This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Understanding availability
Availability is one of the primary ways we can quantitatively measure resiliency. We define availability, A, as the percentage of time that a workload is available for use. It’s a ratio of its expected “uptime” (being available) to the total time being measured (the expected “uptime” plus the expected “downtime”).

Equation 1 - Availability
To better understand this formula, we’ll look at how to measure uptime and downtime. First, we want to know how long the workload will go without failure. We call this mean time between failure (MTBF), the average time between when a workload begins normal operation and its next failure. Then, we want to know how long it will take to recover after it has failed.
We call this mean time to repair (or recovery) (MTTR), a period of time when the workload is unavailable while the failed subsystem is repaired or returned to service. An important period of time in the MTTR is the mean time to detection (MTTD), the amount of time between a failure occurring and when repair operations begin. The following diagram demonstrates how all of these metrics are related.

The relationship between MTTD, MTTR, and MTBF
We can thus express availability, A, using MTBF, the time the workload is up, and MTTR, the time the workload is down.

Equation 2 - Relationship between MTBF and MTTR
And the probability the workload is “down” (that is, not available) is the probability of failure, F.
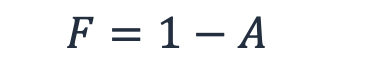
Equation 3 - Probability of failure
Reliability is the ability of a workload to do the right thing, when requested, within the specified response time. This is what availability measures. Having a workload fail less frequently (longer MTBF) or having a shorter repair time (shorter MTTR) improves its availability.
Rule 1
Less frequent failure (longer MTBF), shorter failure detection times (shorter MTTD), and shorter repair times (shorter MTTR) are the three factors that are used to improve availability in distributed systems.
Topics
