本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
AWS DeepRacer 中的强化学习
在强化学习中,以实现预期目标为目标的代理(例如实际或模拟 AWS DeepRacer 车辆)与环境交互,以最大程度提高代理的总奖励。在给定的环境状态下,代理在称为策略的策略指导下采取行动,并到达一个新的状态。任何操作都有关联的即时奖励。该奖励用于衡量操作的合用性。这种即时奖励视为由环境返回。
AWS DeepRacer 中强化学习的目标是在给定环境中学习最优策略。学习是一个试验和出错的迭代过程。代理采取随机初始操作来抵达新的状态。然后,代理迭代步骤,从新状态进入下一个状态。随着时间的推移,代理将发现能够带来最大长期奖励的操作。代理从初始状态到最终状态的交互称为情节。
以下草图说明了此学习过程:
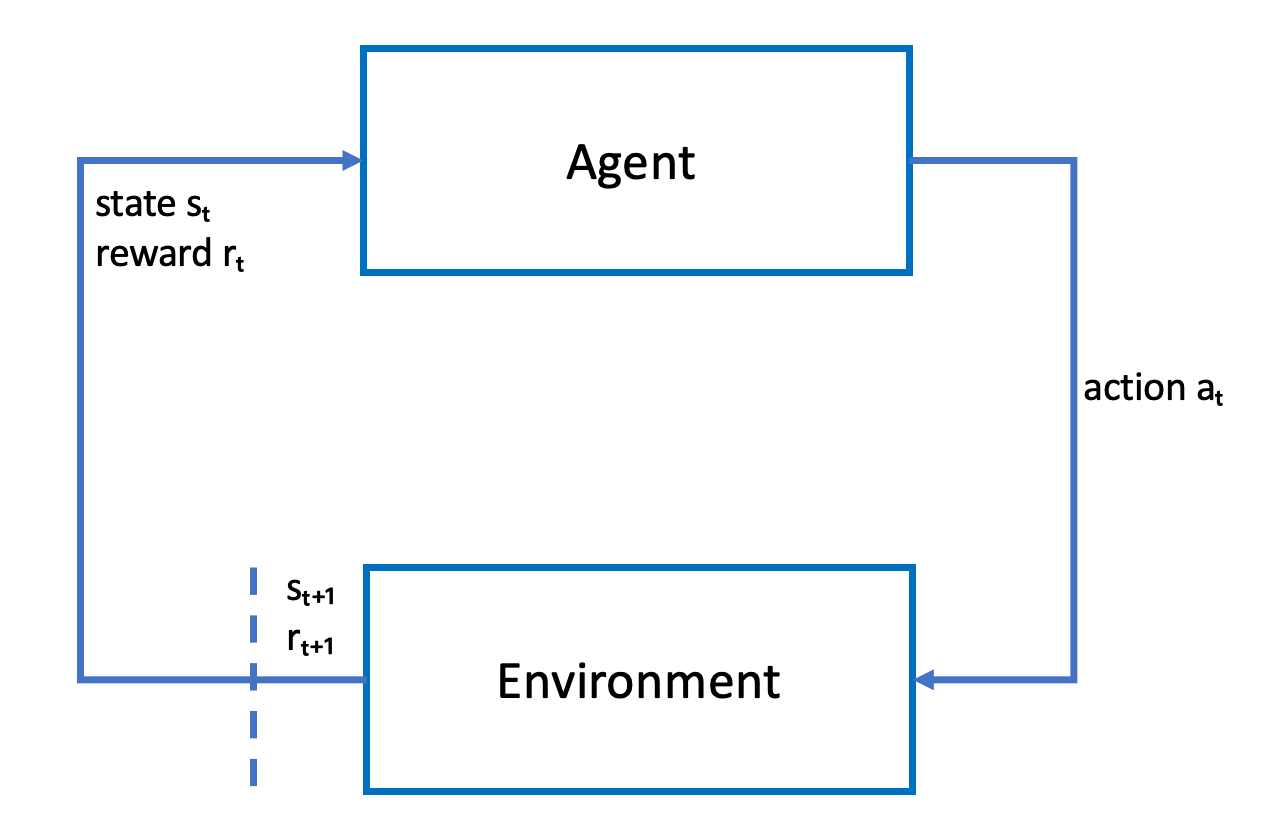
代理体现了一个神经网络,该神经网络代表逼近函数策略的函数。来自车辆前置摄像头的图像是环境状态,而代理操作由代理的速度和转向角度定义。
代理保持在赛道上完成竞赛时,将收到正奖励,偏离赛道则会收到负奖励。当代理从赛道上的某个位置启动时,情节开始,代理偏离赛道或者完成一圈时,情节结束。
注意
严格来讲,环境状态是指与问题相关的一切信息。例如,车辆在赛道上的位置以及赛道的形状。安装在车辆前方的摄像头提供的图像不会捕获完整的环境状态。因此,环境视为部分观察到,来自代理的输入称为观察而非状态。为简单起见,我们在本文中使用的状态和观察可以互换。
在模拟环境中训练代理有以下优势:
-
模拟可以估算代理已经完成了多少进度以及确定代理何时偏离赛道,用于计算奖励。
-
通过模拟,训练人员得以避免像在物理环境中那样,每次车辆偏离赛道就要进行重置的繁琐工作。
-
模拟可以加快训练过程。
-
模拟提供了对不同环境条件更好的控制,例如,选择不同赛道、背景和车辆条件。
强化学习的替代方法是监管学习,也称为模仿学习。此处为已知的数据集([图像, 操作] 元组),该数据集是从给定环境收集的,用于训练代理。通过模仿学习训练得到的模型可以应用于自动驾驶。只有当来自摄像头的图像与在训练数据集中使用的图像很相似时,它们才能很好地工作。为了实现稳健的驾驶,训练数据集必须全面。强化学习与之相反,不需要这种全面的标记工作,并且可以完全在模拟中训练。由于强化学习从随机操作开始,代理可以学习各种环境和赛道条件。这会使训练模型更稳健。
