您可以在 AWS Glue 中调试内存不足 (OOM) 异常和作业异常。以下部分介绍用于调试 Apache Spark 驱动程序或 Spark 执行程序的内存不足异常的方案。
调试驱动程序 OOM 异常
在这种情况下,Spark 任务从 Amazon Simple Storage Service(Amazon S3)中读取大量小文件。它会将这些文件转换为 Apache Parquet 格式,然后将其写出到 Amazon S3。Spark 驱动程序内存不足。输入 Amazon S3 数据在各 Amazon S3 分区中的文件数量已超过 100 万个。
配置的代码如下所示:
data = spark.read.format("json").option("inferSchema", False).load("s3://input_path")
data.write.format("parquet").save(output_path)
在 AWS Glue 控制台上可视化分析指标
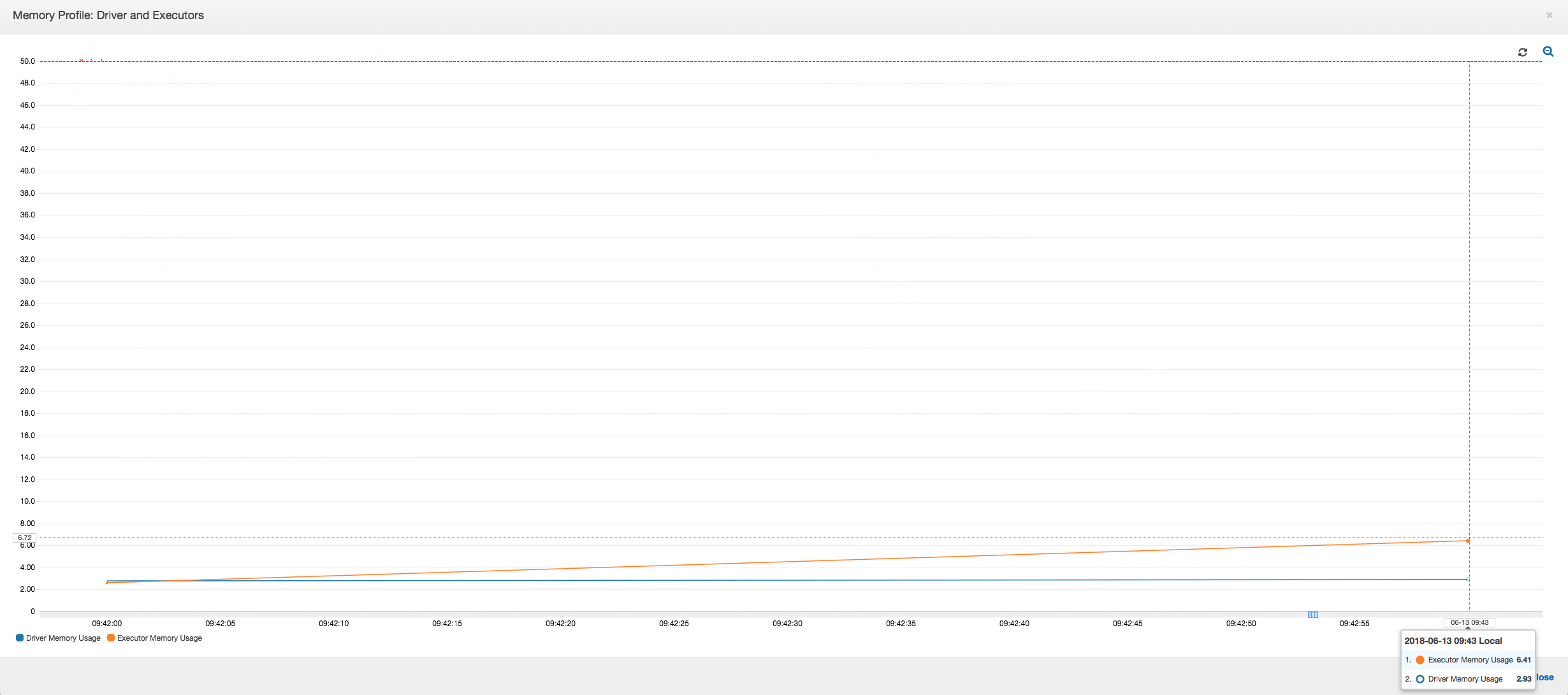
下图显示了以驱动程序和执行程序的百分比表示的内存使用率。此使用率绘制为一个数据点,它是上一分钟报告的值的平均数。您可以在作业的内存配置文件中看到驱动程序内存快速超过 50% 使用率的安全阈值。另一方面,所有执行程序的平均内存使用率仍低于 4%。这清楚地显示了此 Spark 作业中驱动程序执行的异常。
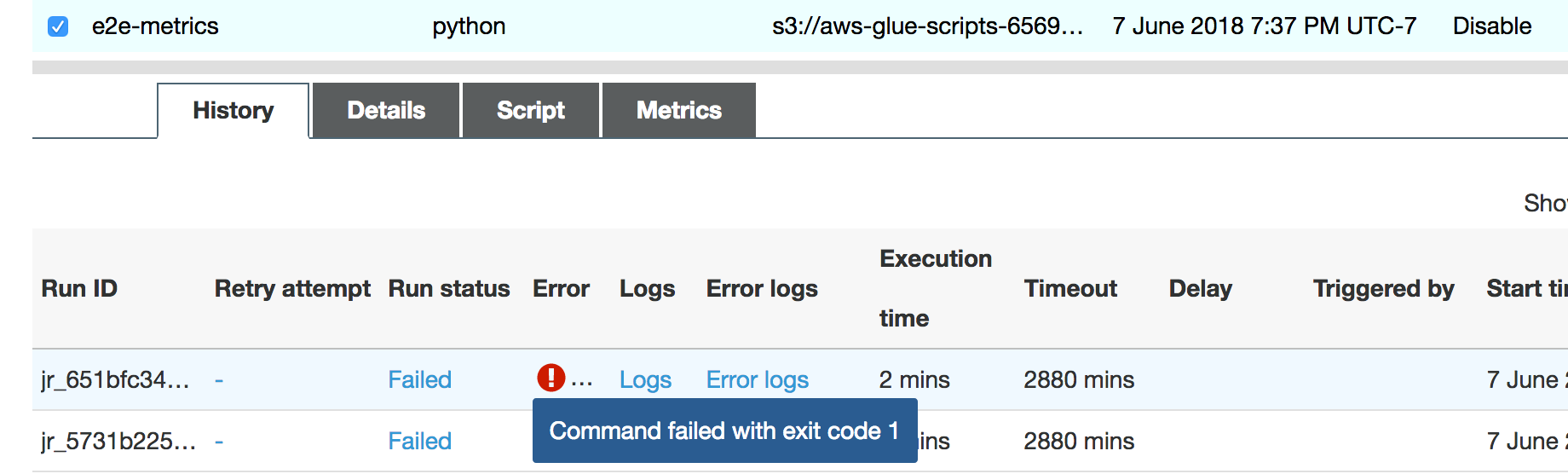
该作业运行很快失败,并在 控制台上的历史记录AWS Glue选项卡中出现以下错误:Command Failed with Exit Code 1 (命令失败,退出代码 1)。此错误字符串表示任务由于系统错误而失败 – 在此示例中,该错误为驱动程序内存不足。
在控制台上,选择 History (历史记录) 选项卡上的 Error logs (错误日志) 链接以确认 CloudWatch Logs 中有关驱动程序 OOM 的查找结果。在作业的错误日志中搜索“Error”以确认确实是 OOM 异常使作业失败:
# java.lang.OutOfMemoryError: Java heap space
# -XX:OnOutOfMemoryError="kill -9 %p"
# Executing /bin/sh -c "kill -9 12039"...
在作业的历史记录选项卡上,选择日志。您可以在任务开始时在 CloudWatch Logs 中找到驱动程序执行的以下跟踪。Spark 驱动程序尝试列出所有目录中的所有文件,构造 InMemoryFileIndex,并为每个文件启动一个任务。这进而会导致 Spark 驱动程序必须在内存中维持大量状态以跟踪所有任务。它会缓存内存索引的大量文件的完整列表,从而导致驱动程序 OOM。
使用分组修复多个文件的处理
您可以通过使用 . 中的分组AWS Glue 功能修复多个文件的处理。使用动态帧时以及输入数据集包含大量文件(超过 50,000 个)时,将自动启用分组功能。分组使您可以将多个文件合并到一个组中,并且允许任务处理整个组而非单个文件。因此,Spark 驱动程序在内存中存储显著减少的状态以跟踪较少的任务。有关手动为数据集启用分组的更多信息,请参阅以较大的组读取输入文件。
要检查 AWS Glue 作业的内存配置文件,请在启用分组的情况下配置以下代码:
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json")
datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
您可以在 AWS Glue 作业配置文件中监控内存配置文件和 ETL 数据移动。
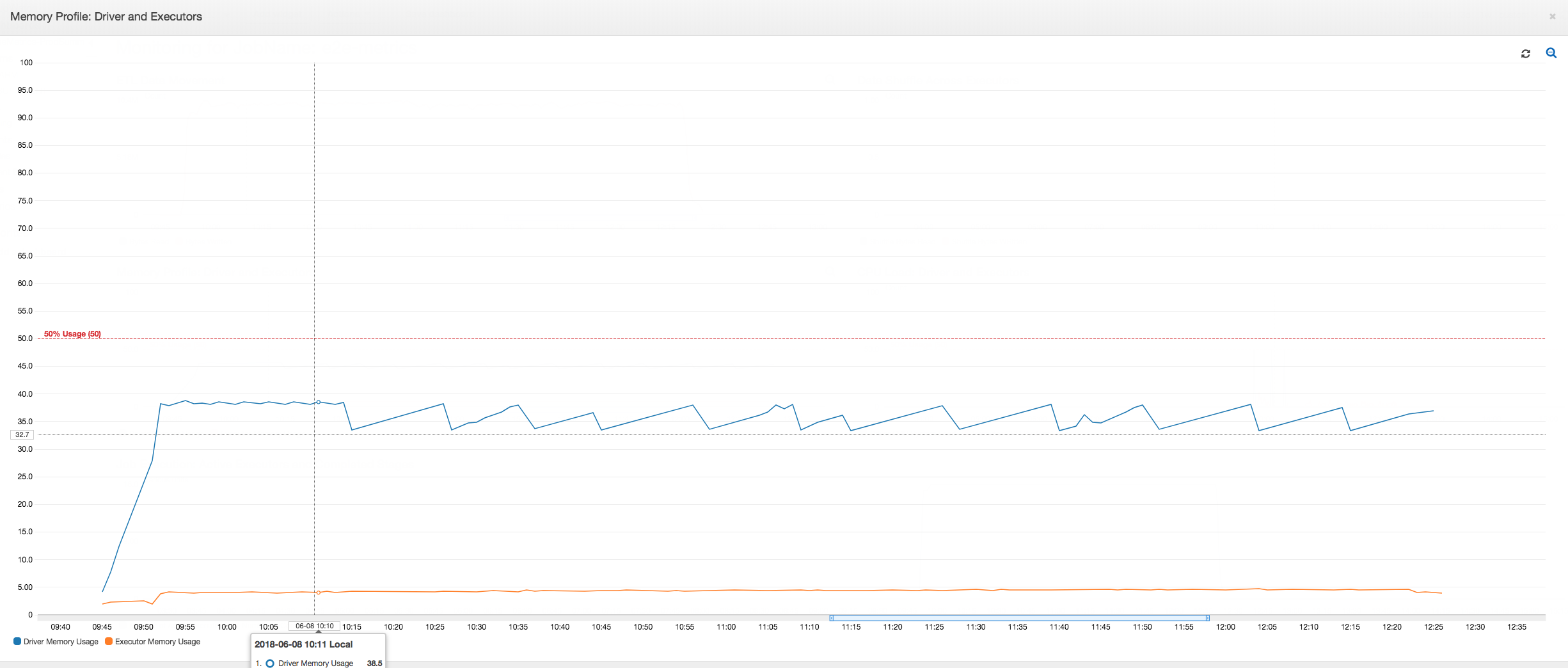
在 AWS Glue 任务的整个持续时间内,驱动程序在低于 50% 内存使用率的阈值下运行。执行程序从 Amazon S3 流式传输数据,对其进行处理,然后将其写出到 Amazon S3。因此,它们在任何时间点消耗的内存不到 5%。
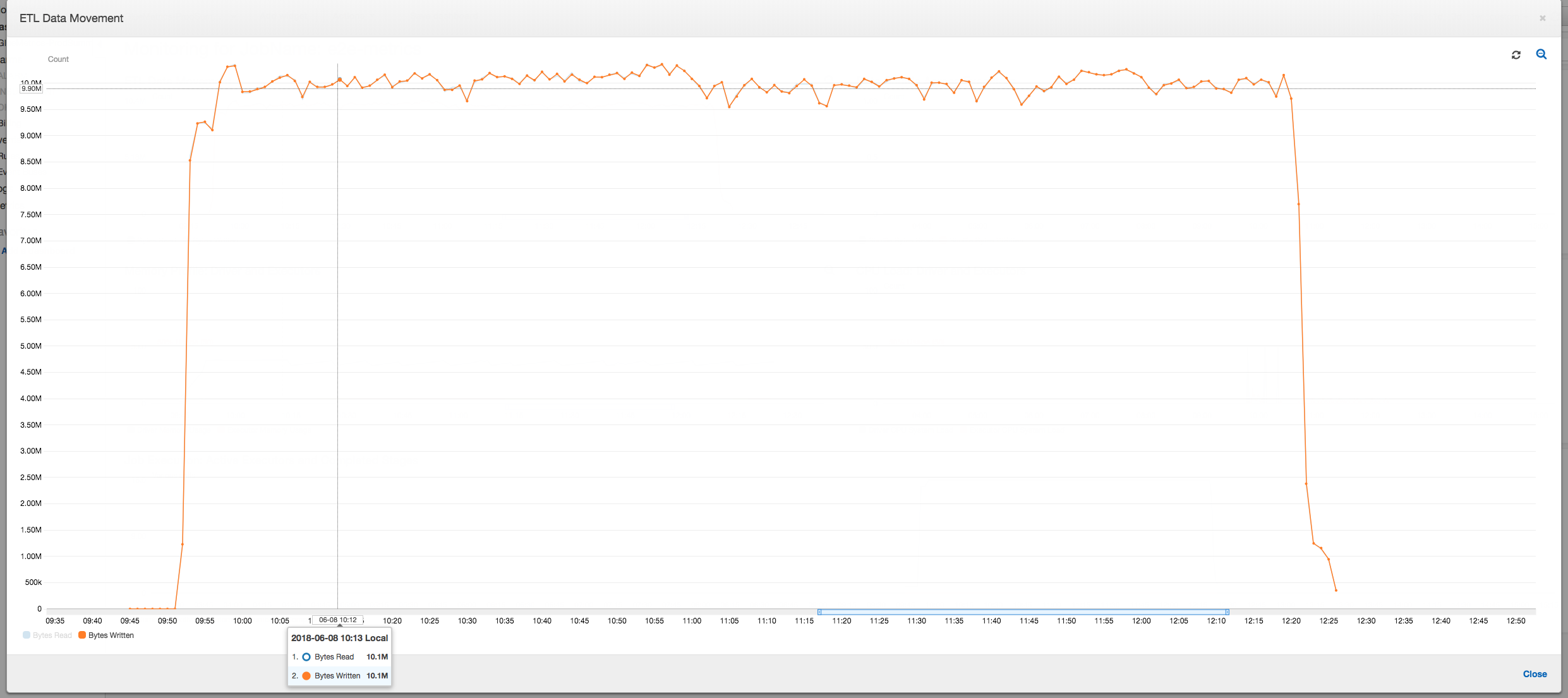
下面的数据移动配置文件显示了任务进行时所有执行程序在最后一分钟内读取和写入的 Amazon S3 字节总数。两者当数据在所有执行程序中流式传输时都遵循类似的模式。该作业在不到三个小时内完成处理所有一百万个文件。
调试执行程序 OOM 异常
在此方案中,您可以了解如何调试 Apache Spark 执行程序中可能出现的 OOM 异常。以下代码使用 Spark 的 MySQL 读取器将大约 3400 万行的一个大型表读入 Spark 数据帧中。然后它以 Parquet 格式将其写出到 Amazon S3。您可以提供连接属性,并使用默认 Spark 配置来读取表。
val connectionProperties = new Properties()
connectionProperties.put("user", user)
connectionProperties.put("password", password)
connectionProperties.put("Driver", "com.mysql.jdbc.Driver")
val sparkSession = glueContext.sparkSession
val dfSpark = sparkSession.read.jdbc(url, tableName, connectionProperties)
dfSpark.write.format("parquet").save(output_path)
在 AWS Glue 控制台上可视化分析指标
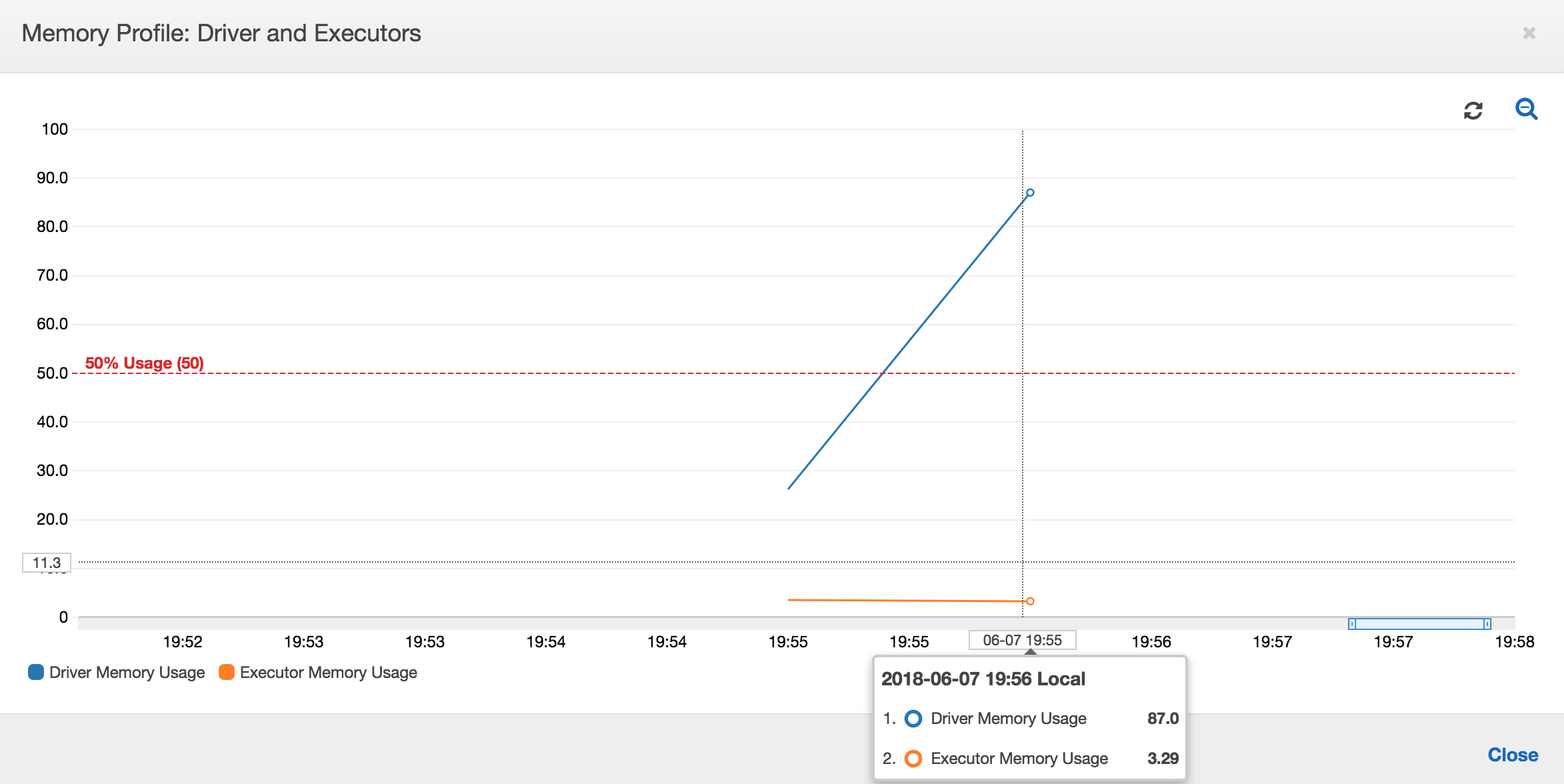
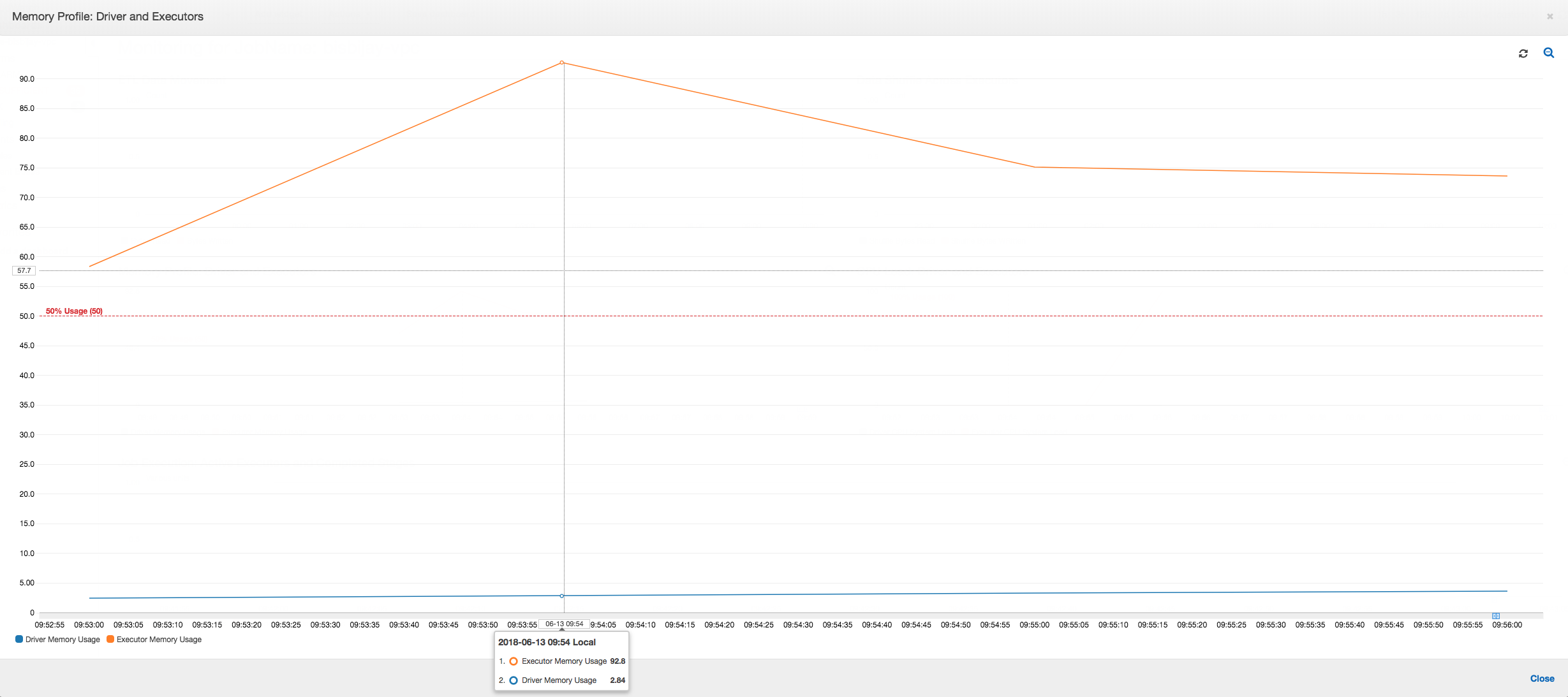
如果内存使用情况图的斜率为正且超过 50%,则如果作业在发出下一个衡量指标之前失败,那么内存耗尽是一个很好的候选原因。下图显示了在执行的一分钟内,所有执行程序的平均内存使用率快速超过 50%。使用率高达 92%,而且运行执行程序的容器被 Apache Hadoop YARN 停止。
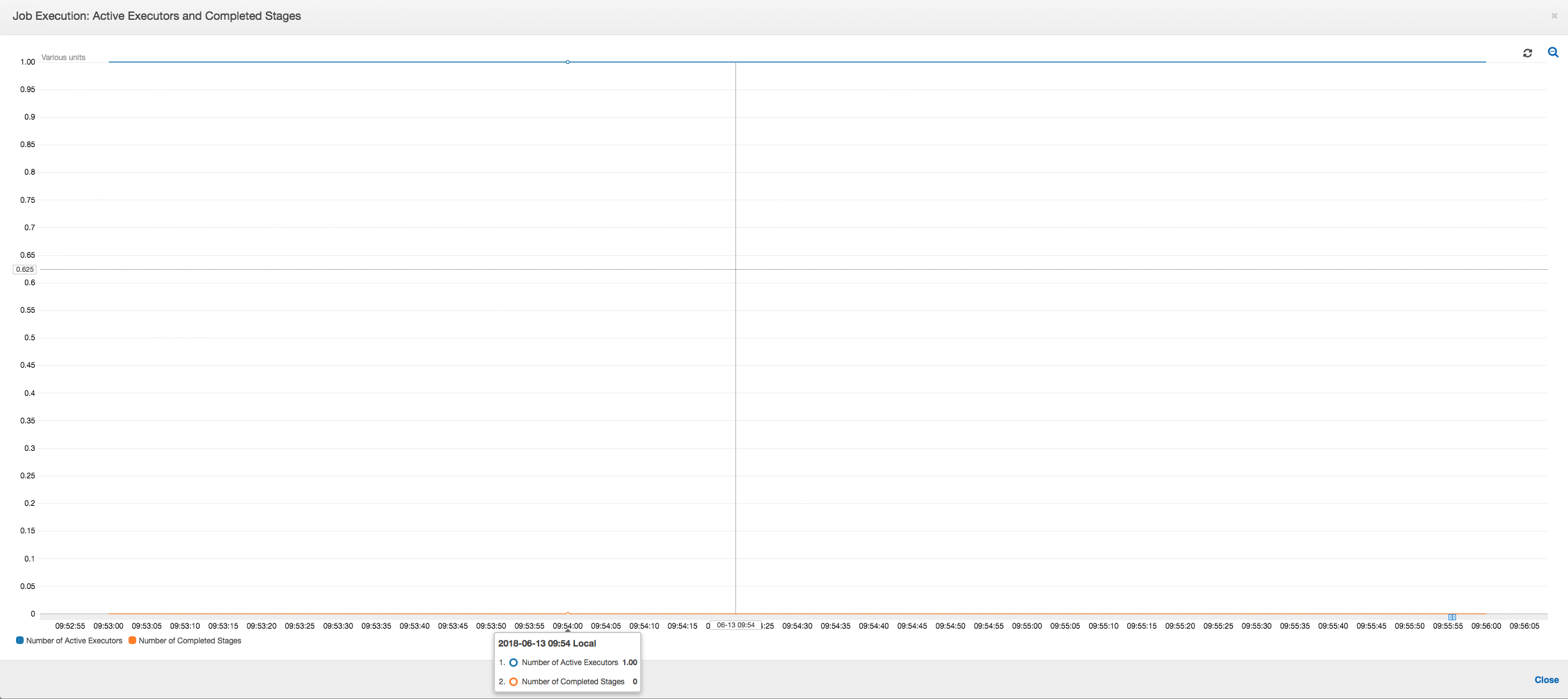
如下图所示,在作业失败之前始终会有单个执行程序在运行。这是因为启动了新的执行程序以替换停止的执行程序。默认情况下,不会并行读取 JDBC 数据源,因为它需要对表中的列进行分区并打开多个连接。因此,只有一个执行程序按顺序读入整个表。
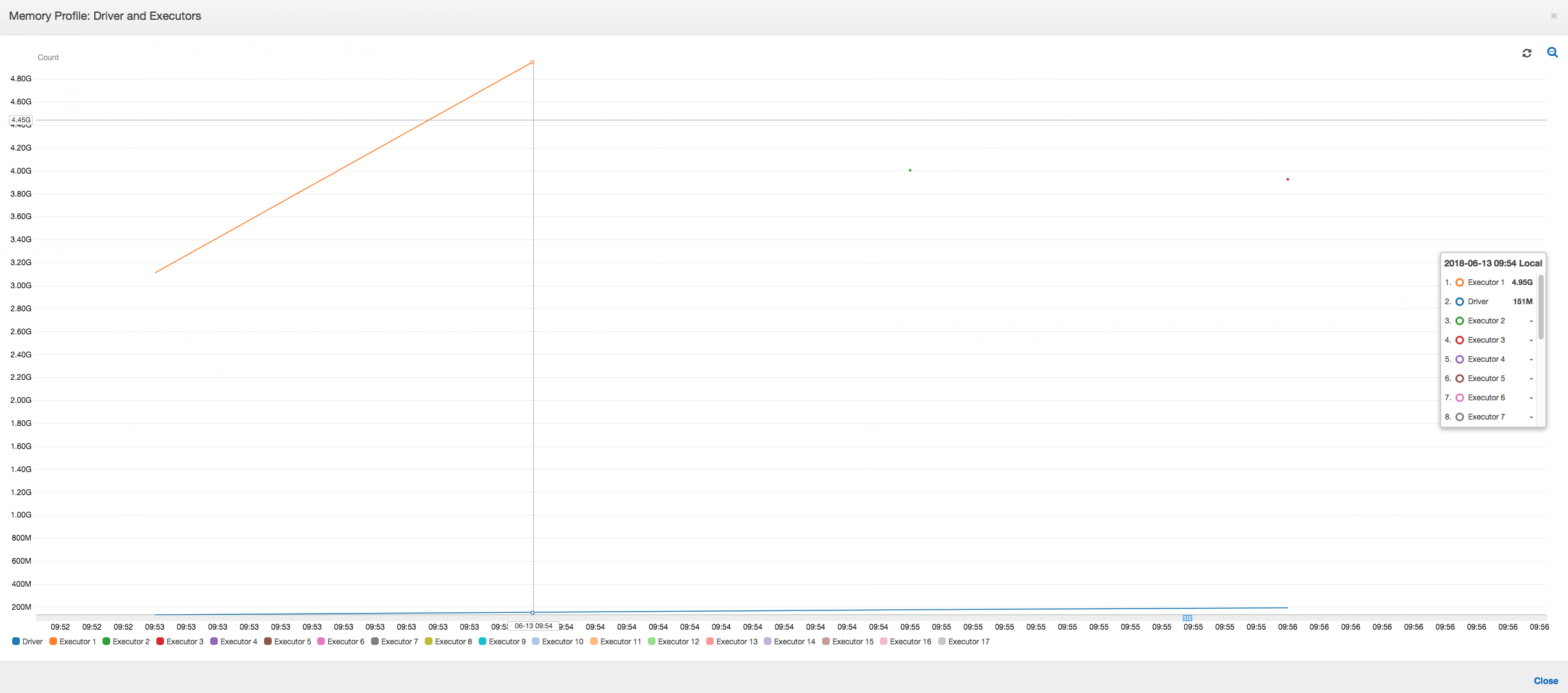
如下图所示,Spark 尝试在作业失败之前四次启动新任务。您可以看到三个执行程序的内存配置文件。每个执行程序都会快速耗尽其所有内存。第四个执行程序内存不足,作业失败。因此,不会立即报告其指标。
您可以从 AWS Glue 控制台上的错误字符串确认作业因 OOM 异常而失败,如下图所示。

任务输出日志:要进一步确认执行程序 OOM 异常这一发现,请查看 CloudWatch Logs。当您搜索 Error 时,您会发现四个执行程序在指标控制面板上显示的大致相同的时间段内被停止。所有执行程序均被 YARN 终止,因为它们超出其内存限制。
执行程序 1
18/06/13 16:54:29 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/06/13 16:54:29 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/06/13 16:54:29 ERROR YarnClusterScheduler: Lost executor 1 on ip-10-1-2-175.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/06/13 16:54:29 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, ip-10-1-2-175.ec2.internal, executor 1): ExecutorLostFailure (executor 1 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.执行程序 2
18/06/13 16:55:35 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/06/13 16:55:35 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/06/13 16:55:35 ERROR YarnClusterScheduler: Lost executor 2 on ip-10-1-2-16.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/06/13 16:55:35 WARN TaskSetManager: Lost task 0.1 in stage 0.0 (TID 1, ip-10-1-2-16.ec2.internal, executor 2): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.执行程序 3
18/06/13 16:56:37 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/06/13 16:56:37 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/06/13 16:56:37 ERROR YarnClusterScheduler: Lost executor 3 on ip-10-1-2-189.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/06/13 16:56:37 WARN TaskSetManager: Lost task 0.2 in stage 0.0 (TID 2, ip-10-1-2-189.ec2.internal, executor 3): ExecutorLostFailure (executor 3 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.执行程序 4
18/06/13 16:57:18 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/06/13 16:57:18 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/06/13 16:57:18 ERROR YarnClusterScheduler: Lost executor 4 on ip-10-1-2-96.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
18/06/13 16:57:18 WARN TaskSetManager: Lost task 0.3 in stage 0.0 (TID 3, ip-10-1-2-96.ec2.internal, executor 4): ExecutorLostFailure (executor 4 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.使用 AWS Glue 动态帧修复提取大小设置
执行程序在读取 JDBC 表时内存不足,因为 Spark JDBC 提取大小的默认配置为零。这意味着 Spark 执行程序上的 JDBC 驱动程序尝试从数据库中一起提取 3400 万行并对其进行缓存,即使 Spark 一次流式传输一行。使用 Spark,您可以通过将提取大小参数设置为非零默认值来避免此情况。
您还可以通过使用 AWS Glue 动态帧修复此问题。默认情况下,动态帧使用 1000 行的提取大小,这通常是一个足够的值。因此,执行程序不会占用其总内存的 7% 以上。AWS Glue 作业只需单个执行程序即可在不到两分钟内完成。虽然建议的方法是使用 AWS Glue 动态帧,但也可以使用 Apache Spark fetchsize 属性设置提取大小。请参阅 Spark SQL、DataFrame 和 Dataset 指南
val (url, database, tableName) = {
("jdbc_url", "db_name", "table_name")
}
val source = glueContext.getSource(format, sourceJson)
val df = source.getDynamicFrame
glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")正常的分析指标:具有 动态帧的执行程序内存AWS Glue永远不会超过安全阈值,如下图所示。它在数据库的行中流式传输数据,并且在任何时间点在 JDBC 驱动程序中仅缓存 1,000 行。不会发生内存不足异常。