本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
数组作业
数组作业是共享通用参数 (如作业定义、vCPU 和内存) 的作业。它会以一系列相关但独立的基本作业的形式运行,这些作业可能跨多个主机分布,而且可能同时运行。数组作业是运行高度并行作业 (如 Monte Carlo 模拟、参数扫描或大型渲染作业) 的最高效方式。
AWS Batch 阵列作业的提交方式与普通作业一样。但是,您可以指定一个数组大小 (介于 2 和 10000 之间) 来定义该数组中应运行的子作业数。如果您提交一个数组大小为 1000 的作业,则单个作业会运行并生成 1000 个子作业。该数组作业是用于管理所有子作业的参考或指针。这种方式将允许您使用单个查询提交大型工作负载。attemptDurationSeconds 参数中指定的超时适用于每个子作业。父阵列作业没有超时。
当您提交阵列作业时,父阵列作业将获得一个普通的 AWS Batch 作业 ID。每个子作业都有相同的基本 ID。但是,子作业的数组索引将附加到父 ID 的末尾,如数组的首个子作业的 example_job_ID:0
父阵列作业可以输入 SUBMITTED、PENDING、FAILED 或 SUCCEEDED 状态。当任何子作业更新为 RUNNABLE时,阵列父作业将更新为 PENDING。有关作业依赖关系的更多信息,请参阅 作业依赖项。
在运行时,AWS_BATCH_JOB_ARRAY_INDEX 环境变量将设置为容器的相应作业数组索引编号。第一个数组作业索引的编号为 0,后续尝试的编号按升序排列 (1、2、3,依此类推)。您可以使用此索引值来控制数组作业子级的差异。有关更多信息,请参阅 使用数组作业索引控制作业差异化。
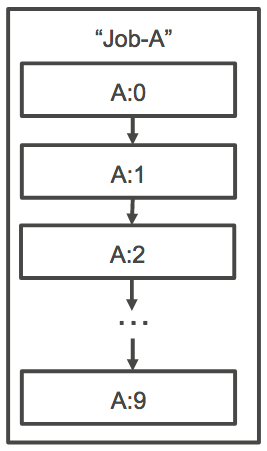
对于数组作业依赖项,您可以为依赖项指定一种类型,如 SEQUENTIAL 或 N_TO_N。您可以指定 SEQUENTIAL 类型依赖项 (无需指定作业 ID),以便每个子数组作业按顺序完成 (从索引 0 开始)。例如,如果您提交一个数组大小为 100 的数组作业,并指定类型为 SEQUENTIAL 的依赖项,则会按顺序生成 100 个子作业,其中,首个子作业必须先成功,然后才能开始下一个子作业。下图显示作业 A,它是一个数组大小为 10 的数组作业。作业 A 的子索引中的每个作业均依赖于其前一个子作业。在作业 A:0 完成之前,Job A:1 无法启动。
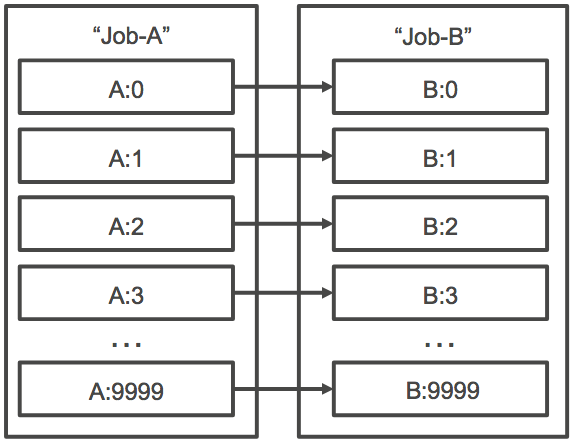
您也可以指定 N_TO_N 类型依赖项,并指定数组任务的任务 ID 。这样一来,此作业的每个子索引必须等待每个依赖项的相应子索引完成后才能开始。下图显示作业 A 和作业 B,二者是数组大小均为 10,000 的数组作业。作业 B 的子索引中的每个作业都依赖于作业 A 中的相应索引。在作业 A:1 完成之前,作业 B:1 无法启动。
如果您取消或终止父数组作业,则其所有子作业将随它一起取消或终止。您可以取消或终止单个子作业(这会将它们迁移至 FAILED 状态),而不会影响其他子作业。但是,如果子数组作业失败(自行或通过手动取消或终止作业),则父作业也会失败。在这种情况下,父作业会在所有子作业完成时转换为 FAILED。
有关搜索和筛选阵列作业的更多信息,请参阅搜索作业队列中的作业。
