使用自定义连接器编写任务
您可以在 AWS Glue Studio 中为数据源节点和数据目标节点使用连接器和连接。
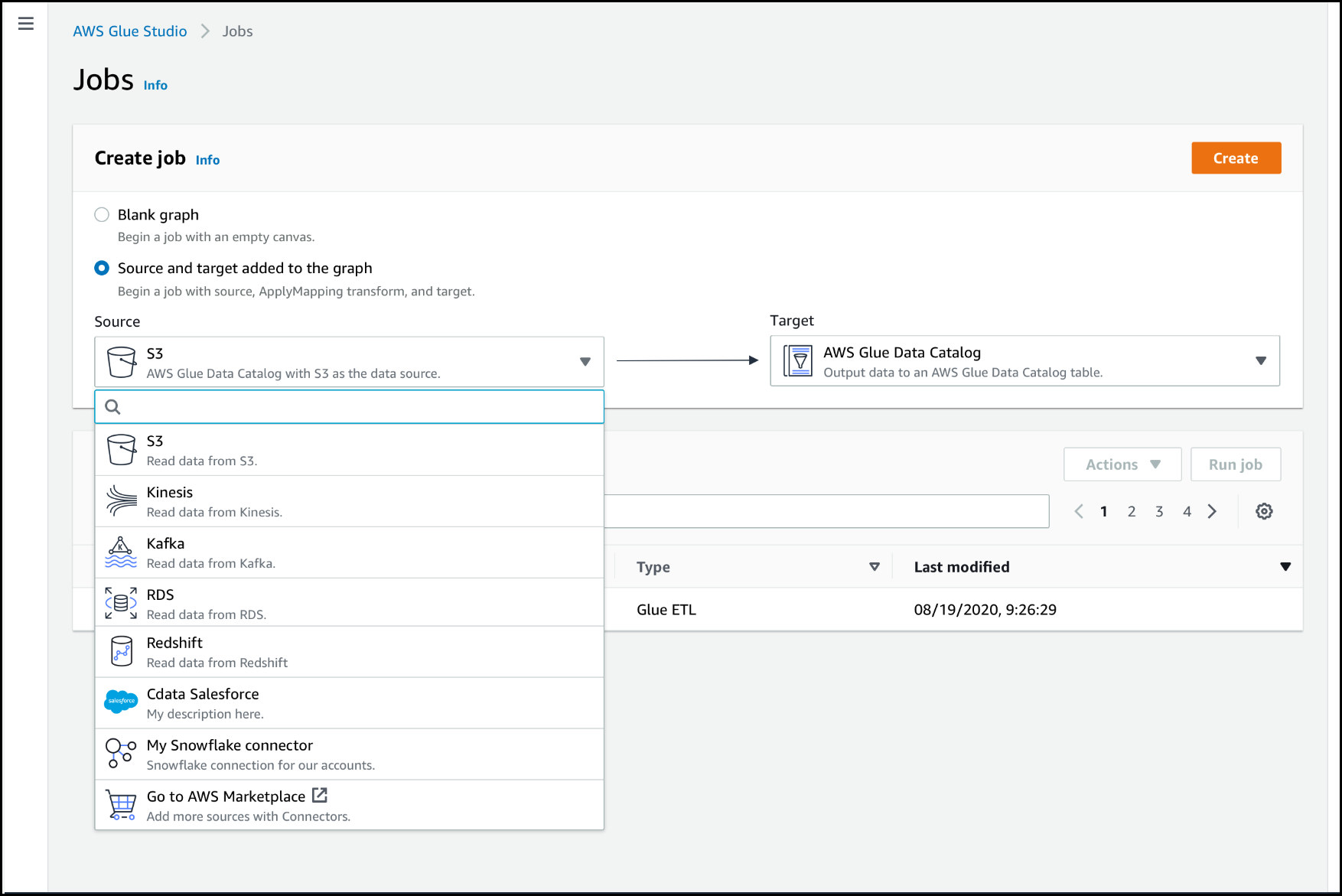
创建任务,为数据源使用连接器
创建新任务时,可以为数据源和数据目标选择连接器。
为使用连接器的节点配置源属性
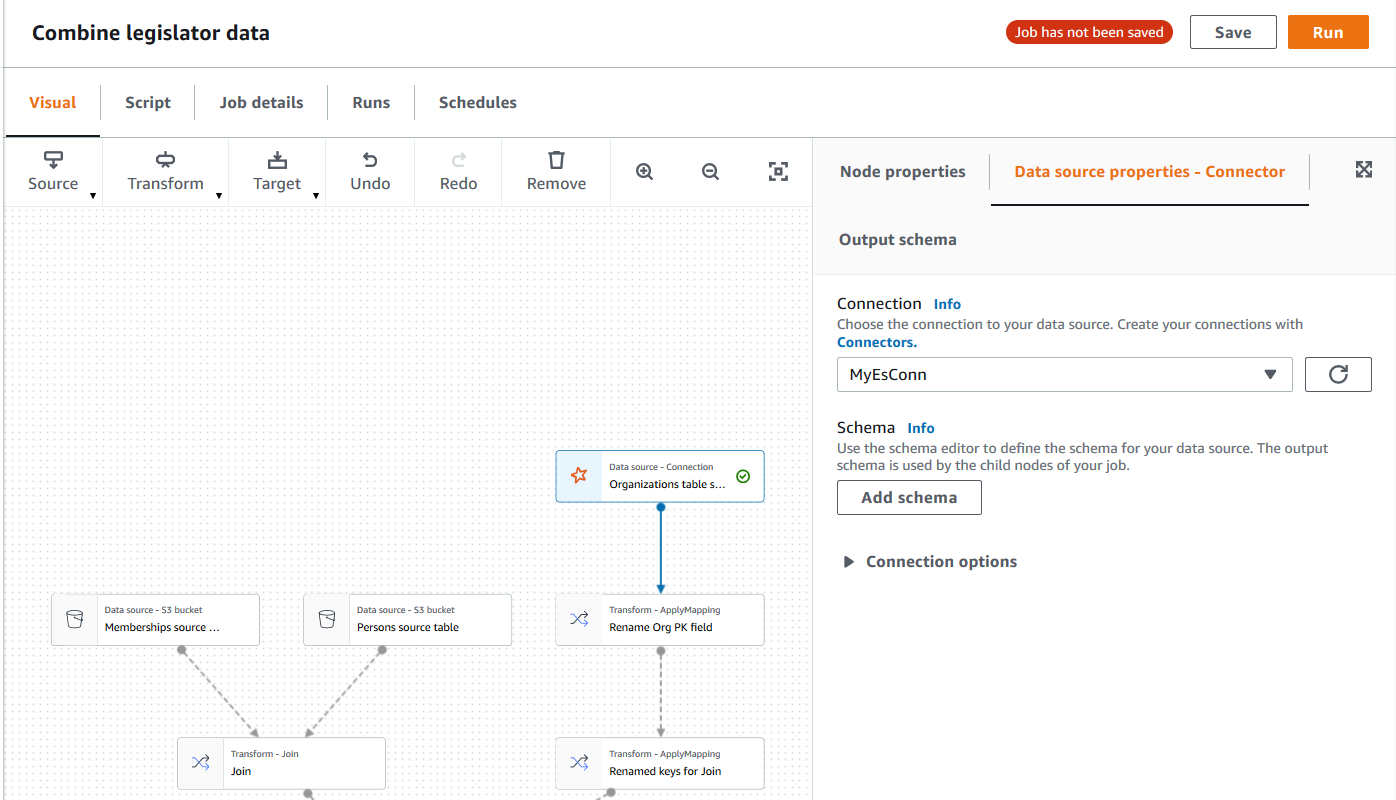
创建为数据源使用连接器的任务后,可视任务编辑器将显示任务图,其中包含为连接器配置的数据源节点。您必须为该节点配置数据源属性。
为使用连接器的数据源节点配置属性
-
选择任务图中的连接器数据源节点,或者添加新节点,然后为 Node type (节点类型) 选择连接器。然后,在右侧的节点详细信息面板中,选择 Data source properties (数据源属性) 选项卡(如果尚未选择)。
-
在 Data source properties (数据源属性) 选项卡上,选择要用于此任务的连接。
输入每种连接类型所需的附加信息:
- JDBC
-
-
Data source input type (数据源输入类型):选择以提供表名称或 SQL 查询作为数据源。根据您的选择,您需要提供以下附加信息:
-
Table name (表名称):数据源中表的名称。如果数据源未使用术语表,则提供适当数据结构的名称,如自定义连接器使用信息所示(AWS Marketplace 中提供)。
-
Filter predicate (筛选条件谓词):读取数据源时使用的条件子句,类似于 WHERE 子句,用于检索数据的子集。
-
Query code (查询代码):输入用于从数据源检索特定数据集的 SQL 查询。基本 SQL 查询示例:
SELECT column_list FROM
table_name WHERE where_clause
-
Schema (架构):因为 AWS Glue Studio 使用存储在连接中的信息来访问数据源,而不是从数据目录表中检索元数据信息,所以您必须为数据源提供架构元数据。选择 Add schema (添加架构),打开架构编辑器。
有关如何使用架构编辑器的说明,请参阅编辑自定义转换节点的架构。
-
Partition column (分区列):(可选)您可以为 Partition Column (分区列)、Lower bound (下限)、Upper bound (上限) 和 Number of partitions (分区数) 提供值,对数据读取进行分区。
lowerBound 和 upperBound 值用于确定分区步长,而不是用于筛选表中的行。对表中的所有行进行分区并返回。
列分区为用于读取数据的查询添加额外的分区条件。使用查询(而不是表名称)时,您应验证查询是否适用于指定的分区条件。例如:
-
Data type casting (数据类型转换):如果数据源使用 JDBC 中不可用的数据类型,请使用此部分指定如何将数据源中的数据类型转换为 JDBC 数据类型。您最多可指定 50 个不同的数据类型转换。数据源中使用相同数据类型的所有列都将以相同的方式进行转换。
例如,如果数据源中有三列使用 Float 数据类型,并且您指示 Float 数据类型应转换为 JDBC String 数据类型,则使用 Float 数据类型的所有三列将转换为 String 数据类型。
-
Job bookmark keys (任务书签键):任务书签可帮助 AWS Glue 维护状态信息,并防止重新处理旧数据。指定一个或多个列为书签键。AWS Glue Studio 使用书签键跟踪上次运行 ETL 任务期间已处理的数据。用于自定义书签键的列都必须严格单调递增或递减,但是允许有间隙。
如果您输入多个书签键,它们将合并成一个复合键。复合任务书签键不应包含重复的列。如果不指定书签键,则预设情况下,AWS Glue Studio 将使用主键作为书签键,前提是主键按顺序递增或递减(没有间隙)。如果表没有主键,但任务书签属性已启用,则必须提供自定义任务书签键。否则,无法搜索用作默认值的主键,任务运行将失败。
Job bookmark keys sorting order (任务书签键排序):选择键值是按顺序递增还是递减。
- Spark
-
-
Schema (架构):因为 AWS Glue Studio 使用存储在连接中的信息来访问数据源,而不是从数据目录表中检索元数据信息,所以您必须为数据源提供架构元数据。选择 Add schema (添加架构),打开架构编辑器。
有关如何使用架构编辑器的说明,请参阅编辑自定义转换节点的架构。
-
Connection options (连接选项):根据需要输入其他键值对,提供其他连接信息或选项。例如,您可以输入数据库名称、表名、用户名和密码。
例如,对于 OpenSearch,您可以输入以下键值对,如 教程:使用 AWS Glue Connector for Elasticsearch 中所述:
-
es.net.http.auth.user :
username
-
es.net.http.auth.pass :
password
-
es.nodes : https://<Elasticsearch
endpoint>
-
es.port : 443
-
path: <Elasticsearch
resource>
-
es.nodes.wan.only : true
有关要使用的最小连接选项的示例,请参阅 GitHub 上的测试脚本示例 MinimalSparkConnectorTest.scala,显示了您通常在连接中提供的连接选项。
- Athena
-
-
Table name (表名称):数据源中表的名称。如果您使用从 Athena-CloudWatch logs 读取数据的连接器,则需要输入表名 all_log_streams。
-
Athena schema name (Athena 架构名称):在 Athena 数据源中选择与包含该表的数据库相对应的架构。如果您使用从 Athena-CloudWatch logs 读取数据的连接器,则需要输入类似于 /aws/glue/name 的表名。
-
Schema (架构):因为 AWS Glue Studio 使用存储在连接中的信息来访问数据源,而不是从数据目录表中检索元数据信息,所以您必须为数据源提供架构元数据。选择 Add schema (添加架构),打开架构编辑器。
有关如何使用架构编辑器的说明,请参阅编辑自定义转换节点的架构。
-
Additional connection options (其他连接选项):根据需要输入其他键值对,提供其他连接信息或选项。
有关示例,请参阅 README.md 文件,网址为 https://github.com/aws-samples/aws-glue-samples/tree/master/GlueCustomConnectors/development/Athena。在本文档中的步骤中,示例代码显示了所需的最小连接选项,即 tableName、schemaName 和 className。代码示例将这些选项指定为 optionsMap 变量,但您可以为连接指定它们,然后使用连接。
-
(可选)提供所需信息后,您可以选择节点详细信息面板中的 Output schema (输出架构) 选项卡,查看生成的数据架构。此选项卡上显示的架构将由您添加到任务图的子节点使用。
-
(可选)配置节点属性和数据源属性后,您可以选择节点详细信息窗格中的 Data preview (数据预览) 选项卡来预览数据源的数据集。当您首次为任务中的任何节点选择此选项卡时,系统会提示您提供 IAM 角色以访问数据。使用此功能会产生相关费用,并且一旦您提供 IAM 角色,则会立即开始计费。
为使用连接器的节点配置目标属性
如果将连接器用于数据目标类型,则必须配置数据目标节点的属性。
为使用连接器的数据目标节点配置属性
-
在任务图中选择连接器数据目标节点。然后,在右侧的节点详细信息面板中,选择 Data target properties (数据目标属性) 选项卡(如果尚未选择)。
-
在 Data target properties (数据目标属性) 选项卡上,选择用于写入目标的连接。
输入每种连接类型所需的附加信息:
- JDBC
-
-
Connection (连接):选择要与连接器一起使用的连接。有关如何创建连接的信息,请参阅为连接器创建连接。
-
Table name (表名称):数据目标中表的名称。如果数据目标未使用术语表,则提供适当数据结构的名称,如自定义连接器使用信息所示(AWS Marketplace 中提供)。
-
Batch size (批处理大小)(可选):在单个操作中输入要在目标表中插入的行数或记录数。默认值是 1000 行。
- Spark
-
-
Connection (连接):选择要与连接器一起使用的连接。如果以前未创建连接,请选择 Create connection (创建连接) 创建一个。有关如何创建连接的信息,请参阅为连接器创建连接。
-
Connection options (连接选项):根据需要输入其他键值对,提供其他连接信息或选项。您可以输入数据库名称、表名、用户名和密码。
例如,对于 OpenSearch,您可以输入以下键值对,如 教程:使用 AWS Glue Connector for Elasticsearch 中所述:
-
es.net.http.auth.user :
username
-
es.net.http.auth.pass :
password
-
es.nodes : https://<Elasticsearch
endpoint>
-
es.port : 443
-
path: <Elasticsearch
resource>
-
es.nodes.wan.only : true
有关要使用的最小连接选项的示例,请参阅 GitHub 上的测试脚本示例 MinimalSparkConnectorTest.scala,显示了您通常在连接中提供的连接选项。
-
提供所需信息后,您可以选择节点详细信息面板中的 Output schema (输出架构) 选项卡,查看生成的数据架构。