在 AWS Glue Studio 中启动视觉 ETL 作业
您可以使用 AWS Glue Studio 中的简单视觉界面,创建您的 ETL 任务。您使用 Jobs (任务) 页面创建新任务。您还可以使用脚本编辑器或笔记本直接处理 AWS Glue Studio ETL 任务脚本中的代码。
在 Jobs (任务) 页面上,您可以看到您使用 AWS Glue Studio 或 AWS Glue 创建的所有任务。您可以在此页面上查看、管理和运行您的任务。
另请参阅博客教程
在 AWS Glue Studio 中启动作业
AWS Glue 允许您通过可视化界面、交互式代码笔记本或脚本编辑器创建作业。您可以通过单击任一选项来启动作业,也可以根据示例作业创建新作业。
示例作业使用您选择的工具创建作业。例如,示例作业允许您创建将 CSV 文件联接到目录表中的可视化 ETL 作业,使用 pandas 时在互式代码笔记本中使用 AWS Glue for Ray 或 AWS Glue for Spark 创建作业,或者使用 SparkSQL 在交互式代码笔记本中创建作业。
在 AWS Glue Studio 中从头开始创建作业
登录 AWS Management Console,然后通过以下网址打开 AWS Glue Studio 控制台:https://console.aws.amazon.com/gluestudio/
。 -
在导航窗格中,选择 ETL 作业。
-
在创建作业部分中,为您的作业选择一个配置选项。
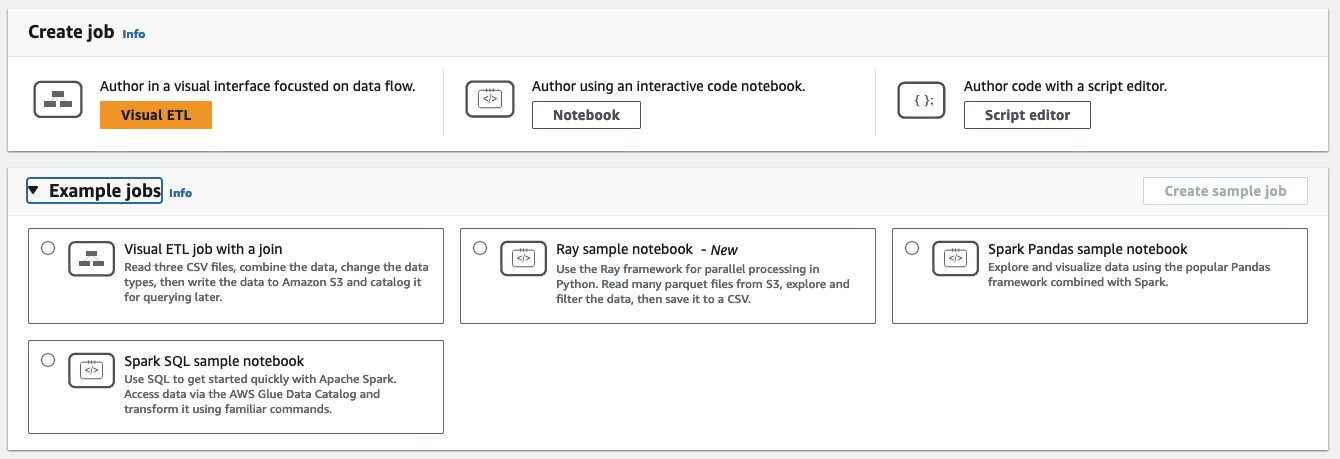
用于从头开始创建作业的选项:
-
Visual ETL - 以数据流为重点的可视化界面中编写
-
使用交互代码笔记本编写 - 基于 Jupyter Notebooks 的笔记本界面中以交互方式编写作业
选择此选项后,在创建笔记本创作会话之前,必须提供附加信息。有关如何指定此信息的详细信息,请参阅 在 AWS Glue Studio 中开启笔记本。
-
使用脚本编辑器编写代码 – 对于熟悉编程和编写 ETL 脚本的用户,请选择此选项,创建新的 Spark ETL 任务。选择引擎(Python shell、Ray、Spark(Python)或 Spark(Scala)。然后,选择重新开始或上传脚本,从本地文件上传现有脚本。如果您选择使用脚本编辑器,则无法使用可视化任务编辑器来设计或编辑任务。
Spark 任务会在由 AWS Glue 托管的 Apache Spark 环境中执行。默认情况下,新脚本以 Python 编码。要编写新的 Scala 脚本,请参阅在 AWS Glue Studio 中创建和编辑 Scala 脚本。
-
在 AWS Glue Studio 中利用示例作业创建作业
您可以选择从示例作业创建作业。在示例作业部分,选择一个示例作业,然后选择创建示例作业。使用其中一个选项创建示例作业提供了一个可供您使用的快速模板。
登录 AWS Management Console,然后通过以下网址打开 AWS Glue Studio 控制台:https://console.aws.amazon.com/gluestudio/
。 -
在导航窗格中,选择 ETL 作业。
-
选择一个选项,从示例作业创建作业:
-
用于联接多个源的 Visual ETL 作业 - 读取三个 CSV 文件,合并数据,更改数据类型,然后将数据写入 Amazon S3 并对其进行编目以供日后查询。
-
使用 Pandas 的 Spark 笔记本 - 使用广受欢迎的 Pandas 框架与 Spark 相结合,探索和可视化数据。
-
使用 SQL 的 Spark 笔记本 - 使用 SQL 快速开始使用 Apache Spark。通过 AWS Glue Data Catalog 访问数据,并使用熟悉的命令对其进行转换。
-
-
选择创建示例作业。
