本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
将 EMR 无服务器与 AWS Lake Formation 用于精细的访问控制
概述
在 Amazon EMR 7.2.0 及更高版本中, AWS Lake Formation 可以利用对由 S3 支持的数据目录表应用精细的访问控制。此功能允许您为 Amazon EMR Serverless Spark 作业中的 read 查询配置表、行、列和单元格级别的访问控制。要为 Apache Spark 批处理作业和交互式会话配置精细访问控制,请使用 EMR Studio。请参阅以下部分,了解有关 Lake Formation 以及如何将其与 EMR Serverless 结合使用的更多信息。
使用 Amazon EMR 无服务器会 AWS Lake Formation 产生额外费用。有关更多信息,请参阅 Amazon EMR 定价
EMR Serverless 是如何使用的 AWS Lake Formation
将 EMR Serverless 与 Lake Formation 结合使用,您可以对每个 Spark 作业强制执行一层权限,以便在 EMR Serverless 执行作业时应用 Lake Formation 权限控制。EMR Serverless 使用 Spark 资源配置文件
在使用 Lake Formation 的预初始化容量时,我们建议至少使用两个 Spark 驱动程序。每个 Lake Formation-enabled 作业都使用两个 Spark 驱动程序,一个用于用户配置文件,一个用于系统配置文件。为了获得最佳性能,与不使用 Lake Formation 相比,在 Lake Formation-enabled 作业中使用的司机数量是原来的两倍。
在 EMR Serverless 上运行 Spark 作业时,还请考虑动态分配对资源管理和集群性能的影响。每个资源配置文件的最大执行程序数的 spark.dynamicAllocation.maxExecutors 配置适用于用户和系统执行程序。如果将该数字配置为等于允许的最大执行程序数,则您的作业运行可能会因为一种类型的执行程序使用所有可用资源而卡住,这会在运行作业时阻止其他执行程序。
为避免资源耗尽,EMR Serverless 将每个资源配置文件的默认最大执行程序数量设置为 spark.dynamicAllocation.maxExecutors 值的 90%。如果指定 spark.dynamicAllocation.maxExecutorsRatio 的值在 0 和 1 之间,可以覆盖此配置。此外,请配置以下属性来优化资源分配和整体性能:
-
spark.dynamicAllocation.cachedExecutorIdleTimeout -
spark.dynamicAllocation.shuffleTracking.timeout -
spark.cleaner.periodicGC.interval
下面简要概述了 EMR Serverless 如何访问受 Lake Formation 安全策略保护的数据。
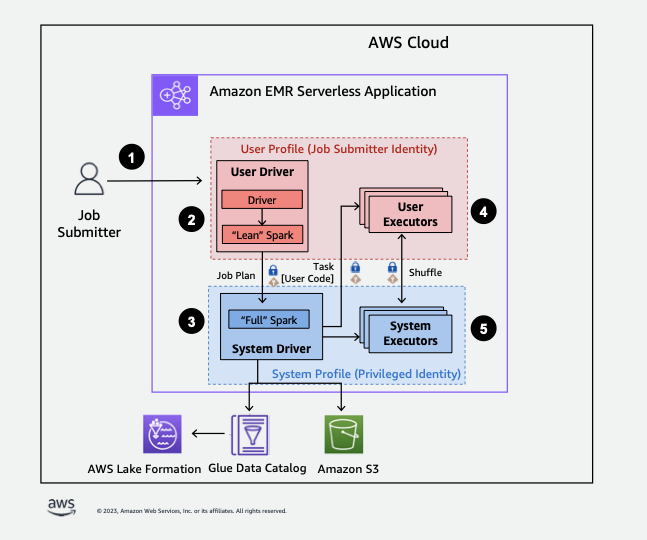
-
用户将 Spark 作业提交到 AWS Lake Formation启用了 EMR 的无服务器应用程序。
-
EMR Serverless 会将作业发送到用户驱动程序,并在用户配置文件中运行作业。用户驱动程序运行精简版的 Spark,该版本无法启动任务、请求执行程序、访问 S3 或 Glue Catalog。其构建了作业计划。
-
EMR Serverless 设置了第二个驱动程序(称为系统驱动程序),在系统配置文件中运行(使用特权身份)。EMR Serverless 在两个驱动程序之间建立了加密的 TLS 通道来进行通信。用户驱动程序使用该通道将作业计划发送到系统驱动程序。系统驱动程序不会运行用户提交的代码。而是运行完整的 Spark,并与 S3 和数据目录通信,以访问数据。并向执行程序发送请求,将作业计划编译成一系列执行阶段。
-
然后,EMR Serverless 使用用户驱动程序或系统驱动程序在执行程序上运行这些阶段。任何阶段的用户代码都只能在用户配置文件执行程序上运行。
-
从受安全筛选器保护的数据目录表中读取数据的阶段 AWS Lake Formation 或应用安全筛选器的阶段将委托给系统执行者。
在 Amazon EMR 中启用 Lake Formation
要启用 Lake Formation,请在创建 EMR Serverless 应用程序时,在运行时配置参数的 spark-defaults 分类下将 spark.emr-serverless.lakeformation.enabled 设置为 true。
aws emr-serverless create-application \ --release-label emr-7.13.0 \ --runtime-configuration '{ "classification": "spark-defaults", "properties": { "spark.emr-serverless.lakeformation.enabled": "true" } }' \ --type "SPARK"
您还可以在 EMR Studio 中创建新应用程序时启用 Lake Formation。在其他配置下,选择使用 Lake Formation 进行精细访问控制。
Inter-worker 将 Lake Formation 与 EMR Serverless 配合使用时,默认情况下会启用加密,因此您无需再次明确启用工作器间加密。
为 Spark 作业启用 Lake Formation
要为单个 Spark 作业启用 Lake Formation,请在使用 spark-submit 时将 spark.emr-serverless.lakeformation.enabled 设置为 true。
--conf spark.emr-serverless.lakeformation.enabled=true
作业运行时角色 IAM 权限
Lake For AWS mation 权限控制对 Glue 数据目录资源、Amazon S3 位置以及这些位置的基础数据的访问权限。IAM 权限控制对 Lake Formation 和 AWS Glue API 及资源的访问。虽然您可能拥有 Lake Formation 权限来访问数据目录(SELECT)中的表,但如果没有对 glue:Get* API 操作的 IAM 权限,操作就会失败。
下面是一个策略示例,展示了如何提供 IAM 权限以访问 S3 中的脚本、将日志上传到 S3、 AWS Glue API 权限以及访问 Lake Formation 的权限。
设置 Lake Formation 的作业运行时角色权限
首先,在 Lake Formation 中注册 Hive 表的位置。然后在所需的表上创建作业运行时角色的权限。有关 Lake Formation 的更多详情,请参阅什么是 AWS Lake Formation? 在《AWS Lake Formation 开发人员指南》中。
设置 Lake Formation 权限后,请在 Amazon EMR Serverless 上提交 Spark 作业。有关 Spark 作业的更多信息,请参阅 Spark 示例。
提交作业运行
设置 Lake Formation 授权后,便可以在 Amazon EMR Serverless 上提交 Spark 作业。以下部分展示了如何配置和提交作业运行属性的示例。
权限要求
未在中注册的表 AWS Lake Formation
对于未向注册的表 AWS Lake Formation,作业运行时角色同时访问 Glue 数据 AWS 目录和 Amazon S3 中的基础表数据。这要求任务运行时角色拥有相应的 IAM 权限,可同时执行 Glue AWS 和 Amazon S3 操作。
在中注册的表 AWS Lake Formation
对于注册到的表 AWS Lake Formation,作业运行时角色访问 AWS Glue 数据目录元数据,而 Lake Formation 提供的临时证书则访问 Amazon S3 中的基础表数据。执行操作所需的 Lake For AWS mation 权限取决于 Spark 任务启动的 Glue 数据目录和 Amazon S3 API 调用,可以总结如下:
-
D@@ ES CRIBE 权限允许运行时角色读取数据目录中的表或数据库元数据
-
ALTER 权限允许运行时角色修改数据目录中的表或数据库元数据
-
DROP 权限允许运行时角色从数据目录中删除表或数据库元数据
-
SE@@ LECT 权限允许运行时角色从 Amazon S3 读取表数据
-
INS@@ ERT 权限允许运行时角色将表数据写入 Amazon S3
-
删除权限允许运行时角色从 Amazon S3 中删除表数据
注意
当 Spark 任务调用 G AWS lue 来检索表元数据并调用 Amazon S3 来检索表数据时,Lake Formation 会延迟评估权限。在 Spark 发出需要缺少权限的 AWS Glue 或 Amazon S3 调用之前,使用权限不足的运行时角色的任务不会失败。
注意
在以下支持的表格矩阵中:
-
标记为 “支持” 的操作仅使用 Lake Formation 凭据来访问在 Lake Formation 中注册的表的表数据。如果 Lake Formation 权限不足,则操作将不会回退到运行时角色证书。对于未在 Lake Formation 中注册的表,作业运行时角色凭据可以访问表数据。
-
在 A mazon S3 位置上标记为 “支持” 且具有 IAM 权限的操作不会使用 Lake Formation 凭证访问亚马逊 S3 中的基础表数据。要运行这些操作,无论表是否已在 Lake Formation 中注册,任务运行时角色都必须具有访问表数据所必需的 Amazon S3 IAM 权限。
注意
从 Amazon EMR 7.12 开始,修改表数据的 DML 和 DDL 操作使用 Lake Formation 凭证。在 Amazon EMR 7.11 及更早版本中,这些操作(删除、更新和合并除外)使用任务运行时角色证书来修改表数据。Amazon EMR 7.11 及更早版本不支持删除、更新和合并操作。
