| Apache Spark 的生成式人工智能升级预览版在以下 AWS 区域中为 AWS Glue 提供:美国东部(俄亥俄州)、美国东部(弗吉尼亚州北部)、美国西部(俄勒冈州)、亚太地区(东京)和亚太地区(悉尼)。预览版功能可能会随时更改。 |
AWS Glue 中的 Spark 升级功能使数据工程师和开发者能够使用生成式人工智能将其现有的 AWS Glue Spark 作业升级和迁移到最新的 Spark 版本。数据工程师可以使用该功能来扫描其 AWS Glue Spark 作业、生成升级计划、执行计划和验证输出。该功能通过自动执行识别和更新 Spark 脚本、配置、依赖项、方法和功能的无差别工作,缩短了 Spark 升级的时间并降低了升级成本。
工作方式
使用升级分析功能时,AWS Glue 会识别作业务代码中版本和配置之间的差异,从而生成升级计划。升级计划会详细说明所有代码更改以及所需的迁移步骤。接下来,AWS Glue 会在沙盒环境中构建并运行升级后的应用程序以验证更改,并生成代码更改列表供您迁移作业。您可以查看更新的脚本以及详细说明建议更改的摘要。运行自己的测试后,接受更改,AWS Glue 作业将自动更新为采用新脚本的最新版本。
升级分析过程可能需要一些时间才能完成,具体时间取决于作业的复杂程度和工作负载。升级分析结果将存储在指定的 Amazon S3 路径中,可以查看该路径以了解升级情况和任何潜在的兼容性问题。查看升级分析结果后,您可以决定是继续进行实际升级,还是在升级之前对作业进行任何必要的更改。
先决条件
要在 AWS Glue 中使用生成式人工智能升级作业,需要满足以下先决条件:
-
AWS Glue 2 PySpark 作业:只有 AWS Glue 2 作业可以升级到 AWS Glue 4。
-
需要 IAM 权限才能开始分析、查看结果和升级作业。有关更多信息,请参阅下面权限部分中的示例。
-
如果使用 AWS KMS 加密分析构件或服务来加密用于分析的数据,则需要额外的 AWS KMS 权限。有关更多信息,请参阅下面AWS KMS 策略部分中的示例。
权限
-
使用以下权限调用者的 IAM 策略:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["glue:StartJobUpgradeAnalysis", "glue:StartJobRun", "glue:GetJobRun", "glue:GetJob", "glue:BatchStopJobRun" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:job/jobName" ] }, { "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "<s3 script location associated with the job>" ] }, { "Effect": "Allow", "Action": ["s3:PutObject"], "Resource": [ "<result s3 path provided on API>" ] }, { "Effect": "Allow", "Action": [ "kms:Decrypt", "kms:GenerateDataKey", ], "Resource": "<key-arn-passed in the API>" } ] }注意
如果您使用两个不同的 AWS KMS 密钥,一个用于结果构件加密,另一个用于服务元数据加密,则该策略需要为这两个密钥包含类似的策略。
-
更新要升级的作业的执行角色,包含以下内联策略:
{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "ARN of the Amazon S3 path provided on API", "ARN of the Amazon S3 path provided on API/*" ] }例如,如果您使用 Amazon S3 路径
s3://amzn-s3-demo-bucket/upgraded-result,则该策略将为:{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/", "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/*" ] }
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["glue:GetJobUpgradeAnalysis"],
"Resource": [
"arn:aws:glue:us-east-1:123456789012:job/jobName"
]
}
]
}{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["glue:StopJobUpgradeAnalysis",
"glue:BatchStopJobRun"
],
"Resource": [
"arn:aws:glue:us-east-1:123456789012:job/jobName"
]
}
]
}{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["glue:ListJobUpgradeAnalyses"],
"Resource": [
"arn:aws:glue:us-east-1:123456789012:job/jobName"
]
}
]
}{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["glue:UpdateJob",
"glue:UpgradeJob"
],
"Resource": [
"arn:aws:glue:us-east-1:123456789012:job/jobName"
]
},
{
"Effect": "Allow",
"Action": ["iam:PassRole"],
"Resource": [
"<Role arn associated with the job>"
]
}
]
}AWS KMS 策略
要在开始分析时传递自己的自定义 AWS KMS 密钥,请参阅以下部分以配置对 AWS KMS 密钥的相应权限。
您需要权限(加密/解密)才能传递密钥。在下面的策略示例中,允许通过 <IAM Customer caller ARN> 指定的 AWS 账户或角色执行允许的操作:
-
kms:Decrypt 允许使用指定的 AWS KMS 密钥进行解密。
-
kms:GenerateDataKey 允许使用指定的 AWS KMS 密钥生成数据密钥。
{
"Effect": "Allow",
"Principal":{
"AWS": "<IAM Customer caller ARN>"
},
"Action": [
"kms:Decrypt",
"kms:GenerateDataKey",
],
"Resource": "<key-arn-passed-on-start-api>"
}您需要授予 AWS Glue 使用 AWS KMS 密钥进行密钥加密和解密的权限。
{
"Effect": "Allow",
"Principal":{
"Service": "glue.amazonaws.com"
},
"Action": [
"kms:Decrypt",
"kms:GenerateDataKey",
],
"Resource": "<key-arn>",
"Condition": {
"StringLike": {
"aws:SourceArn": "arn:aws:glue:<region>:<aws_account_id>:job/job-name"
}
}
}此策略可确保您拥有 AWS KMS 密钥的加密和解密权限。
{
"Effect": "Allow",
"Principal":{
"AWS": "<IAM Customer caller ARN>"
},
"Action": [
"kms:Decrypt",
"kms:GenerateDataKey",
],
"Resource": "<key-arn-passed-on-start-api>"
}运行升级分析并应用升级脚本
您可以运行升级分析,这将为您从作业视图中选择的作业生成升级计划。
-
从作业中选择 AWS Glue 2.0 作业,然后从操作菜单中选择运行升级分析。
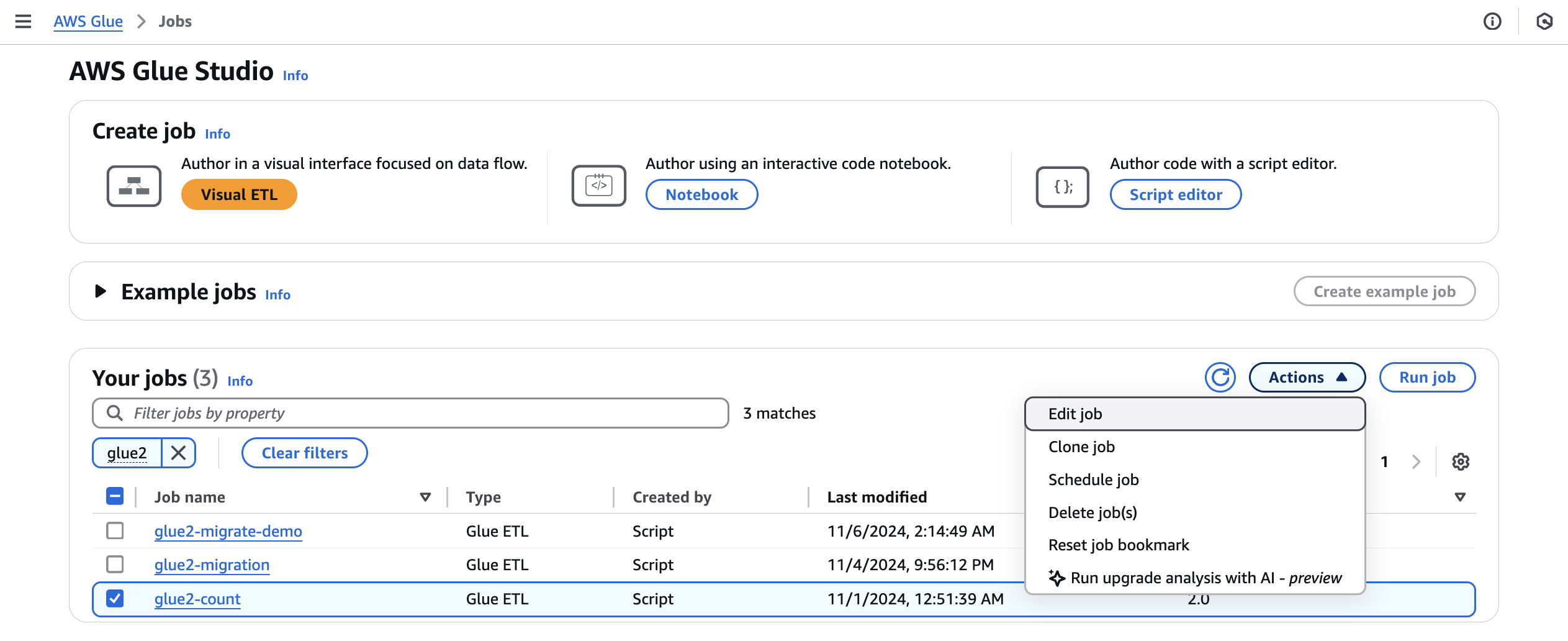
-
在模态中,在结果路径中选择存储生成的升级计划的路径。此路径必须是您可以访问和写入的 Amazon S3 存储桶。
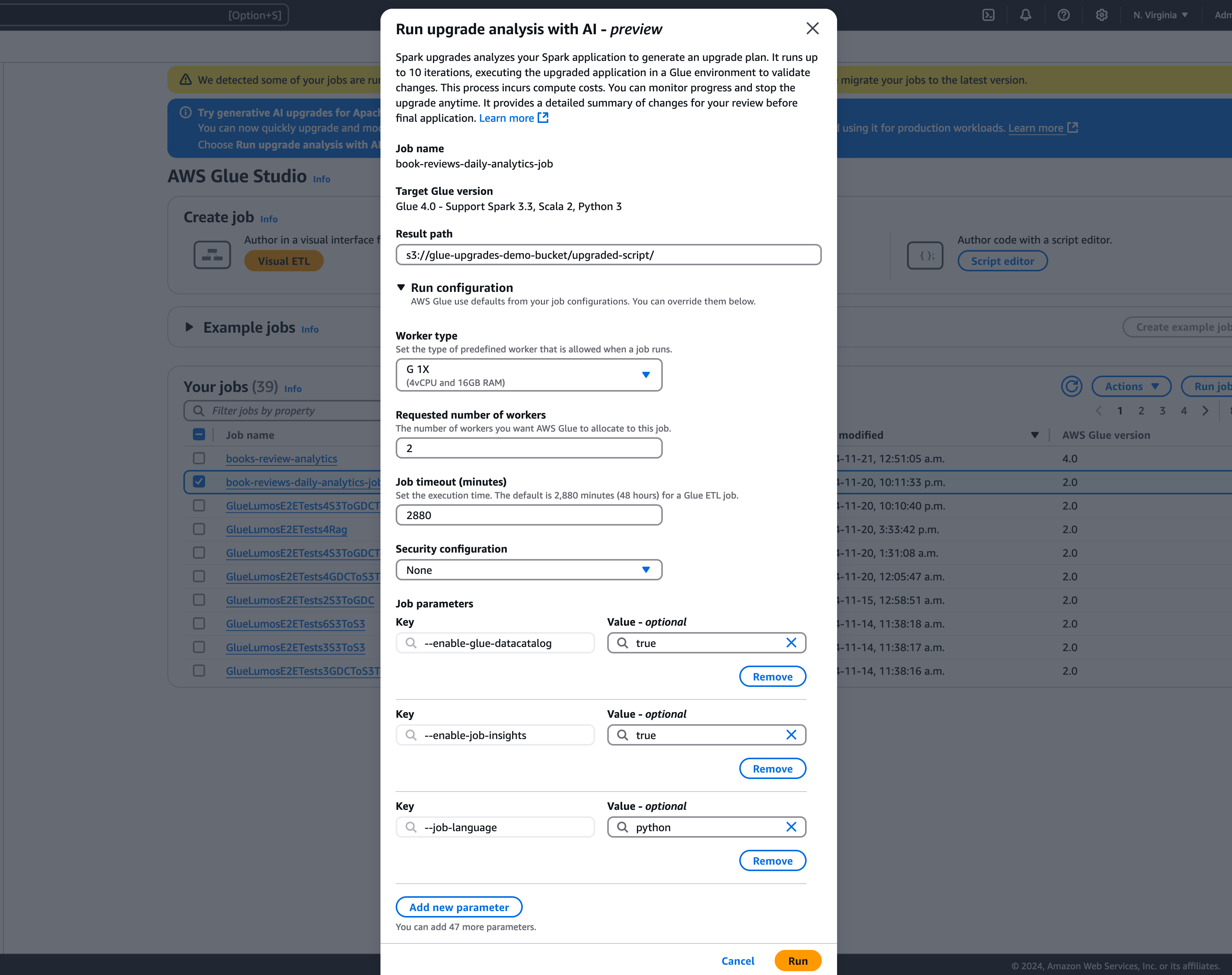
-
如果需要,配置其他选项:
-
运行配置(可选):运行配置是一项可选的设置,允许您自定义升级分析期间执行的验证运行的各个方面。此配置用于执行升级后的脚本,并允许您选择计算环境属性(工作线程类型、工作线程数量等)。请注意,在审查、接受更改并将其应用于生产环境之前,您应该使用非生产开发者账户对示例数据集进行验证。运行配置包括以下可自定义的参数:
-
工作线程类型:您可以指定用于验证运行的工作线程类型,从而允许您根据自己的要求选择适当的计算资源。
-
工作线程数量:您可以定义要为验证运行预置的工作线程数量,从而使您能够根据工作负载需求扩展资源。
-
作业超时(分钟):此参数允许您设置验证运行的时间限制,从而确保作业在指定的持续时间后终止,以防止过度消耗资源。
-
安全配置:您可以配置加密和访问控制等安全设置,以确保在验证运行期间保护您的数据和资源。
-
其他作业参数:如果需要,则您可以添加新的作业参数,以进一步自定义验证运行的执行环境。
通过利用运行配置,您可以量身定制验证运行以满足自己的特定要求。例如,您可以将验证运行配置为使用较小的数据集,这样可以更快地完成分析并优化成本。此方法可确保高效执行升级分析,同时最大限度地降低验证阶段的资源利用率和相关成本。
-
-
加密配置(可选):
-
启用升级构件加密:在将数据写入结果路径时启用静态加密。如果您不想加密升级构件,则请取消选中此选项。
-
自定义服务元数据加密:默认情况下,您的服务元数据使用 AWS 拥有的密钥进行加密。如果您想使用自己的密钥加密,则请选择此选项。
-
-
-
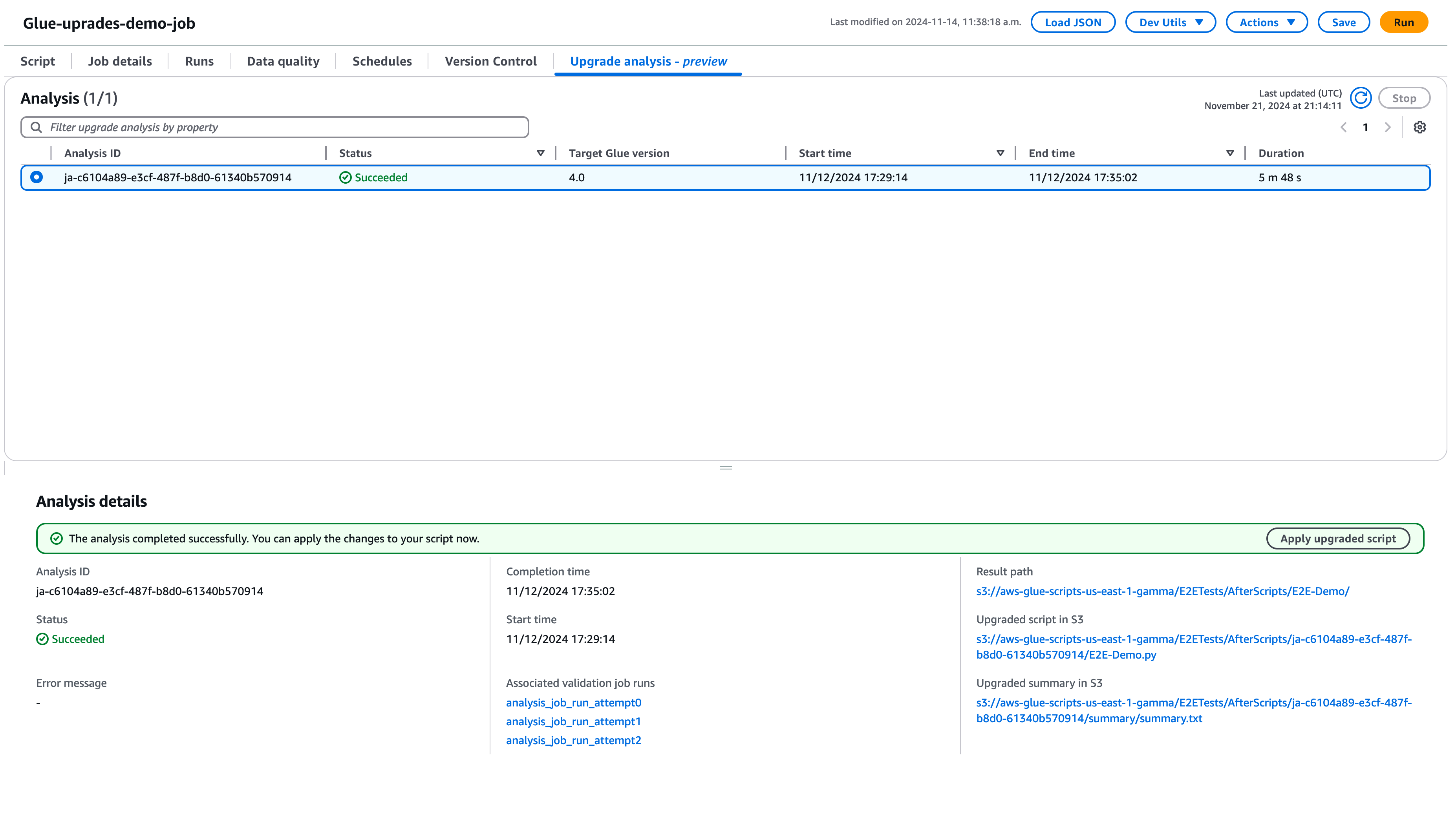
选择运行开始升级分析。分析运行时,您可以在升级分析选项卡中查看结果。分析详细信息窗口将显示有关分析的信息以及指向升级构件的链接。
-
结果路径:此项是存储结果摘要和升级脚本的位置。
-
Amazon S3 中的升级脚本:升级脚本在 Amazon S3 中的位置。您可以在应用升级之前查看该脚本。
-
Amazon S3 中的升级摘要:升级摘要在 Amazon S3 中的位置。您可以在应用升级之前查看升级摘要。
-
-
成功完成升级分析后,您可以通过选择应用升级的脚本,应用升级的脚本以自动升级作业。
应用后,AWS Glue 版本将更新为 4.0。您可以在脚本选项卡中查看新脚本。
了解升级摘要
此示例演示将 AWS Glue 作业从 2.0 版升级到 4.0 版的过程。该示例作业从 Amazon S3 存储桶读取产品数据,使用 Spark SQL 对数据进行多次转换,然后将转换后的结果保存回 Amazon S3 存储桶。
from awsglue.transforms import *
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from pyspark.sql.types import *
from pyspark.sql.functions import *
from awsglue.job import Job
import json
from pyspark.sql.types import StructType
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/"
schema_location = (
"s3://aws-glue-scripts-us-east-1-gamma/DataFiles/"
)
products_schema_string = spark.read.text(
f"{schema_location}schemas/products_schema"
).first()[0]
product_schema = StructType.fromJson(json.loads(products_schema_string))
products_source_df = (
spark.read.option("header", "true")
.schema(product_schema)
.option(
"path",
f"{gdc_database}products/",
)
.csv(f"{gdc_database}products/")
)
products_source_df.show()
products_temp_view_name = "spark_upgrade_demo_product_view"
products_source_df.createOrReplaceTempView(products_temp_view_name)
query = f"select {products_temp_view_name}.*, format_string('%0$s-%0$s', category, subcategory) as unique_category from {products_temp_view_name}"
products_with_combination_df = spark.sql(query)
products_with_combination_df.show()
products_with_combination_df.createOrReplaceTempView(products_temp_view_name)
product_df_attribution = spark.sql(
f"""
SELECT *,
unbase64(split(product_name, ' ')[0]) as product_name_decoded,
unbase64(split(unique_category, '-')[1]) as subcategory_decoded
FROM {products_temp_view_name}
"""
)
product_df_attribution.show()
product_df_attribution.write.mode("overwrite").option("header", "true").option(
"path", f"{gdc_database}spark_upgrade_demo_product_agg/"
).saveAsTable("spark_upgrade_demo_product_agg", external=True)
spark_upgrade_demo_product_agg_table_df = spark.sql(
f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'"
)
spark_upgrade_demo_product_agg_table_df.show()
job.commit()from awsglue.transforms import *
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from pyspark.sql.types import *
from pyspark.sql.functions import *
from awsglue.job import Job
import json
from pyspark.sql.types import StructType
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
# change 1
spark.conf.set("spark.sql.adaptive.enabled", "false")
# change 2
spark.conf.set("spark.sql.legacy.pathOptionBehavior.enabled", "true")
job = Job(glueContext)
gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/"
schema_location = (
"s3://aws-glue-scripts-us-east-1-gamma/DataFiles/"
)
products_schema_string = spark.read.text(
f"{schema_location}schemas/products_schema"
).first()[0]
product_schema = StructType.fromJson(json.loads(products_schema_string))
products_source_df = (
spark.read.option("header", "true")
.schema(product_schema)
.option(
"path",
f"{gdc_database}products/",
)
.csv(f"{gdc_database}products/")
)
products_source_df.show()
products_temp_view_name = "spark_upgrade_demo_product_view"
products_source_df.createOrReplaceTempView(products_temp_view_name)
# change 3
query = f"select {products_temp_view_name}.*, format_string('%1$s-%1$s', category, subcategory) as unique_category from {products_temp_view_name}"
products_with_combination_df = spark.sql(query)
products_with_combination_df.show()
products_with_combination_df.createOrReplaceTempView(products_temp_view_name)
# change 4
product_df_attribution = spark.sql(
f"""
SELECT *,
try_to_binary(split(product_name, ' ')[0], 'base64') as product_name_decoded,
try_to_binary(split(unique_category, '-')[1], 'base64') as subcategory_decoded
FROM {products_temp_view_name}
"""
)
product_df_attribution.show()
product_df_attribution.write.mode("overwrite").option("header", "true").option(
"path", f"{gdc_database}spark_upgrade_demo_product_agg/"
).saveAsTable("spark_upgrade_demo_product_agg", external=True)
spark_upgrade_demo_product_agg_table_df = spark.sql(
f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'"
)
spark_upgrade_demo_product_agg_table_df.show()
job.commit()
根据摘要,AWS Glue 提出了四项更改,以便将脚本从 AWS Glue 2.0 成功升级到 AWS Glue 4.0:
-
Spark SQL 配置(spark.sql.adaptive.enabled):由于从 Spark 3.2 开始引入了 Spark SQL 自适应查询执行的新功能,此更改旨在恢复应用程序行为。您可以检查此配置更改,并可以根据其偏好进一步启用或禁用它。
-
DataFrame API 更改:路径选项不能与
load()等其他 DataFrameReader 操作共存。为保留之前的行为,AWS Glue 更新了该脚本以添加新的 SQL 配置(spark.sql.legacy.pathOptionBehavior.enabled)。 -
Spark SQL API 更改:
format_string(strfmt, obj, ...)中strfmt的行为已更新为不允许0$作为第一个参数。为确保兼容性,AWS Glue 修改了该脚本以使用1$作为第一个参数。 -
Spark SQL API 更改:
unbase64函数不允许输入格式错误的字符串。为了保留之前的行为,AWS Glue 更新了该脚本以使用try_to_binary函数。
根据摘要,AWS Glue 提出了四项更改,以便将脚本从 AWS Glue 2.0 成功升级到 AWS Glue 4.0:
-
Spark SQL 配置(spark.sql.adaptive.enabled):由于从 Spark 3.2 开始引入了 Spark SQL 自适应查询执行的新功能,此更改旨在恢复应用程序行为。您可以检查此配置更改,并可以根据其偏好进一步启用或禁用它。
-
DataFrame API 更改:路径选项不能与
load()等其他 DataFrameReader 操作共存。为保留之前的行为,AWS Glue 更新了该脚本以添加新的 SQL 配置(spark.sql.legacy.pathOptionBehavior.enabled)。 -
Spark SQL API 更改:
format_string(strfmt, obj, ...)中strfmt的行为已更新为不允许0$作为第一个参数。为确保兼容性,AWS Glue 修改了该脚本以使用1$作为第一个参数。 -
Spark SQL API 更改:
unbase64函数不允许输入格式错误的字符串。为了保留之前的行为,AWS Glue 更新了该脚本以使用try_to_binary函数。
停止正在进行的升级分析
您可以取消正在进行的升级分析,也可以直接停止分析。
-
选择升级分析选项卡。
-
选择正在运行的作业,然后选择停止。这将停止分析。然后,您可以对同一作业进行其他升级分析。

注意事项
在预览期间开始使用 Spark 升级功能时,要优化使用服务,需要考虑几个重要方面。
-
服务范围和限制:预览版专注于从 AWS Glue 2.0 版到 4.0 版的 PySpark 代码升级。目前,该服务处理不依赖于其他库依赖项的 PySpark 代码。您可以在一个 AWS 账户中同时运行最多 10 个作业的自动升级,从而在保持系统稳定性的同时高效升级多个作业。
-
仅支持 PySpark 作业。
-
升级分析将在 24 小时后超时。
-
一个作业一次只能运行一个主动升级分析。在账户级别,最多可以同时运行 10 个主动升级分析。
-
-
在升级过程中优化成本:由于 Spark 升级功能使用生成式人工智能通过多次迭代来验证升级计划,并且每次迭代都在您的账户中以 AWS Glue 作业的形式运行,因此优化验证作业运行配置以实现成本效率至关重要。为此,建议在开始升级分析时指定运行配置如下:
-
使用非生产开发者账户,选择代表您的生产数据但规模较小的示例模拟数据集,以使用 Spark 升级功能进行验证。
-
使用规模合适的计算资源,例如 G.1X 工作线程,并选择适当数量的工作线程来处理您的示例数据。
-
在适用时启用 AWS Glue 作业自动扩缩功能,以根据工作负载自动调整资源。
例如,如果您的生产作业使用 20 个 G.2X 工作线程处理数 TB 的数据,则可以将升级作业配置为使用 2 个 G.2X 工作线程中处理几 GB 的代表性数据,并启用自动扩缩以进行验证。
-
-
预览最佳实践:在预览期间,强烈建议您从非生产作业开始升级之旅。这种方法使您可以熟悉升级工作流,并了解该服务如何处理不同类型的 Spark 代码模式。
-
警报和通知:对作业使用生成式人工智能升级功能时,请确保关闭作业运行失败的警报/通知。在升级过程中,提供升级的构件之前,您的账户中最多可有 10 次失败的作业运行。
-
异常检测规则:关闭对进行升级的作业的任何异常检测规则,因为在进行升级验证时,中间作业运行期间写入输出文件夹的数据可能并非预期的格式。
Spark Upgrades 中的跨区域推理
Spark Upgrades 由 Amazon Bedrock 提供支持并利用跨区域推理 (CRIS)。利用 CRIS,Spark Upgrades 将自动选择您所在地理位置的最佳区域(详见此处)来处理您的推理请求,最大限度地提高可用计算资源和模型可用性,并提供最佳客户体验。使用跨区域推理不会产生额外成本。
跨区域推理请求保留在属于数据原始所在地理位置的 AWS 区域内。例如,在美国境内提出的请求将保留在美国境内的 AWS 区域内。尽管数据仍然只存储在主区域中,但在使用跨区域推理时,您的输入提示和输出结果可能会移出主区域。所有数据都将通过 Amazon 的安全网络进行加密传输。
