当您开发和测试 AWS Glue for Spark 作业脚本时,有多种可用选项:
AWS Glue Studio 控制台
可视化编辑器
脚本编辑器
AWS Glue Studio 笔记本
交互式会话
Jupyter notebook
Docker 映像
本地开发
远程开发
AWS Glue Studio ETL 库
本地开发
您可以根据您的要求选择以上任何选项。
如果您喜欢无代码或低代码体验,则 AWS Glue Studio 可视化编辑器是不错的选择。
如果您更喜欢交互式笔记本体验,则 AWS Glue Studio 笔记本是一个不错的选择。有关更多信息,请参阅将笔记本与 AWS Glue Studio 和 AWS Glue 结合使用。如果您想使用您自己的本地环境,交互式会话是一个不错的选择。有关更多信息,请参阅将交互式会话与 AWS Glue 结合使用。
如果您更喜欢本地/远程开发体验,Docker 镜像是一个不错的选择。这可以帮助您在任何您喜欢的地方开发和测试 AWS Glue for Spark 作业脚本,而不会产生 AWS Glue 成本。
如果您更喜欢没有 Docker 的本地开发,则在本地安装 AWS Glue ETL 库目录是一个不错的选择。
使用 AWS Glue Studio 进行开发
AWS Glue Studio 可视化编辑器是一个图形界面,可以方便地在 AWS Glue 中创建、运行和监控提取、转换和加载 (ETL) 任务。您可以直观地编写数据转换工作流,并在 AWS Glue 的基于 Apache Spark 的无服务器 ETL 引擎上无缝运行它们。您可以在任务的每个步骤中检查架构和数据结果。有关更多信息,请参阅《AWS Glue Studio 用户指南》。
使用交互式会话进行开发
交互式会话使您可以在自己选择的环境中构建和测试应用程序。有关更多信息,请参阅将交互式会话与 AWS Glue 结合使用。
使用 Docker 镜像进行开发
注意
本部分中的说明尚未在 Microsoft Windows 操作系统上进行测试。
有关 Windows 平台上的本地开发和测试,请参阅博客 Building an AWS Glue ETL pipeline locally without an AWS account
对于生产就绪型数据平台,AWS Glue 作业的开发过程和 CI/CD 管道是一个关键主题。您可以在 Docker 容器中灵活地开发和测试 AWS Glue 作业。AWSGlue 在 Docker Hub 上托管 Docker 映像,以使用其他实用程序设置您的开发环境。您可以使用 AWS Glue ETL 库来使用您喜欢的 IDE、笔记本或 REPL。本主题介绍如何使用 Docker 映像在 Docker 容器中开发和测试 AWS Glue 版本 4.0 作业。
可以在 Docker Hub 上使用适用于 AWS Glue 的以下 Docker 映像。
对于
amazon/aws-glue-libs:glue_libs_4.0.0_image_01Glue 版本 4.0:AWS对于
amazon/aws-glue-libs:glue_libs_3.0.0_image_01Glue 版本 3.0:AWS对于
amazon/aws-glue-libs:glue_libs_2.0.0_image_01Glue 版本 2.0:AWS
这些镜像适用于 x86_64。建议您在此架构上进行测试。但是,有可能在不支持的基础镜像上重新设计本地开发解决方案。
此示例介绍如何在本地计算机上使用 amazon/aws-glue-libs:glue_libs_4.0.0_image_01 和运行容器。此容器映像已经过 AWS Glue 版本 3.3 Spark 作业测试。此影像包含以下内容:
Amazon Linux
AWS Glue ETL 库 (aws-glue-libs
) Apache Spark 3.3.0
Spark 历史记录服务器
Jupyter Lab
Livy
其他库依赖项(与其中一个 AWS Glue 作业系统的设置相同)
根据您的要求完成下列部分之一:
将容器设置为使用 spark-submit
将容器设置为使用 REPL shell(PySpark)
将容器设置为使用 Pytest
将容器设置为使用 Jupyter Lab
将容器设置为使用 Visual Studio 代码
先决条件
在开始之前,请确保已安装 Docker 并且 Docker 守护进程正在运行。有关安装说明,请参阅 Mac
有关在本地开发 AWS Glue 代码时的限制的更多信息,请参阅本地开发限制。
配置 AWS
要从容器启用 AWS API 调用,请按照以下步骤设置 AWS 凭证。在以下部分中,我们将使用此 AWS 命名配置文件。
-
设置 AWS CLI,配置命名配置文件。有关 AWS CLI 配置的更多信息,请参阅 AWS CLI 文档中的配置和凭证文件设置。
在终端中运行以下命令:
PROFILE_NAME="<your_profile_name>"
您可能还需要设置 AWS_REGION 环境变量以指定要向其发送请求的 AWS 区域。
设置和运行容器
将容器设置为通过 spark-submit 命令运行 PySpark 代码包括以下高级步骤:
从 Docker Hub 拉取镜像。
运行容器。
从 Docker Hub 拉取镜像
请运行以下命令从 Docker Hub 中拉取镜像:
docker pull amazon/aws-glue-libs:glue_libs_4.0.0_image_01运行容器
您现在可以使用此镜像运行容器。您可以根据您的要求选择以下任何选项。
spark-submit
您可以通过在容器上运行 spark-submit 命令来运行 AWS Glue 作业脚本。
编写脚本并在
/local_path_to_workspace目录下将其另存为sample1.py。本主题中包含示例代码作为附录。$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ mkdir -p ${WORKSPACE_LOCATION}/src $ vim ${WORKSPACE_LOCATION}/src/${SCRIPT_FILE_NAME}运行以下命令以在容器上执行
spark-submit命令,以提交新的 Spark 应用程序:$ docker run -it -v ~/.aws:/home/glue_user/.aws -v $WORKSPACE_LOCATION:/home/glue_user/workspace/ -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_spark_submit amazon/aws-glue-libs:glue_libs_4.0.0_image_01 spark-submit /home/glue_user/workspace/src/$SCRIPT_FILE_NAME ...22/01/26 09:08:55 INFO DAGScheduler: Job 0 finished: fromRDD at DynamicFrame.scala:305, took 3.639886 s root |-- family_name: string |-- name: string |-- links: array | |-- element: struct | | |-- note: string | | |-- url: string |-- gender: string |-- image: string |-- identifiers: array | |-- element: struct | | |-- scheme: string | | |-- identifier: string |-- other_names: array | |-- element: struct | | |-- lang: string | | |-- note: string | | |-- name: string |-- sort_name: string |-- images: array | |-- element: struct | | |-- url: string |-- given_name: string |-- birth_date: string |-- id: string |-- contact_details: array | |-- element: struct | | |-- type: string | | |-- value: string |-- death_date: string ...-
(可选)配置
spark-submit以匹配您的环境。例如,您可以将依赖关系与--jars配置一起传递。有关更多信息,请参阅 Spark 文档中的 Dynamically Loading Spark Properties。
REPL shell(Pyspark)
您可以运行 REPL(read-eval-print 循环)shell 进行交互式开发。
运行以下命令在容器上执行 PySpark 命令以启动 REPL shell:
$ docker run -it -v ~/.aws:/home/glue_user/.aws -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_pyspark amazon/aws-glue-libs:glue_libs_4.0.0_image_01 pyspark
...
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.1-amzn-0
/_/
Using Python version 3.7.10 (default, Jun 3 2021 00:02:01)
Spark context Web UI available at http://56e99d000c99:4040
Spark context available as 'sc' (master = local[*], app id = local-1643011860812).
SparkSession available as 'spark'.
>>> Pytest
对于单元测试,您可以将 pytest 用于 AWS Glue Spark 作业脚本。
运行以下命令进行准备。
$ WORKSPACE_LOCATION=/local_path_to_workspace
$ SCRIPT_FILE_NAME=sample.py
$ UNIT_TEST_FILE_NAME=test_sample.py
$ mkdir -p ${WORKSPACE_LOCATION}/tests
$ vim ${WORKSPACE_LOCATION}/tests/${UNIT_TEST_FILE_NAME}运行以下命令以在测试套件上执行 pytest:
$ docker run -it -v ~/.aws:/home/glue_user/.aws -v $WORKSPACE_LOCATION:/home/glue_user/workspace/ -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_pytest amazon/aws-glue-libs:glue_libs_4.0.0_image_01 -c "python3 -m pytest"
starting org.apache.spark.deploy.history.HistoryServer, logging to /home/glue_user/spark/logs/spark-glue_user-org.apache.spark.deploy.history.HistoryServer-1-5168f209bd78.out
*============================================================= test session starts =============================================================
*platform linux -- Python 3.7.10, pytest-6.2.3, py-1.11.0, pluggy-0.13.1
rootdir: /home/glue_user/workspace
plugins: anyio-3.4.0
*collected 1 item *
tests/test_sample.py . [100%]
============================================================== warnings summary ===============================================================
tests/test_sample.py::test_counts
/home/glue_user/spark/python/pyspark/sql/context.py:79: DeprecationWarning: Deprecated in 3.0.0. Use SparkSession.builder.getOrCreate() instead.
DeprecationWarning)
-- Docs: https://docs.pytest.org/en/stable/warnings.html
======================================================== 1 passed, *1 warning* in 21.07s ========================================================Jupyter Lab
您可以启动 Jupyter 以便在笔记本上进行交互式开发和临时查询。
运行以下命令启动 Jupyter Lab:
$ JUPYTER_WORKSPACE_LOCATION=/local_path_to_workspace/jupyter_workspace/ $ docker run -it -v ~/.aws:/home/glue_user/.aws -v $JUPYTER_WORKSPACE_LOCATION:/home/glue_user/workspace/jupyter_workspace/ -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 -p 8998:8998 -p 8888:8888 --name glue_jupyter_lab amazon/aws-glue-libs:glue_libs_4.0.0_image_01 /home/glue_user/jupyter/jupyter_start.sh ... [I 2022-01-24 08:19:21.368 ServerApp] Serving notebooks from local directory: /home/glue_user/workspace/jupyter_workspace [I 2022-01-24 08:19:21.368 ServerApp] Jupyter Server 1.13.1 is running at: [I 2022-01-24 08:19:21.368 ServerApp] http://faa541f8f99f:8888/lab [I 2022-01-24 08:19:21.368 ServerApp] or http://127.0.0.1:8888/lab [I 2022-01-24 08:19:21.368 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).在本地计算机的 Web 浏览器中打开 http://127.0.0.1:8888/lab,以查看 Jupyter 实验室用户界面。
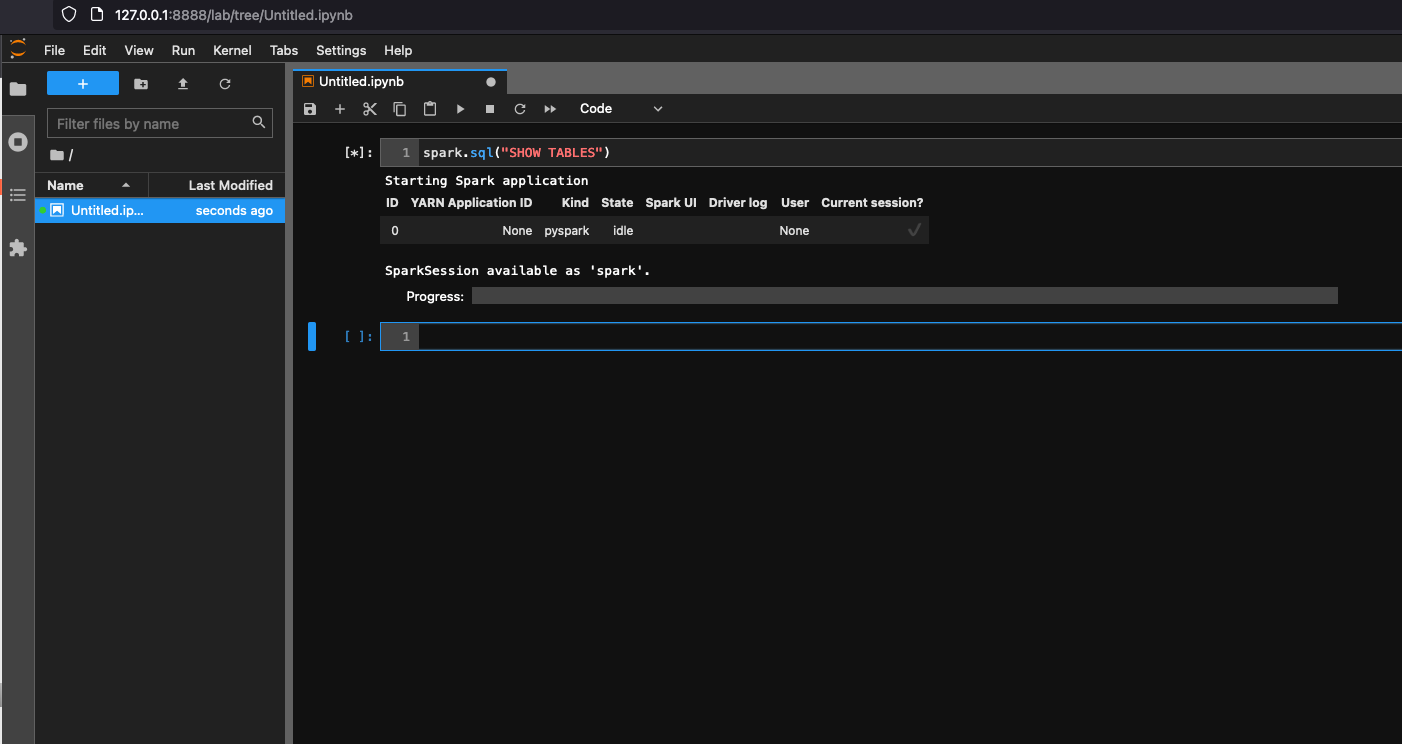
在笔记本下选择 Glue Spark Local (PySpark)。您可以开始在交互式 Jupyter notebook UI 中开发代码。
将容器设置为使用 Visual Studio 代码
先决条件:
安装 Visual Studio 代码。
安装 Python
。 在 Visual Studio 代码中打开工作区文件夹。
选择设置。
请选择 Workspace(工作区)。
请选择 Open Settings (JSON)(打开设置(JSON))。
粘贴以下 JSON 并保存它。
{ "python.defaultInterpreterPath": "/usr/bin/python3", "python.analysis.extraPaths": [ "/home/glue_user/aws-glue-libs/PyGlue.zip:/home/glue_user/spark/python/lib/py4j-0.10.9.5-src.zip:/home/glue_user/spark/python/", ] }
步骤:
运行 Docker 容器。
$ docker run -it -v ~/.aws:/home/glue_user/.aws -v $WORKSPACE_LOCATION:/home/glue_user/workspace/ -e AWS_PROFILE=$PROFILE_NAME -e DISABLE_SSL=true --rm -p 4040:4040 -p 18080:18080 --name glue_pyspark amazon/aws-glue-libs:glue_libs_4.0.0_image_01 pyspark启动 Visual Studio 代码。
请选择左侧菜单中的 Remote Explorer,然后选择
amazon/aws-glue-libs:glue_libs_4.0.0_image_01。
右键单击并选择 Attach to Container(附加到容器)。如果显示对话框,请选择 Got it(明白了)。
打开
/home/glue_user/workspace/。创建 Glue PySpark 脚本,然后选择 Run(运行)。
您将看到脚本成功运行。
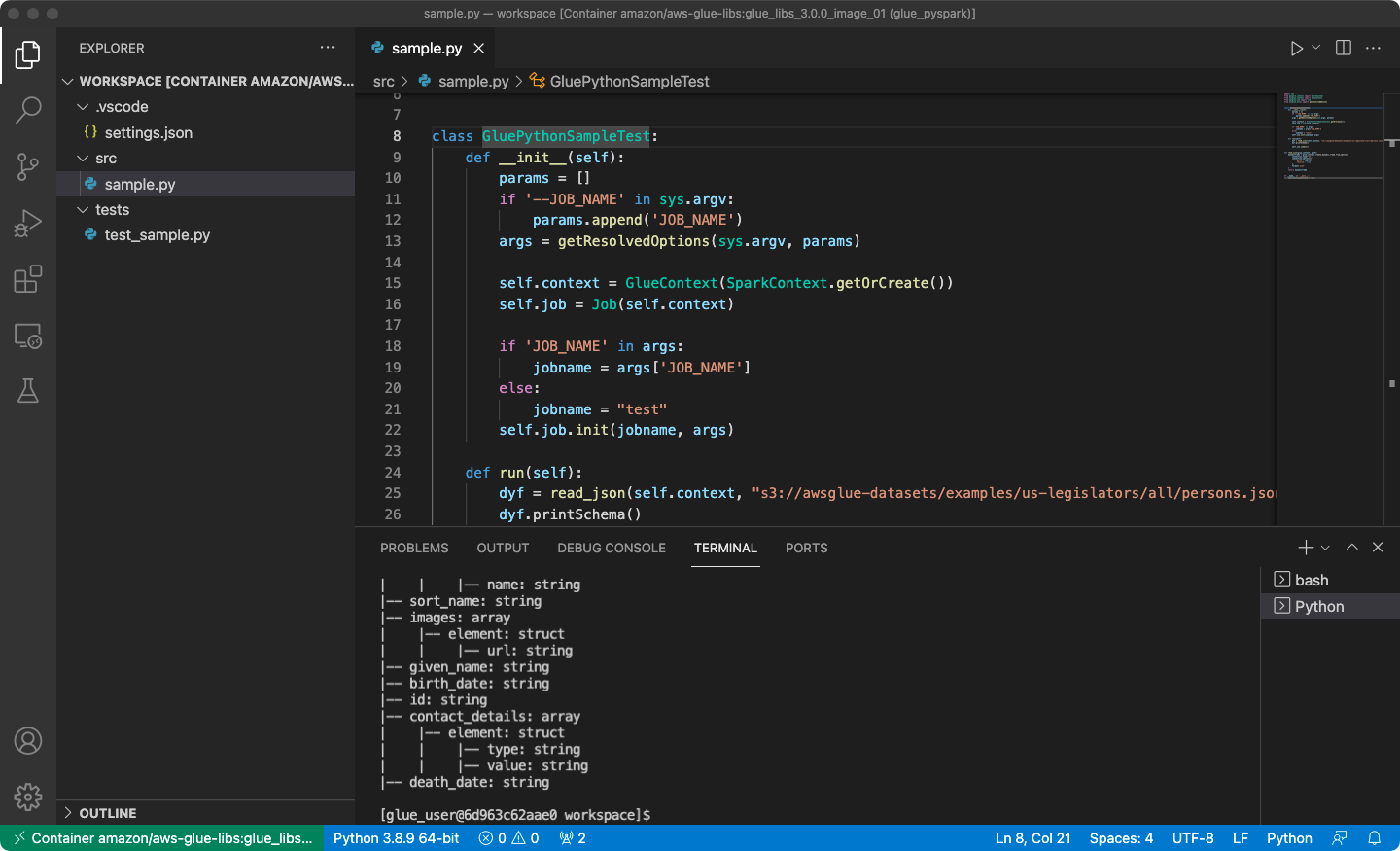
附录:用于测试的 AWS Glue 作业示例代码
本附录提供了脚本作为用于测试目的 AWS Glue 作业示例代码。
sample.py:用于将 AWS Glue ETL 库与 Amazon S3 API 调用结合使用的示例代码
import sys
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.utils import getResolvedOptions
class GluePythonSampleTest:
def __init__(self):
params = []
if '--JOB_NAME' in sys.argv:
params.append('JOB_NAME')
args = getResolvedOptions(sys.argv, params)
self.context = GlueContext(SparkContext.getOrCreate())
self.job = Job(self.context)
if 'JOB_NAME' in args:
jobname = args['JOB_NAME']
else:
jobname = "test"
self.job.init(jobname, args)
def run(self):
dyf = read_json(self.context, "s3://awsglue-datasets/examples/us-legislators/all/persons.json")
dyf.printSchema()
self.job.commit()
def read_json(glue_context, path):
dynamicframe = glue_context.create_dynamic_frame.from_options(
connection_type='s3',
connection_options={
'paths': [path],
'recurse': True
},
format='json'
)
return dynamicframe
if __name__ == '__main__':
GluePythonSampleTest().run()
上面的代码需要 AWS IAM 中的 Amazon S3 权限。您需要授予 IAM 托管策略 arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess 或 IAM 自定义策略,以允许您为 Amazon S3 路径调用 ListBucket 和 GetObject。
test_sample.py:用于 sample.py 单元测试的示例代码。
import pytest
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.utils import getResolvedOptions
import sys
from src import sample
@pytest.fixture(scope="module", autouse=True)
def glue_context():
sys.argv.append('--JOB_NAME')
sys.argv.append('test_count')
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
context = GlueContext(SparkContext.getOrCreate())
job = Job(context)
job.init(args['JOB_NAME'], args)
yield(context)
job.commit()
def test_counts(glue_context):
dyf = sample.read_json(glue_context, "s3://awsglue-datasets/examples/us-legislators/all/persons.json")
assert dyf.toDF().count() == 1961
使用 AWS Glue ETL 库进行开发
AWS Glue ETL 库在公有 Amazon S3 存储桶中可用,并且可以由 Apache Maven 构建系统使用。这使您可以在本地开发和测试 Python 和 Scala 提取、转换和加载 (ETL) 脚本,而无需网络连接。建议使用 Docker 镜像进行本地开发,因为它提供了一个为使用此库而正确配置的环境。
本地开发适用于所有 AWS Glue 版本,包括 AWS Glue 版本 0.9、1.0、2.0 及更高版本。有关可与 AWS Glue 配合使用的 Python 和 Apache Spark 版本的信息,请参阅 Glue version job property。
该库随 Amazon 软件许可证 (https://aws.amazon.com/asl
本地开发限制
使用 AWS Glue Scala 库进行本地开发时,请记住以下限制。
-
避免使用 AWS Glue 库创建程序集 jar(“fat jar”或“uber jar”),因为这将导致以下功能被禁用:
-
AWS Glue Parquet 写入器 (在 AWS Glue 中使用 Parquet 格式)
这些功能仅在 AWS Glue 任务系统内可用。
-
本地开发不支持 FindMatches 转换。
-
本地开发不支持矢量化的 SIMD CSV 读取器。
-
本地开发不支持用于从 S3 路径加载 JDBC 驱动程序的 customJdbcDriverS3Path 属性。或者,您可以在本地下载 JDBC 驱动程序并从那里加载。
-
本地开发不支持 Glue Data Quality。
使用 Python 在本地开发
完成一些先决步骤,然后使用 AWS Glue 实用工具来测试和提交您的 Python ETL 脚本。
本地 Python 开发的先决条件
完成以下步骤以准备本地 Python 开发:
-
从 GitHub(https://github.com/awslabs/aws-glue-libs
)克隆 AWS Glue Python 存储库。 -
请执行以下操作之一:
对于 AWS Glue 版本 0.9,请签出分支
glue-0.9。对于 AWS Glue 版本 1.0,请签出分支
glue-1.0。AWS Glue 0.9 以上的所有版本均支持 Python 3。对于 AWS Glue 版本 2.0,请签出分支
glue-2.0。对于 AWS Glue 版本 3.0,请签出分支
glue-3.0。对于 AWS Glue 版本 4.0,请签出
master分支。
-
从以下位置安装 Apache Maven:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-common/apache-maven-3.6.0-bin.tar.gz
。 -
从下列位置之一安装 Apache Spark 分发:
对于 AWS Glue 版本 0.9:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-0.9/spark-2.2.1-bin-hadoop2.7.tgz
对于 https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-1.0/spark-2.4.3-bin-hadoop2.8.tgz
Glue 版本 1.0:AWS 对于 https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-2.0/spark-2.4.3-bin-hadoop2.8.tgz
Glue 版本 2.0:AWS 对于 https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-3.0/spark-3.1.1-amzn-0-bin-3.2.1-amzn-3.tgz
Glue 版本 3.0:AWS 对于 https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-4.0/spark-3.3.0-amzn-1-bin-3.3.3-amzn-0.tgz
Glue 版本 4.0:AWS
-
导出
SPARK_HOME环境变量,将其设置为从 Spark 归档文件中提取的根位置。例如:对于 AWS Glue 版本 0.9:
export SPARK_HOME=/home/$USER/spark-2.2.1-bin-hadoop2.7对于 AWS Glue 版本 1.0 及 2.0:
export SPARK_HOME=/home/$USER/spark-2.4.3-bin-spark-2.4.3-bin-hadoop2.8对于
export SPARK_HOME=/home/$USER/spark-3.1.1-amzn-0-bin-3.2.1-amzn-3Glue 版本 3.0:AWS对于
export SPARK_HOME=/home/$USER/spark-3.3.0-amzn-1-bin-3.3.3-amzn-0Glue 版本 4.0:AWS
运行您的 Python ETL 脚本
使用可用于本地开发的 AWS Glue jar 文件,您可以在本地运行 AWS Glue Python 程序包。
使用以下实用工具和框架来测试和运行 Python 脚本。下表中列出的命令是从 AWS Glue Python 程序包
| 实用工具 | 命令 | 描述 |
|---|---|---|
| AWS Glue Shell | ./bin/gluepyspark |
在与 AWS Glue ETL 库集成的 shell 中输入并运行 Python 脚本。 |
| AWS Glue 提交 | ./bin/gluesparksubmit |
提交完整的 Python 脚本以供执行。 |
| Pytest | ./bin/gluepytest |
编写并运行 Python 代码的单元测试。必须在 PATH 中安装 pytest 模块并使其可用。有关更多信息,请参阅 pytest 文档 |
使用 Scala 在本地开发
完成一些先决步骤,然后发出 Maven 命令以在本地运行 Scala ETL 脚本。
本地 Scala 开发的先决条件
完成这些步骤以准备本地 Scala 开发。
步骤 1:安装软件
在此步骤中,您将安装软件并设置所需的环境变量。
-
从以下位置安装 Apache Maven:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-common/apache-maven-3.6.0-bin.tar.gz
。 -
从下列位置之一安装 Apache Spark 分发:
对于 AWS Glue 版本 0.9:https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-0.9/spark-2.2.1-bin-hadoop2.7.tgz
对于 https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-1.0/spark-2.4.3-bin-hadoop2.8.tgz
Glue 版本 1.0:AWS 对于 https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-2.0/spark-2.4.3-bin-hadoop2.8.tgz
Glue 版本 2.0:AWS 对于 https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-3.0/spark-3.1.1-amzn-0-bin-3.2.1-amzn-3.tgz
Glue 版本 3.0:AWS 对于 https://aws-glue-etl-artifacts.s3.amazonaws.com/glue-4.0/spark-3.3.0-amzn-1-bin-3.3.3-amzn-0.tgz
Glue 版本 4.0:AWS
-
导出
SPARK_HOME环境变量,将其设置为从 Spark 归档文件中提取的根位置。例如:对于 AWS Glue 版本 0.9:
export SPARK_HOME=/home/$USER/spark-2.2.1-bin-hadoop2.7对于 AWS Glue 版本 1.0 及 2.0:
export SPARK_HOME=/home/$USER/spark-2.4.3-bin-spark-2.4.3-bin-hadoop2.8对于
export SPARK_HOME=/home/$USER/spark-3.1.1-amzn-0-bin-3.2.1-amzn-3Glue 版本 3.0:AWS对于
export SPARK_HOME=/home/$USER/spark-3.3.0-amzn-1-bin-3.3.3-amzn-0Glue 版本 4.0:AWS
步骤 2:配置您的 Maven 项目
使用以下 pom.xml 文件作为 AWS Glue Scala 应用程序的模板。它包含所需的 dependencies、repositories 和 plugins 元素。将 Glue version 字符串替换为以下各项之一:
-
对于 AWS Glue 版本 4.0 为
4.0.0 -
对于 AWS Glue 版本 3.0 为
3.0.0 -
对于 AWS Glue 版本 1.0 或 2.0 为
1.0.0 -
对于 AWS Glue 版本 0.9 为
0.9.0
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.amazonaws</groupId>
<artifactId>AWSGlueApp</artifactId>
<version>1.0-SNAPSHOT</version>
<name>${project.artifactId}</name>
<description>AWS ETL application</description>
<properties>
<scala.version>2.11.1 for AWS Glue 2.0 or below, 2.12.7 for AWS Glue 3.0 and 4.0</scala.version>
<glue.version>Glue version with three numbers (as mentioned earlier)</glue.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<!-- A "provided" dependency, this will be ignored when you package your application -->
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>AWSGlueETL</artifactId>
<version>${glue.version}</version>
<!-- A "provided" dependency, this will be ignored when you package your application -->
<scope>provided</scope>
</dependency>
</dependencies>
<repositories>
<repository>
<id>aws-glue-etl-artifacts</id>
<url>https://aws-glue-etl-artifacts.s3.amazonaws.com/release/</url>
</repository>
</repositories>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<!-- see http://davidb.github.com/scala-maven-plugin -->
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.6.0</version>
<executions>
<execution>
<goals>
<goal>java</goal>
</goals>
</execution>
</executions>
<configuration>
<systemProperties>
<systemProperty>
<key>spark.master</key>
<value>local[*]</value>
</systemProperty>
<systemProperty>
<key>spark.app.name</key>
<value>localrun</value>
</systemProperty>
<systemProperty>
<key>org.xerial.snappy.lib.name</key>
<value>libsnappyjava.jnilib</value>
</systemProperty>
</systemProperties>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-enforcer-plugin</artifactId>
<version>3.0.0-M2</version>
<executions>
<execution>
<id>enforce-maven</id>
<goals>
<goal>enforce</goal>
</goals>
<configuration>
<rules>
<requireMavenVersion>
<version>3.5.3</version>
</requireMavenVersion>
</rules>
</configuration>
</execution>
</executions>
</plugin>
<!-- The shade plugin will be helpful in building a uberjar or fatjar.
You can use this jar in the AWS Glue runtime environment. For more information, see https://maven.apache.org/plugins/maven-shade-plugin/ -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<configuration>
<!-- any other shade configurations -->
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>运行您的 Scala ETL 脚本
从 Maven 项目根目录运行以下命令以运行 Scala ETL 脚本。
mvn exec:java -Dexec.mainClass="mainClass" -Dexec.args="--JOB-NAMEjobName"
将 mainClass 替换为脚本主类的完全限定类名。将 jobName 替换为所需的作业名称。
配置测试环境
有关配置本地测试环境的示例,请参阅以下博客文章:
如果要使用开发终端节点或笔记本电脑测试 ETL 脚本,请参阅使用开发终端节点来开发脚本。
注意
不支持将开发终端节点与 AWS Glue 版本 2.0 任务一起使用。有关更多信息,请参阅运行 Spark ETL 任务,减少启动时间。
