本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
训练您的第一个 AWS DeepRacer 模型
本演练演示了如何使用 AWS DeepRacer 控制台训练您的第一个模型。
使用 AWS DeepRacer 控制台训练强化学习模型
了解如何在 AWS DeepRacer 控制台中找到 创建模型按钮,开始您的模型训练之旅。
使用 AWS DeepRacer 控制台训练强化学习模型
-
如果这是您首次使用 AWS DeepRacer,请从服务登录页面选择 创建模型或在主导航窗格的 强化学习标题下选择开始。
-
在 开始强化学习 页面上的 步骤 2: 创建模型和赛事 下,选择 创建模型。
或者,在主导航窗格的 强化学习标题下选择 您的模型。在 Your models (您的模型) 页面上,选择 Create model (创建模型)。
指定模型名称和环境
为您的模型命名并学习如何选择适合您的仿真赛道。
指定模型名称和环境
-
在 创建模型 页面中,在 训练详情 输入模型的名称。
-
或者,添加训练作业描述。
-
要了解有关其他选项的更多信息,请参阅标记。
-
在 环境模拟下,选择一个赛道作为您的 AWS DeepRacer 代理的训练环境。在 赛道方向下,选择 顺时针或逆时针。然后选择下一步。
第一次运行时,请选择具有简单形状和平滑转弯的赛道。在以后的迭代中,您可以选择更复杂的赛道来逐步改进模型。要为特定赛车活动训练模型,请选择最类似于活动赛道的赛道。
-
在页面底部,选择 下一步。
选择比赛类型和训练算法
AWS DeepRacer 控制台有三种比赛类型和两种训练算法可供选择。了解哪些适合您的技能水平和训练目标。
选择比赛类型和训练算法
-
在 创建模型页面的上的 比赛类型下,选择 计时赛、避开物体和 人机比赛。
对于您的首轮比赛,我们建议您选择 计时赛。有关针对此比赛类型优化代理传感器配置的指导,请参阅为计时赛定制 AWS DeepRacer 训练。
-
(可选)后续运行时,可选择 避障赛,以绕过沿选定赛道放置在固定或随机位置的静止障碍物。有关更多信息,请参阅为避障赛定制 AWS DeepRacer 训练。
-
选择 固定位置以在赛道的两条车道上用户指定的固定位置生成方框,或者选择 随机位置以生成在每次训练模拟开始时随机分布在两条车道上的物体。
-
接下来,为 赛道上的物体数量选择一个值。
-
如果选择 固定位置,则可以调整每个对象在赛道上的位置。对于 车道放置,请在内车道和外车道之间进行选择。默认情况下,物体在赛道上均匀分布。要更改物体起点和终点线之间的距离,请在 起点和终点之间的位置 (%)字段中输入 7 到 90 之间距离的百分比。
-
-
对于其他更具挑战性的训练,请选择 对战赛,与最多四台移动速度恒定的自动程序车辆进行比赛。要了解更多信息,请参阅 为对战赛定制 AWS DeepRacer 训练。
-
在 选择机器人车辆数量下,选择您希望代理训练多少辆机器人车辆。
-
接下来,选择您希望机器人车辆在赛道上行驶的速度(以毫米/秒为单位)。
-
或者,选中 启用车道变更复选框,让机器人车辆能够每 1-5 秒随机更改一次车道。
-
-
在训练算法和超参数下,选择 柔性动作评价 (SAC) 或 近端策略优化 (PPO)算法。在 AWS DeepRacer 控制台中,必须在持续的操作空间中训练 SAC 模型。PPO 模型可以在连续或离散的操作空间中训练。
-
在 训练算法和超参数下,按原样使用默认超参数值。
稍后,为了提高训练性能,请展开 Hyperparameters (超参数) 并按如下所示修改默认超参数值:
-
对于 Gradient descent batch size (梯度下降批大小),选择可用选项。
-
对于 Number of epochs (纪元数),设置有效值。
-
对于 Learning rate (学习速率),设置有效值。
-
对于 SAC alpha 值(仅限 SAC 算法),设置有效值。
-
对于 Entropy (熵),设置有效值。
-
对于Discount factor (折扣系数),设置有效值。
-
对于 Loss type (损耗类型),选择可用选项。
-
对于 Number of experience episodes between each policy-updating iteration (每次策略更新迭代之间的经验情节数),设置有效值。
有关超级参数的更多信息,请参阅系统性调整超级参数。
-
-
选择 下一步。
定义操作空间
在 定义操作空间页面上,如果您选择使用 SAC 算法进行训练,则您的默认操作空间为连续动作空间。如果您选择使用 PPO 算法进行训练,请在 连续操作空间和 离散操作空间之间进行选择。要详细了解每个操作空间和算法如何塑造代理的训练体验,请参阅AWS DeepRacer 操作空间和奖励函数。
-
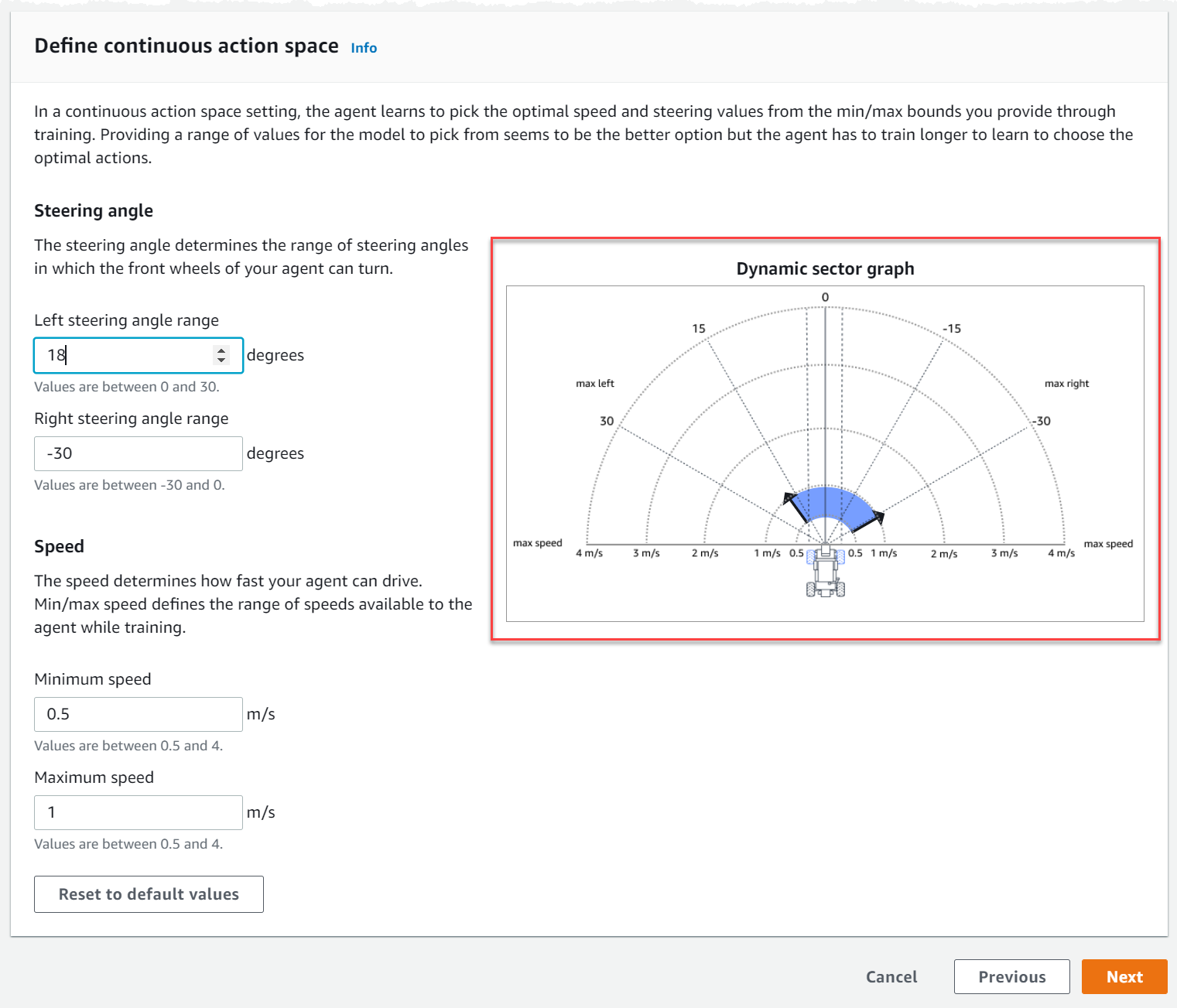
在 定义连续操作空间下,选择 左转向角度范围和 右转向角范围。
尝试为每个转向角度范围输入不同的角度,并观看范围变化的可视化,以在 动态扇形图上显示您的选择。
-
在 速度下,输入代理的最小和最大速度(以毫米/秒为单位)。
请注意您的更改是如何反映在 动态扇形图上的。
-
(可选)选择 重置为默认值以清除不需要的值。我们鼓励在图表上尝试不同的值来进行实验和学习。
-
选择 下一步。
-
从下拉列表中选择 转向角粒度的值。
-
为代理的 最大转向角选择一个介于 1-30 之间的度数值。
-
从下拉列表的 速度粒度选择一个值。
-
为代理的最大速度选择一个介于 0.1-4 之间的值(以毫米/秒为单位)。
-
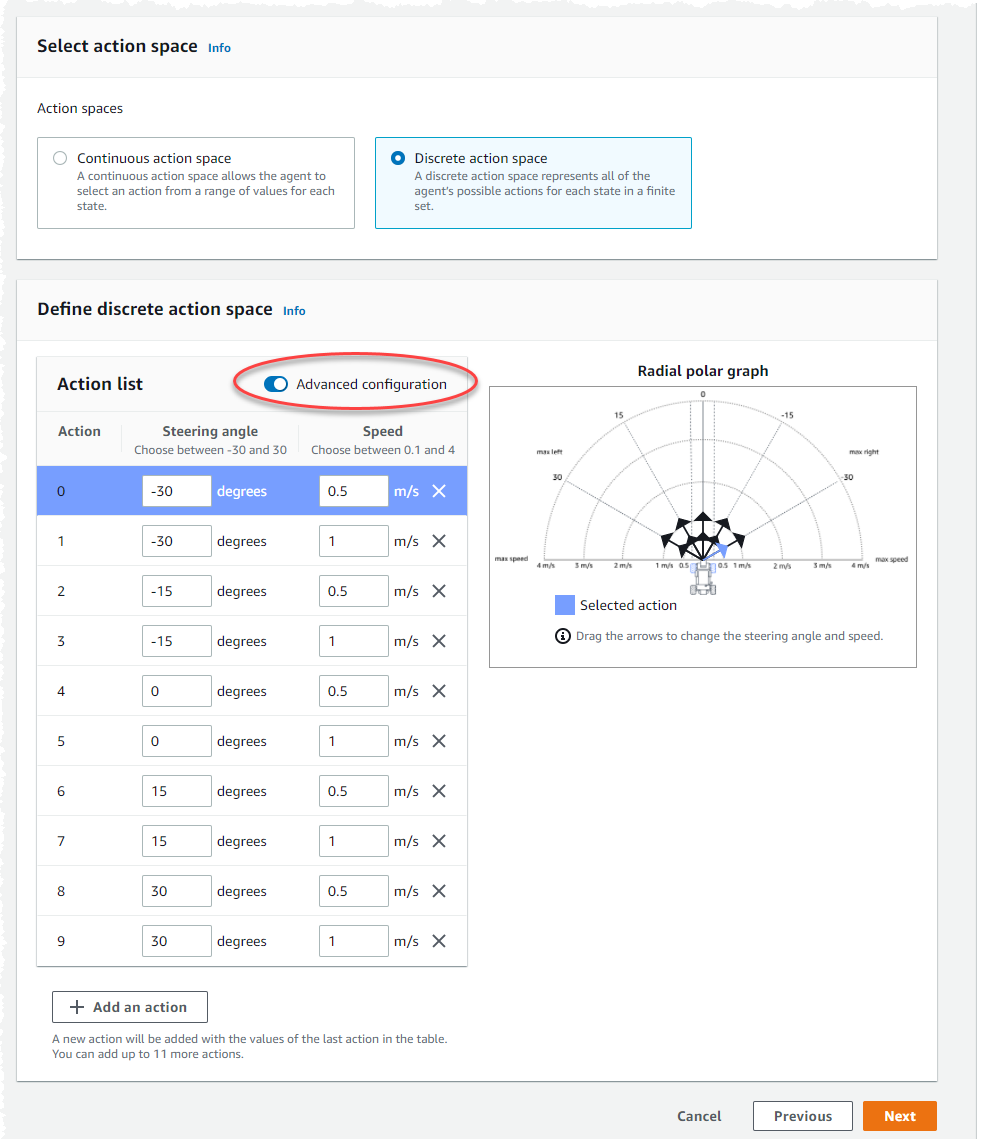
使用 动作列表中的默认动作设置,或者(可选)切换到 高级配置来微调您的设置。如果在调整值后选择 上一步或关闭 高级配置,则更改将丢失。
-
在 转向角列中输入一个介于 -30 和 30 之间的度数值。
-
在 速度列中输入一个介于 0.1 到 4 之间(以毫米/秒为单位)的值,最多可执行九个动作。
-
(可选)选择 添加动作以增加动作列表中的行数。
-
(可选)在行上选择 X 将其删除。
-
-
选择 下一步。
选择一辆模拟赛车
了解如何开始使用 。每月参加公开组比赛,赚取新的定制赛车、油漆喷涂和改装功能。
选择模拟赛车
-
在 选择车辆外壳和传感器配置页面上,选择与您的比赛类型和动作空间兼容的外壳。如果您的车库里没有匹配的赛车,请前往主导航窗格上 强化学习标题下的 您的车库来创建一辆。
对于 计时赛训练,您只需要使用原装 DeepRacer 的默认传感器配置和单镜头摄像头。只要操作空间匹配,其他所有的外壳和传感器配置就可以正常工作。有关更多信息,请参阅为计时赛定制 AWS DeepRacer 训练。
对于 避开物体训练,立体摄像机很有用,但也可以使用单个摄像头来避开固定位置的静止障碍物。LiDAR 传感器为可选件。请参阅AWS DeepRacer 操作空间和奖励函数。
对于 人机训练,除了单台摄像机或立体摄像机外,LiDAR 单元最适合用与经过其他行驶车辆时检测和避开盲点。要了解更多信息,请参阅 为对战赛定制 AWS DeepRacer 训练。
-
选择 下一步。
自定义您的奖励功能
奖励功能是强化学习的核心。学会用它来激励您的赛车(代理)在探索赛道(环境)时采取特定的行动。就像鼓励和劝阻宠物的某些行为一样,您可以使用这个工具来鼓励您的赛车尽快完成一圈,并阻止它驶出赛道或与物体碰撞。
自定义您的奖励功能
-
在Create model (创建模型) 页面上的Reward function (奖励函数) 下,按原样使用第一个模型的默认奖励函数示例。
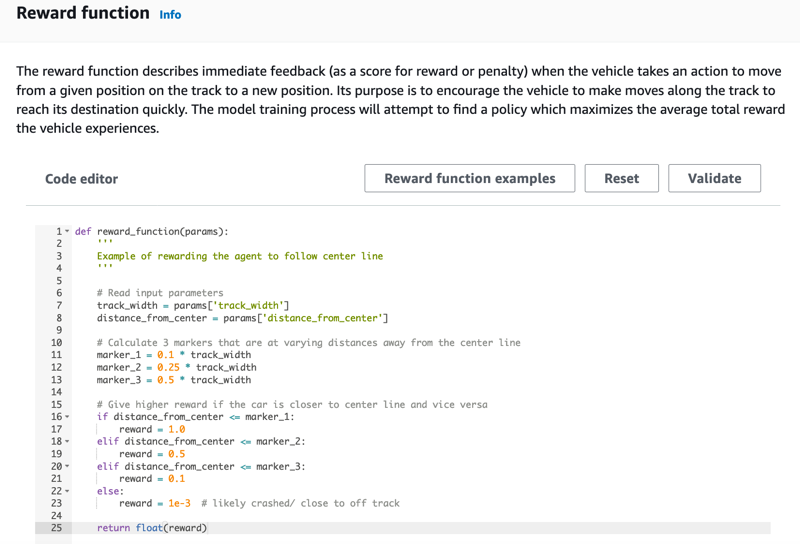
稍后,您可以通过选择 Reward function examples (奖励函数示例) 来选择另一个示例函数,然后选择 Use code (使用代码) 接受选定的奖励函数。
有四个示例函数可供您用作开始。它们说明了如何紧贴赛道中心行驶(默认)、如何确保代理停留在赛道边界内,如何防止之字形行驶以及如何避免撞向静止障碍物或其他移动车辆。
要了解有关奖励函数的更多信息,请参阅AWS DeepRacer 奖励功能参考。
-
在 停止条件 下,保留默认的 最长时间 值不变或设置终止训练作业的新值,以帮助防止长时间运行(以及可能的失控)的训练作业。
在训练的早期阶段进行试验时,您应该从此参数的较小的值开始,然后逐渐延长训练的时间。
-
在 自动提交给 AWS DeepRacer下,默认选中训练完成后自动将此模型提交给 AWS DeepRacer 并有机会赢取奖品。或者,您可以通过选择复选标记来选择不输入您的模型。
-
在 联赛要求下,选择您的 居住国家,并通过选中复选框接受条款和条件。
-
在 创建模型 页面上,选择 创建模型 以开始创建模型并预置训练作业实例。
-
提交后,等待训练作业完成初始化,然后运行。
初始化过程大约需要花费几分钟,之后作业状态会从 正在初始化 变为 进行中。
-
观看 Reward graph (奖励图) 和 Simulation video stream (模拟视频流) 以了解训练作业的进度。您可以每隔一段时间选择 Reward graph (奖励图) 旁边的刷新按钮来刷新 Reward graph (奖励图),直到训练作业完成。
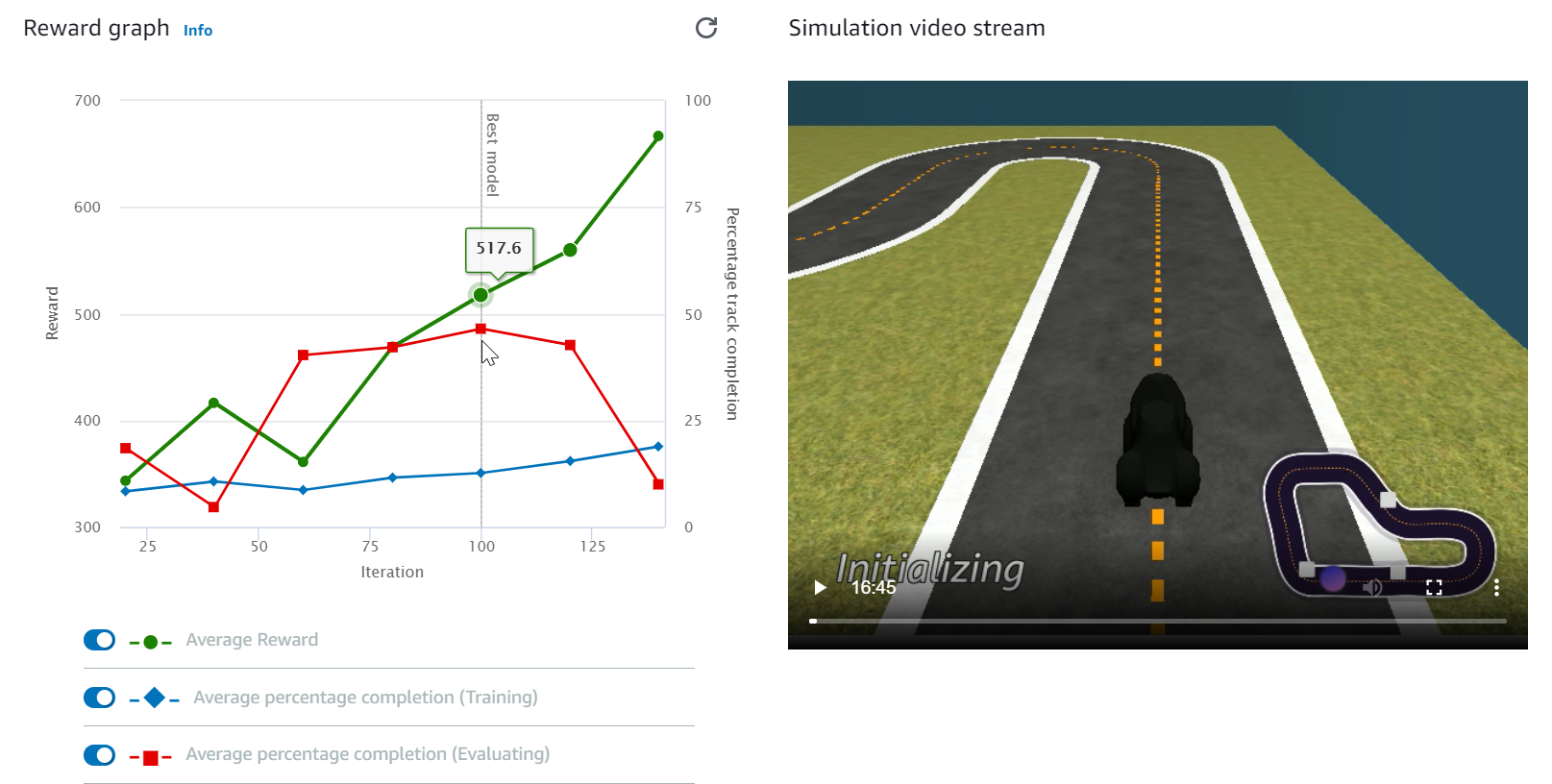
训练作业在 AWS 云上运行,因此您无需在训练期间将 AWS DeepRacer 控制台保持打开状态。您可以返回控制台,在作业进行中的任何时间点检查模型。
如果 模拟视频流 窗口或 奖励图 显示无响应,请刷新浏览器页面以更新训练进度。
