本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
按需配置驱动程序
要使用按需驱动程序,必须对其进行配置。只有在 su pplementary _time_series 数据实体中提取数据后,才能配置需求驱动因素。
注意
如果您未配置需求驱动因素,您仍然可以生成预测。但是,需求计划不会使用需求驱动因素。
需求驱动因素数据填充方法
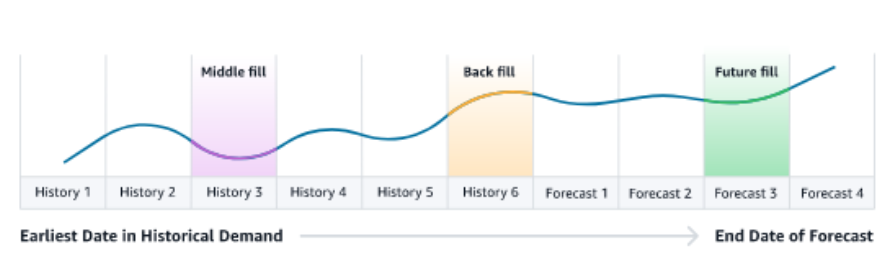
填充方法表示(或 “填充”)时间序列中的缺失值。需求计划支持以下填充方法。需求计划应用的填充方法取决于数据中缺口的位置。
-
回填—当产品较早的记录日期和上次记录的日期之间存在差距时适用。
-
中间填充 — 当给定产品的最后记录数据点与全球上次记录的日期之间存在间隙时应用。
-
未来填充 — 当需求驱动因素在未来至少有一个数据点并且在未来的时间范围内存在缺口时适用。
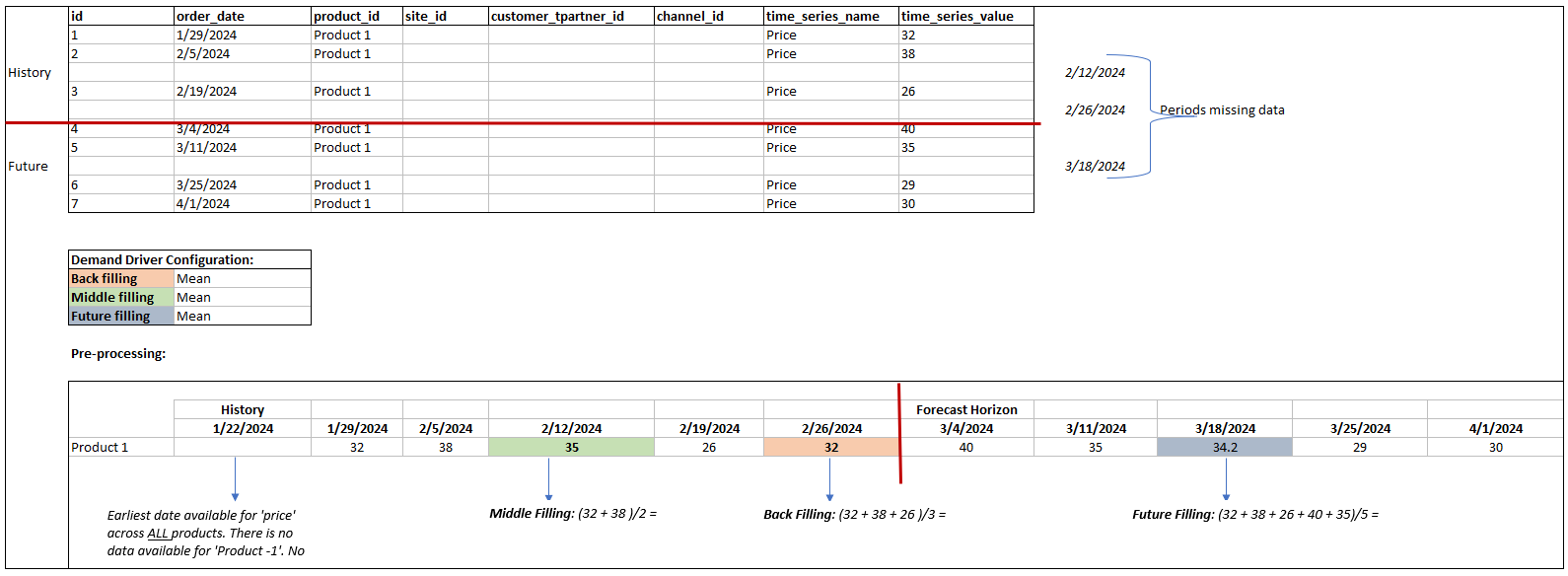
需求计划利用与需求驱动因素相对应的 su pplementary_time_series 数据实体中的最后 64 个数据点进行考虑。需求计划支持所有三种填充方法的零、中位数、平均值、最大值和最小值选项。
以下示例说明了当将数据提取到产品 1 的 su pplementary_time_serie s 数据实体(包括历史数据和未来数据)的价格列时,需求驱动因素如何处理缺失的数据。
聚合方法
Demand Planning 使用汇总方法,通过合并特定时间段和粒度级别的数据,促进不同粒度级别的需求驱动因素的集成。
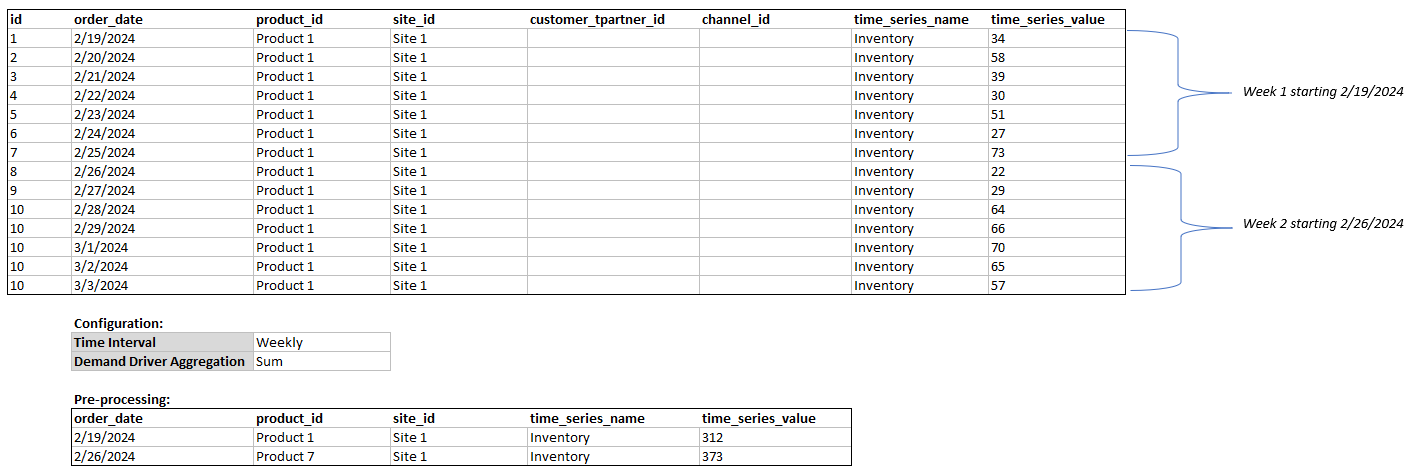
时间段汇总-例如,当库存需求驱动因素在每日层面可用,但预测为每周层面时,需求计划将应用在库存需求计划设置下配置的汇总方法来使用这些信息进行预测。
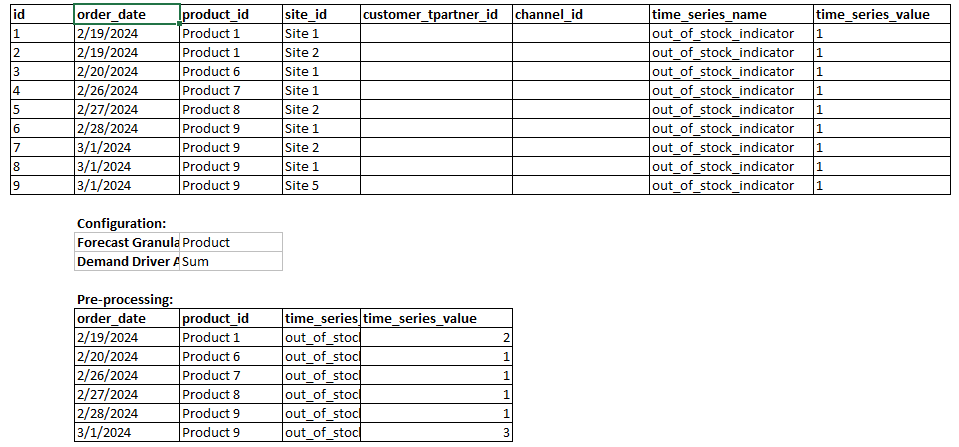
粒度级别汇总 — 以下是需求计划如何使用粒度级别聚合的示例。 out_of_stock_indicat or 每天在产品站点层面提供,但预测粒度仅在产品层面可用。需求计划将应用在该需求动因的需求计划设置下配置的汇总方法。