本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
查看被动异常
在见解中,您可以查看 Amazon RDS 资源的异常。在被动见解页面的聚合指标部分,可以查看带有相应时间线的异常列表。还有一些部分显示与异常相关的日志组和事件的信息。被动见解中的因果异常每个都有相应的页面,其中包含有关异常的详细信息。
查看对 RDS 被动异常的详细分析
在此阶段,深入研究该异常,以获取有关 Amazon RDS 数据库实例的详细分析和建议。
详细分析仅适用于开启了“性能见解”的 Amazon RDS 数据库实例。
深入研究异常详情页面
-
在见解页面上,找到资源类型为 AWS/RDS 的聚合指标。
-
请选择查看详细信息。
出现异常详细信息页面。标题以数据库性能异常开头,并命名资源显示。无论异常何时出现,控制台都默认为严重性最高的异常。
-
(可选)如果多个资源受到影响,则从页面顶部的列表中选择一个不同的资源。
随后您可以找到对详情页面构成部分的说明。
资源概述
详情页面的顶部是资源概述。此部分总结了 Amazon RDS 数据库实例遇到的性能异常。
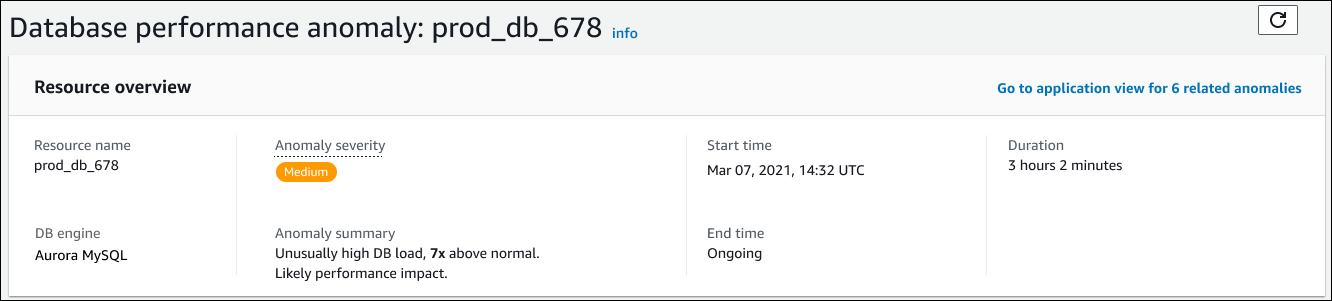
此部分包含以下字段:
-
资源名称 — 遇到异常的数据库实例的名称。在此示例中,该资源被命名为prod_db_678。
-
数据库引擎 — 遇到异常的数据库实例的名称。在此示例中,引擎是 Aurora MySQL。
-
异常严重性 — 衡量异常对实例的负面影响的标准。可能的严重性包括高、中和低。
-
异常摘要 — 对问题的简要综述。典型的摘要是数据库负载异常高。
-
开始时间和结束时间 — 异常开始和结束的时间。如果结束时间为持续,则异常仍在发生。
-
持续时间 — 异常行为的持续时间。在此示例中,异常持续存在,已经出现了 3 小时 2 分钟。
主要指标
主要指标部分汇总了因果异常,即见解中的最高一级异常。可以将因果异常视为数据库实例遇到的一般问题。
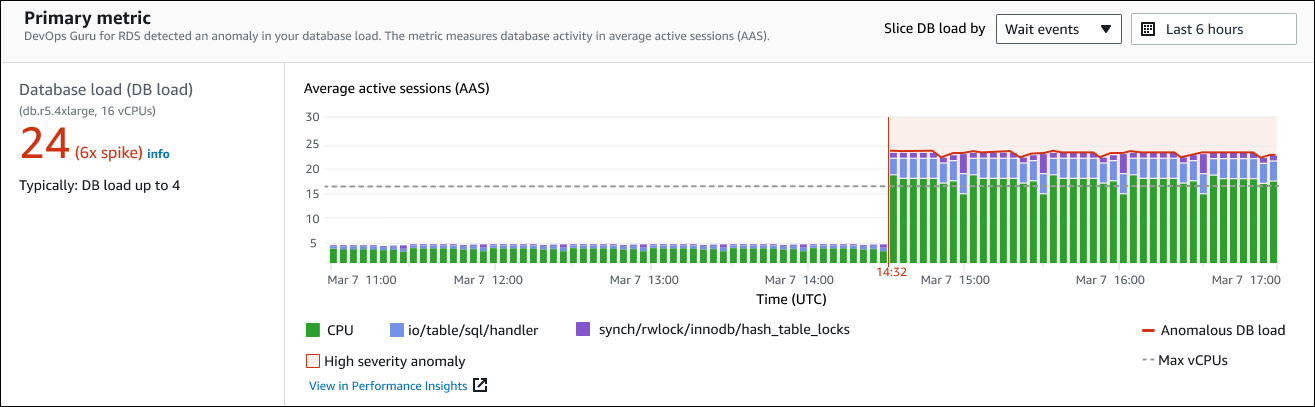
左侧面板提供了有关该问题的更多详细信息。在此示例中,摘要包含以下信息:
-
数据库负载(DB 负载)— 将异常归类为数据库负载问题。“性能见解”中的相应指标是
DBLoad。该指标也已发布到亚马逊 CloudWatch。 -
db.r5.4xlarge — 数据库实例类。vCPU 的数量(在此例中为 16)对应于平均活动会话数 (AAS) 图表中的虚线。
-
24(6 倍峰值)— 数据库负载,在见解报告的时间间隔内的平均活动会话 (AAS) 数量来衡量。因此,在异常期间的任何给定时间,数据库上平均有 24 个会话处于活动状态。数据库负载是该实例正常数据库负载的 6 倍。
-
典型:数据库负载最多为 4 — 典型工作负载期间以 AAS 衡量的数据库负载基准。值 4 表示,在正常操作期间,在任何给定时间,数据库上平均有 4 个或更少的会话处于活动状态。
默认情况下,负载图表由等待事件进行切片。这意味着,对于图表中的每个条形,最大的彩色区域表示占数据库总负载最多的等待事件。图表显示了问题开始的时间(红色)。将注意力集中于在条形中占用空间最多的等待事件:
-
CPU -
IO:wait/io/sql/table/handler
对于此 Aurora MySQL 数据库,上述等待事件出现的次数比正常情况要多。如需了解如何使用 Amazon Aurora 中的等待事件来调优性能,请参阅《Amazon Aurora 用户指南》中的为 Aurora MySQL 优化等待事件和为 Aurora PostgreSQL 优化等待事件。要了解如何在 RDS for PostgreSQL 中使用等待事件调整性能,请参阅《Amazon RDS 用户指南》中的使用 RDS for PostgreSQ 等待事件进行调整。
相关指标
相关指标部分列出了上下文异常,这些异常是因果异常中的具体发现。这些发现提供了有关性能问题的额外信息。
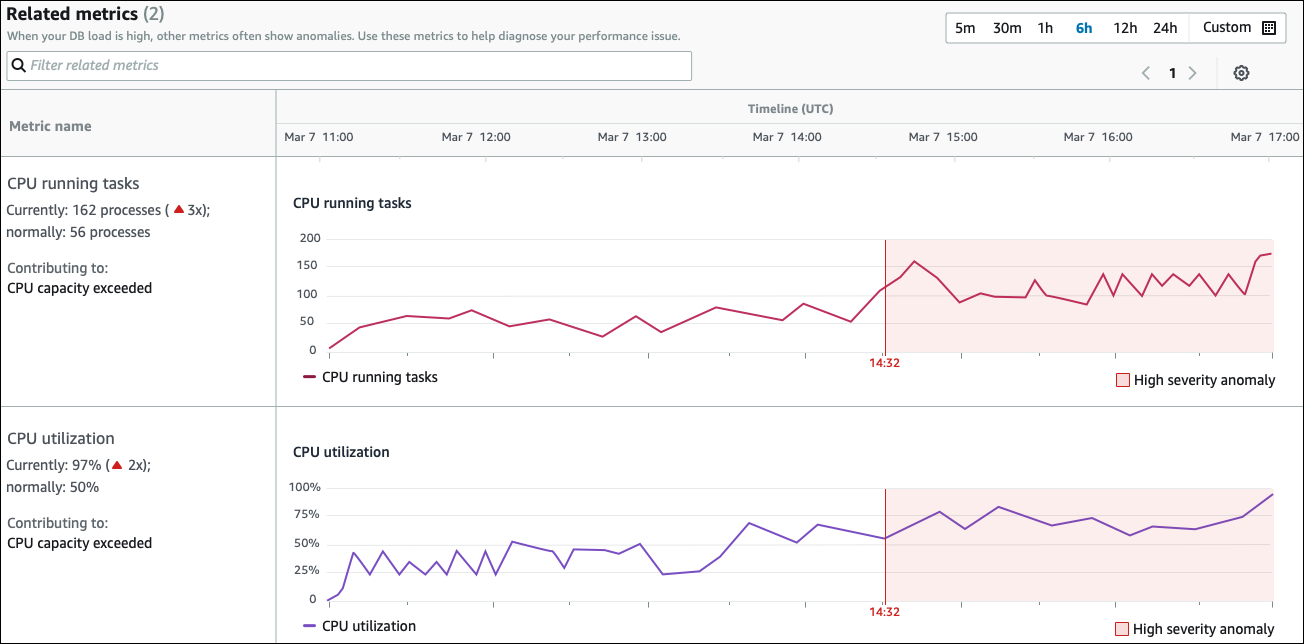
相关指标表有两列:指标名称和时间线 (UTC)。表中的每一行都对应特定的指标。
每行的第一列包含以下信息:
-
名称– 指标的名称。第一行将该指标标记为 CPU 运行任务。 -
当前 — 指标的当前值。在第一行,当前值为 162 个进程 (3x)。
-
通常-此数据库正常运行时的该指标的基准。 DevOpsGuru for RDS 将基线计算为历史记录 1 周内的第 95 个百分位数值。第一行表示 CPU 上通常有 56 个进程在运行。
-
促成 — 与该指标相关的发现。在第一行,CPU 运行任务指标与 CPU 容量超出异常关联。
时间线列显示该指标的折线图。阴影区域显示了 DevOps Guru for RDS 将发现指定为高严重性的时间间隔。
分析和建议
因果异常描述了总体问题,而上下文异则描述了需要调查的特定发现。每个发现都对应一组相关指标。
在以下分析和建议部分的示例中,高数据库负载异常有两个发现。
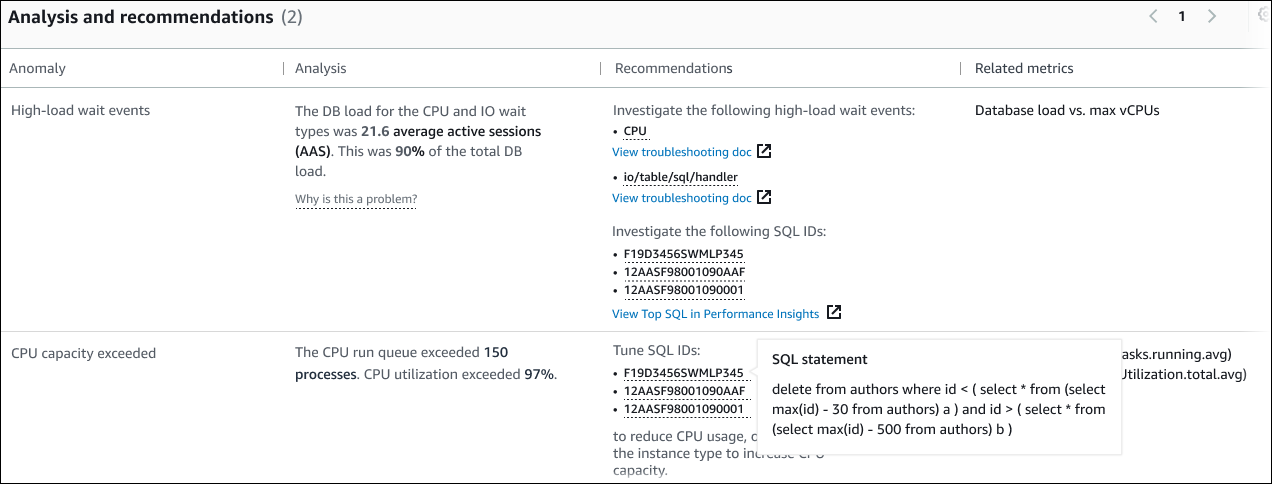
此表包含以下各列:
-
异常 — 对此上下文异常的一般描述。在此示例中,第一个异常是高负载等待事件,第二个异常是超出 CPU 容量。
-
分析 — 对异常的详细解释。
在第一个异常中,三种等待类型占数据库负载的 90%。在第二个异常中,CPU 运行队列超过 150,这意味着在任何给定时间,有超过 150 个会话在等待 CPU 时间。CPU 利用率超过 97%,这意味着在问题持续期间,CPU 有 97% 的时间处于忙碌状态。因此,CPU 几乎持续被占用,而平均有 150 个会话等待在 CPU 上运行。
-
建议 — 建议的用户对异常的响应。
在第一个异常中, DevOpsGuru for RDS 建议您调查等待事件
cpu和。io/table/sql/handler要了解如何根据这些事件调整数据库性能,请参阅《Amazon Aurora 用户指南》中的 cpu 和 io/table/sql/handler 。在第二个异常情况中, DevOpsGuru for RDS 建议您通过调整三个 SQL 语句来降低 CPU 消耗。您可以将鼠标悬停在链接上方以查看 SQL 文本。
-
相关指标 — 提供对异常进行具体衡量的指标。有关这些指标的更多信息,请参阅《Amazon Aurora 用户指南》中的 Amazon Aurora 指标参考或《Amazon RDS 用户指南》中的 Amazon RDS 指标参考。
在第一个异常中, DevOpsGuru for RDS 建议将数据库负载与实例的最大 CPU 进行比较。在第二个异常中,建议查看 CPU 运行队列、CPU 利用率和 SQL 执行率。
