloto leve minimiza o custo contínuo da recuperação de desastres ao minimizar os recursos ativos e simplifica a recuperação no momento de um desastre, pois os principais requisitos de infraestrutura estão todos prontos. Essa opção de recuperação exige que você altere sua abordagem de implantação. Você precisa fazer alterações na infraestrutura principal em cada região e implantar alterações na carga de trabalho (configuração, código) simultaneamente em cada região. Essa etapa pode ser simplificada automatizando suas implantações e usando a infraestrutura como código (IaC) para implantar a infraestrutura em várias contas e regiões (implantação completa da infraestrutura na região primária e implantação de infraestrutura reduzida/desativada nas regiões de DR). É recomendável usar uma conta diferente por região para fornecer o mais alto nível de isolamento de recursos e segurança (no caso de credenciais comprometidas também fazerem parte de seus planos de recuperação de desastres).
Com essa abordagem, você também deve evitar um desastre de dados. A replicação contínua de dados protege você contra alguns tipos de desastres, mas pode não protegê-lo contra corrupção ou destruição de dados, a menos que sua estratégia também inclua o controle de versões dos dados armazenados ou opções de recuperação. point-in-time Você pode fazer backup dos dados replicados na região do desastre para criar point-in-time backups nessa mesma região.
Serviços da AWS
Além de usar os serviços da AWS abordados na seção Backup e restauração para criar point-in-time backups, considere também os seguintes serviços para sua estratégia piloto.
Para fins piloto, a replicação contínua de dados em bancos de dados ativos e armazenamentos de dados na região de DR é a melhor abordagem para baixo RPO (quando usada em adição aos point-in-time backups discutidos anteriormente). A AWS fornece replicação de dados assíncrona, contínua e entre regiões para dados usando os seguintes serviços e recursos:
Com a replicação contínua, as versões de seus dados estão disponíveis quase imediatamente em sua região de DR. Os tempos reais de replicação podem ser monitorados usando recursos de serviço como o S3 Replication Time Control (S3 RTC) para objetos do S3 e recursos de gerenciamento dos bancos de dados globais Amazon Aurora.
Ao fazer o failover para executar sua carga de trabalho de leitura/gravação na região de recuperação de desastres, você deve promover uma réplica de leitura do RDS para se tornar a instância primária. Para instâncias de banco de dados diferentes do Aurora, o processo leva alguns minutos para ser concluído e a reinicialização faz parte do processo. Para replicação entre regiões (CRR) e failover com o RDS, o uso do banco de dados global Amazon Aurora oferece várias vantagens. O banco de dados global usa uma infraestrutura dedicada que deixa seus bancos de dados totalmente disponíveis para atender seu aplicativo e pode ser replicado para a região secundária com latência típica de menos de um segundo (e dentro de uma região da AWS é muito menos de 100 milissegundos). Com o banco de dados global Amazon Aurora, se sua região principal sofrer uma degradação de desempenho ou uma interrupção, você pode promover que uma das regiões secundárias assuma responsabilidades de leitura/gravação em menos de um minuto, mesmo no caso de uma interrupção regional completa. Você também pode configurar o Aurora para monitorar o tempo de atraso do RPO de todos os clusters secundários para garantir que pelo menos um cluster secundário permaneça dentro da janela de RPO de destino.
Uma versão reduzida de sua infraestrutura principal de carga de trabalho com menos ou menos recursos deve ser implantada em sua região de DR. Usando AWS CloudFormation, você pode definir sua infraestrutura e implantá-la de forma consistente em todas as contas da AWS e em todas as regiões da AWS. AWS CloudFormation usa pseudoparâmetros predefinidos para identificar a conta da AWS e a região da AWS na qual ela está implantada. Portanto, você pode implementar a lógica de condição em seus CloudFormation modelos para implantar somente a versão reduzida de sua infraestrutura na região de DR. Por EC2 exemplo, implantações, uma Amazon Machine Image (AMI) fornece informações como configuração de hardware e software instalado. Você pode implementar um pipeline do Image Builder que cria o que AMIs você precisa e copiá-lo para suas regiões primária e de backup. Isso ajuda a garantir que esses dourados AMIs tenham tudo o que você precisa para reimplantar ou expandir sua carga de trabalho em uma nova região, no caso de um evento de desastre. As EC2 instâncias da Amazon são implantadas em uma configuração reduzida (menos instâncias do que na sua região principal). Para expandir a infraestrutura para suportar o tráfego de produção, consulte Amazon Auto EC2 Scaling na seção Warm Standby.
Para uma configuração ativa/passiva, como luz piloto, todo o tráfego vai inicialmente para a região principal e muda para a região de recuperação de desastres se a região primária não estiver mais disponível. Essa operação de failover pode ser iniciada de forma manual ou automática. O failover iniciado automaticamente com base em verificações de saúde ou alarmes deve ser usado com cautela. Mesmo usando as melhores práticas discutidas aqui, o tempo de recuperação e o ponto de recuperação serão maiores que zero, incorrendo em alguma perda de disponibilidade e de dados. Se você falhar quando não precisar (alarme falso), você incorrerá nessas perdas. Portanto, o failover iniciado manualmente é usado com frequência. Nesse caso, você ainda deve automatizar as etapas para failover para que a inicialização manual ocorra com o apertar um botão.
Há várias opções de gerenciamento de tráfego a serem consideradas ao usar AWS os serviços.
Uma opção é usar o Amazon Route 53
Outra opção é usar AWS Global Accelerator
A Amazon CloudFront
AWS Recuperação flexível de desastres
AWS O Elastic Disaster Recovery

Figura 10 - Arquitetura AWS elástica de recuperação de desastres
Standby passivo
A abordagem de standby passivo envolve garantir que haja uma cópia reduzida, mas totalmente funcional, do seu ambiente de produção em outra região. Essa abordagem estende o conceito de luz piloto e diminui o tempo de recuperação, já que a workload está sempre ativa em outra região. Essa abordagem também permite que você realize testes ou implemente testes contínuos com mais facilidade para aumentar a confiança em sua capacidade de se recuperar de um desastre.
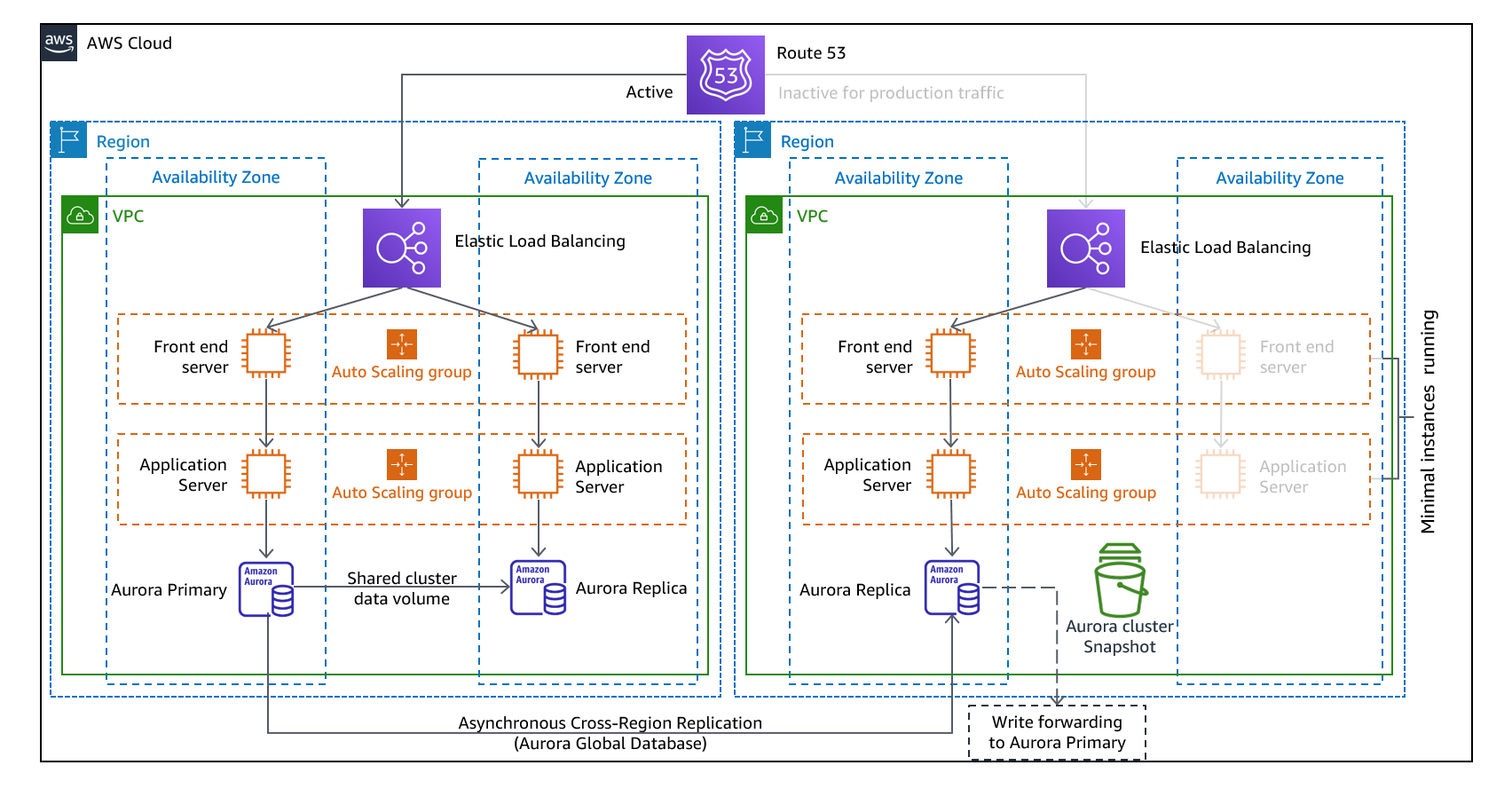
Figura 11 - Arquitetura de espera quente
Nota: Às vezes, a diferença entre a luz piloto e a espera quente pode ser difícil de entender. Ambos incluem um ambiente em sua região de DR com cópias dos ativos de sua região principal. A diferença é que a luz piloto não pode processar solicitações sem que uma ação adicional seja tomada primeiro, enquanto o modo de espera aquecido pode lidar com o tráfego (em níveis de capacidade reduzidos) imediatamente. A abordagem piloto exige que você “ligue” os servidores, possivelmente implante uma infraestrutura adicional (não essencial) e aumente a escala, enquanto o modo de espera aquecido exige apenas que você aumente a escala (tudo já está implantado e em execução). Use suas necessidades de RTO e RPO para ajudá-lo a escolher entre essas abordagens.
Serviços da AWS
Todos os serviços da AWS cobertos por backup e restauração e piloto também são usados em espera quente para backup de dados, replicação de dados, roteamento de tráfego ativo/passivo e implantação de infraestrutura, incluindo instâncias. EC2
O Amazon EC2 Auto Scaling é usado para escalar
Como o Auto Scaling é uma atividade do plano de controle, depender dela diminuirá a resiliência de sua estratégia geral de recuperação. É uma troca. Você pode optar por provisionar capacidade suficiente para que a região de recuperação possa lidar com toda a carga de produção conforme implantada. Essa configuração estaticamente estável é chamada de hot standby (consulte a próxima seção). Ou você pode optar por provisionar menos recursos, o que custará menos, mas depender do Auto Scaling. Algumas implementações de DR implantarão recursos suficientes para lidar com o tráfego inicial, garantindo um baixo RTO e, em seguida, confiarão no Auto Scaling para acelerar o tráfego subsequente.
Multissite ativa/ativa
Você pode executar sua carga de trabalho simultaneamente em várias regiões como parte de uma estratégia ativa/ativa de vários sites ou ativa/passiva em espera ativa. Vários sites. active/active serves traffic from all regions to which it is deployed, whereas hot standby serves traffic only from a single region, and the other Region(s) are only used for disaster recovery. With a multi-site active/active approach, users are able to access your workload in any of the Regions in which it is deployed. This approach is the most complex and costly approach to disaster recovery, but it can reduce your recovery time to near zero for most disasters with the correct technology choices and implementation (however data corruption may need to rely on backups, which usually results in a non-zero recovery point). Hot standby uses an active/passive configuration where users are only directed to a single region and DR regions do not take traffic. Most customers find that if they are going to stand up a full environment in the second Region, it makes sense to use it active/active Como alternativa, se você não quiser usar as duas regiões para lidar com o tráfego de usuários, o Warm Standby oferece uma abordagem mais econômica e operacionalmente menos complexa.
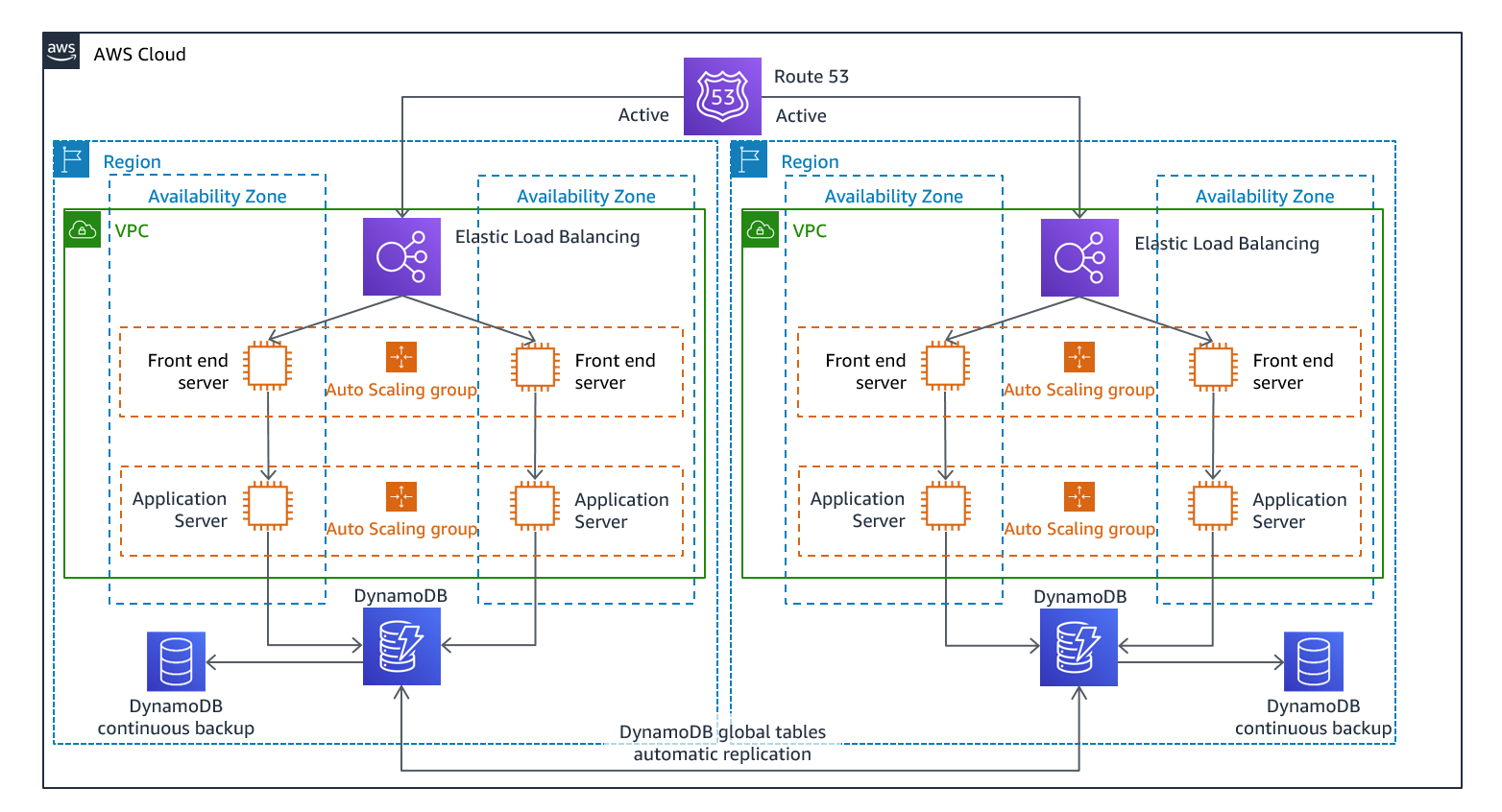
Figura 12 - Arquitetura ativa/ativa de vários sites (altere um caminho ativo para inativo para hot standby)
Com a necessidade de uma abordagem de vários locais active/active, because the workload is running in more than one Region, there is no such thing as failover in this scenario. Disaster recovery testing in this case would focus on how the workload reacts to loss of a Region: Is traffic routed away from the failed Region? Can the other Region(s) handle all the traffic? Testing for a data disaster is also required. Backup and recovery are still required and should be tested regularly. It should also be noted that recovery times for a data disaster involving data corruption, deletion, or obfuscation will always be greater than zero and the recovery point will always be at some point before the disaster was discovered. If the additional complexity and cost of a multi-site active/active (ou de espera ativa) para manter tempos de recuperação quase nulos, esforços adicionais devem ser feitos para manter a segurança e evitar erros humanos para mitigar os desastres humanos.
Serviços da AWS
Todos os serviços da AWS cobertos por backup e restauração, iluminação piloto e espera quente também são usados aqui para backup de dados, replicação de point-in-time dados, roteamento de tráfego ativo/ativo e implantação e escalabilidade da infraestrutura, incluindo instâncias. EC2
Para os cenários ativos/passivos discutidos anteriormente (Pilot Light e Warm Standby), tanto o Amazon Route 53 quanto o Amazon AWS Global Accelerator podem ser usados para rotear o tráfego da rede para a região ativa. Para a estratégia ativa/ativa aqui, esses dois serviços também permitem a definição de políticas que determinam quais usuários acessam qual endpoint regional ativo. Com AWS Global Accelerator você define uma discagem de tráfego para controlar a porcentagem de tráfego que é direcionada para cada endpoint do aplicativo. O Amazon Route 53 suporta essa abordagem percentual e também várias outras políticas disponíveis, incluindo políticas baseadas em geoproximidade e latência. O Global Accelerator aproveita automaticamente a extensa rede de servidores de borda da AWS para integrar o tráfego ao backbone da rede da AWS o mais rápido possível, resultando em menores latências de solicitação.
A replicação assíncrona de dados com essa estratégia permite um RPO quase zero. Os serviços da AWS, como o banco de dados global Amazon Aurora, usam uma infraestrutura dedicada que deixa seus bancos de dados totalmente disponíveis para atender seu aplicativo e podem ser replicados em até cinco regiões secundárias com latência típica de menos de um segundo. With active/passive strategies, writes occur only to the primary Region. The difference with active/active está projetando como a consistência dos dados com gravações em cada região ativa é tratada. É comum projetar leituras de usuários para serem atendidas na região mais próxima a eles, conhecida como leitura local. Com as gravações, você tem várias opções:
-
Uma estratégia global de gravação direciona todas as gravações para uma única região. Em caso de falha dessa região, outra região seria promovida a aceitar escritos. O banco de dados global Aurora é uma boa opção para gravação global, pois oferece suporte à sincronização com réplicas de leitura em todas as regiões, e você pode promover uma das regiões secundárias para assumir responsabilidades de leitura/gravação em menos de um minuto. O Aurora também oferece suporte ao encaminhamento de gravação, o que permite que clusters secundários em um banco de dados global do Aurora encaminhem instruções SQL que realizam operações de gravação no cluster primário.
-
Uma estratégia local de gravação direciona as gravações para a região mais próxima (assim como as leituras). As tabelas globais do Amazon DynamoDB possibilitam essa estratégia, permitindo leitura e gravação de todas as regiões em que sua tabela global está implantada. As tabelas globais do Amazon DynamoDB usam um último escritor para vencer a reconciliação entre atualizações simultâneas.
-
Uma estratégia de gravação particionada atribui gravações a uma região específica com base em uma chave de partição (como ID de usuário) para evitar conflitos de gravação. A replicação do Amazon S3 configurada bidirecionalmente
pode ser usada para esse caso e atualmente oferece suporte à replicação entre duas regiões. Ao implementar essa abordagem, certifique-se de ativar a sincronização de modificação da réplica nos buckets A e B para replicar as alterações dos metadados da réplica, como listas de controle de acesso a objetos (ACLs), tags de objetos ou bloqueios de objetos nos objetos replicados. Você também pode configurar se deseja ou não replicar marcadores de exclusão entre buckets em suas regiões ativas. Além da replicação, sua estratégia também deve incluir point-in-time backups para se proteger contra eventos de corrupção ou destruição de dados.
AWS CloudFormation é uma ferramenta poderosa para aplicar a infraestrutura implantada de forma consistente entre contas da AWS em várias regiões da AWS. AWS CloudFormation StackSetsamplia essa funcionalidade ao permitir que você crie, atualize ou exclua CloudFormation pilhas em várias contas e regiões com uma única operação. Embora AWS CloudFormation use YAML ou JSON para definir infraestrutura como código, AWS Cloud Development Kit (AWS CDK)
