要在 AWS Glue Studio 中开始使用异常检测,请打开 AWS Glue Studio 作业,然后单击评估数据质量转换。
启用此功能后,AWS Glue 数据质量自动监测功能将随着时间推移分析您的数据,从而检测异常。此功能提供了有关您数据的宝贵数据统计信息和观测值,让您能够对任何已识别的异常采取行动。
查看异常检测文档,了解此功能的内部工作原理。
启用异常检测
在 AWS Glue Studio 中启用异常检测:
-
在作业中选择数据质量节点,然后选择异常检测选项卡。切换以打开启用异常检测。
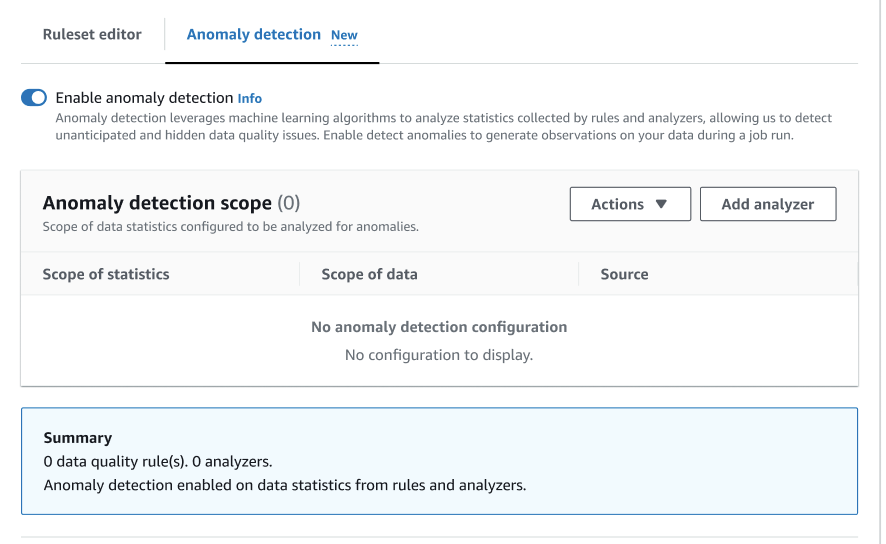
-
通过选择添加分析器来定义要监测异常情况的数据。有两个字段可以进行填充:“统计信息”和“数据”。
-
统计信息是指有关数据形状和其他属性的信息。您可以一次选择一个或多个统计信息,也可以选择所有统计信息。统计信息包括:Completeness、Uniqueness、Mean、Sum、StandardDeviation、Entropy、DistinctValuesCount、UniqueValueRatio 等。有关更多详细信息,请参阅分析器文档。
-
数据是指数据集中的列。您可以选择所有列或单个列。
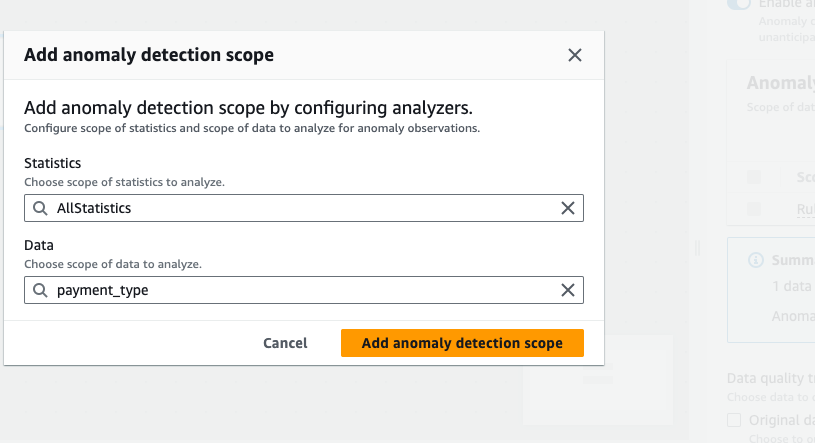
-
-
选择添加异常检测范围,以保存您的更改。添加分析器后,可在异常检测范围部分中看到这些分析器。
您也可以使用操作菜单编辑分析器,或者选择规则集编辑器选项卡,直接在规则集编辑器记事本中编辑分析器。您将在自己创建的所有规则下方看到您保存的分析器。
Rules = [ ] Analyzers = [ Completeness “id” ]
配置了经更新的规则集和分析器后,AWS Glue 数据质量自动监测功能就会持续监控传入的数据流。根据您的设置,此功能可以通过警报或作业停止发出潜在的异常信号。这种主动监控有助于确保整个数据管道的数据质量和完整性。
在下一节中,您将了解如何有效地监控由系统识别的异常。您还将学习如何查看和分析 AWS Glue 数据质量自动监测功能收集的数据统计信息。此外,您还将了解如何向支持异常检测功能的机器学习模型提供反馈。此反馈循环对于提高模型的准确性,以及确保模型能够有效地检测符合您特定业务需求和数据模式的异常至关重要。
