借助 AWS Glue 中的 Amazon Q 数据集成,您可以在 Amazon Q 面板中输入问题。您可以输入有关 AWS Glue 所提供数据集成功能的问题。系统将返回详细答案以及参考文档。
另一个用例是生成 AWS Glue ETL 作业脚本。您可以询问有关如何执行数据提取、转换、加载作业的问题。系统将返回生成的 PySpark 脚本。
Amazon Q 聊天互动
在 AWS Glue 控制台上,开始编写一个新作业,并询问 Amazon Q:“创建一个 Glue ETL 流,连接到我的数据库 glue_db 中的两个 Glue 目录表 venue 和 event,将结果联接到 venue 的 venueid 和 event 的 e_venueid,然后根据 venuestate=='DC' 条件筛选 venue 状态,并以 CSV 格式写入 s3://amzn-s3-demo-bucket/codegen/BDB-9999/output/。”
您会注意到代码已生成。通过此回复,您可以学习和理解如何为自己的目的编写 AWS Glue 代码。您可以将生成的代码复制/粘贴到脚本编辑器中并配置占位符。在作业上配置 IAM 角色和 AWS Glue 连接后,保存并运行该作业。当作业完成后,您可以验证摘要数据是否按预期保存到 Amazon S3 并可供您的下游工作负载使用。
AWS Glue Studio 笔记本交互
注意
AWS Glue Studio 笔记本中的 Amazon Q 数据集成体验仍然侧重于基于 DynamicFrame 的数据集成流。
添加一个新单元格并输入您的评论以描述您想要实现的目标。按下 Tab 键和 Enter 键后,系统将显示建议的代码。
第一个意图是提取数据:“请提供用于读取 Glue Data Catalog 表的代码”,接着是“请提供用于应用筛选转换的代码,筛选条件为 star_rating>3”,以及“请提供将数据帧写入 S3 并保存为 Parquet 格式的代码”。
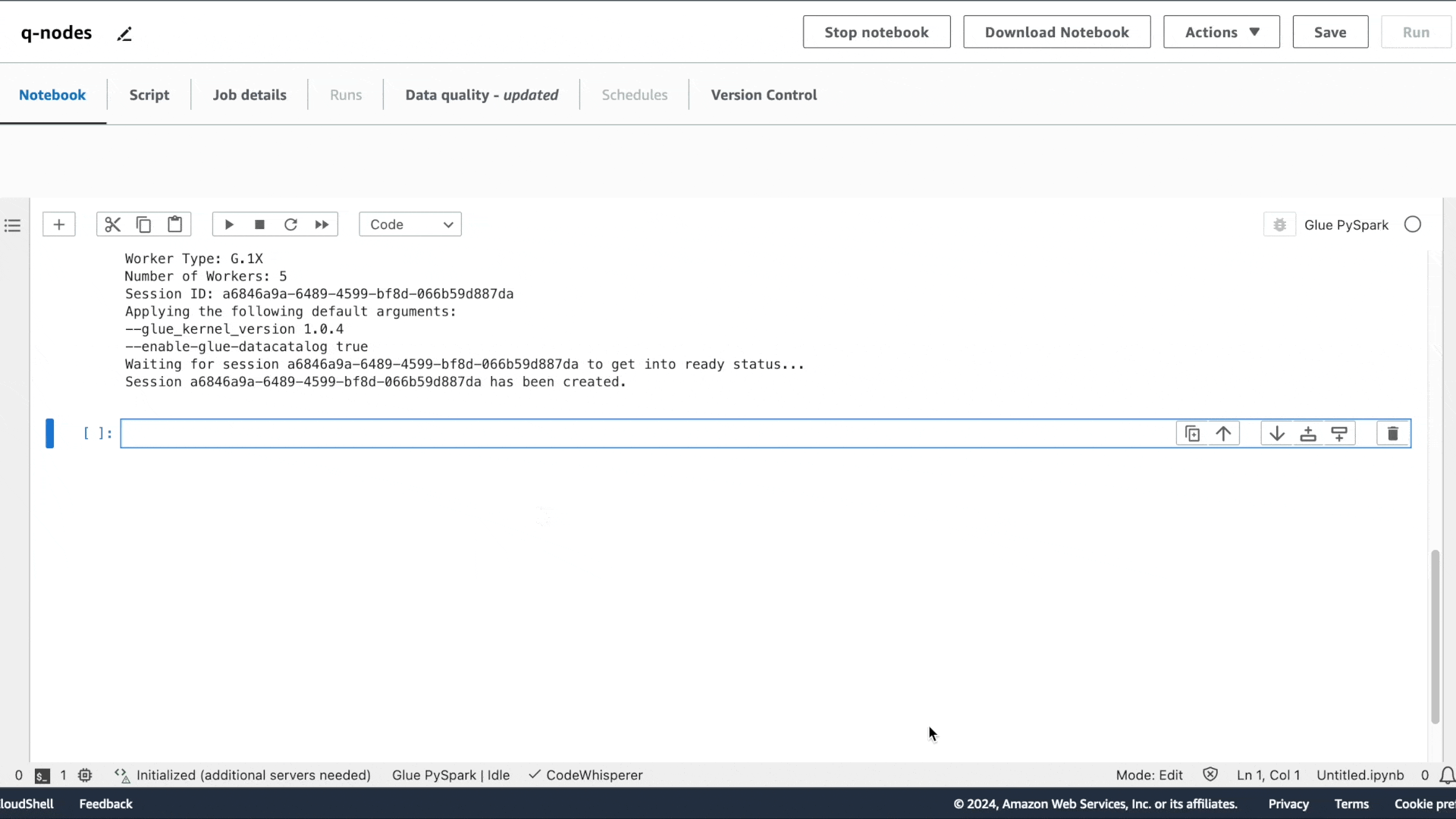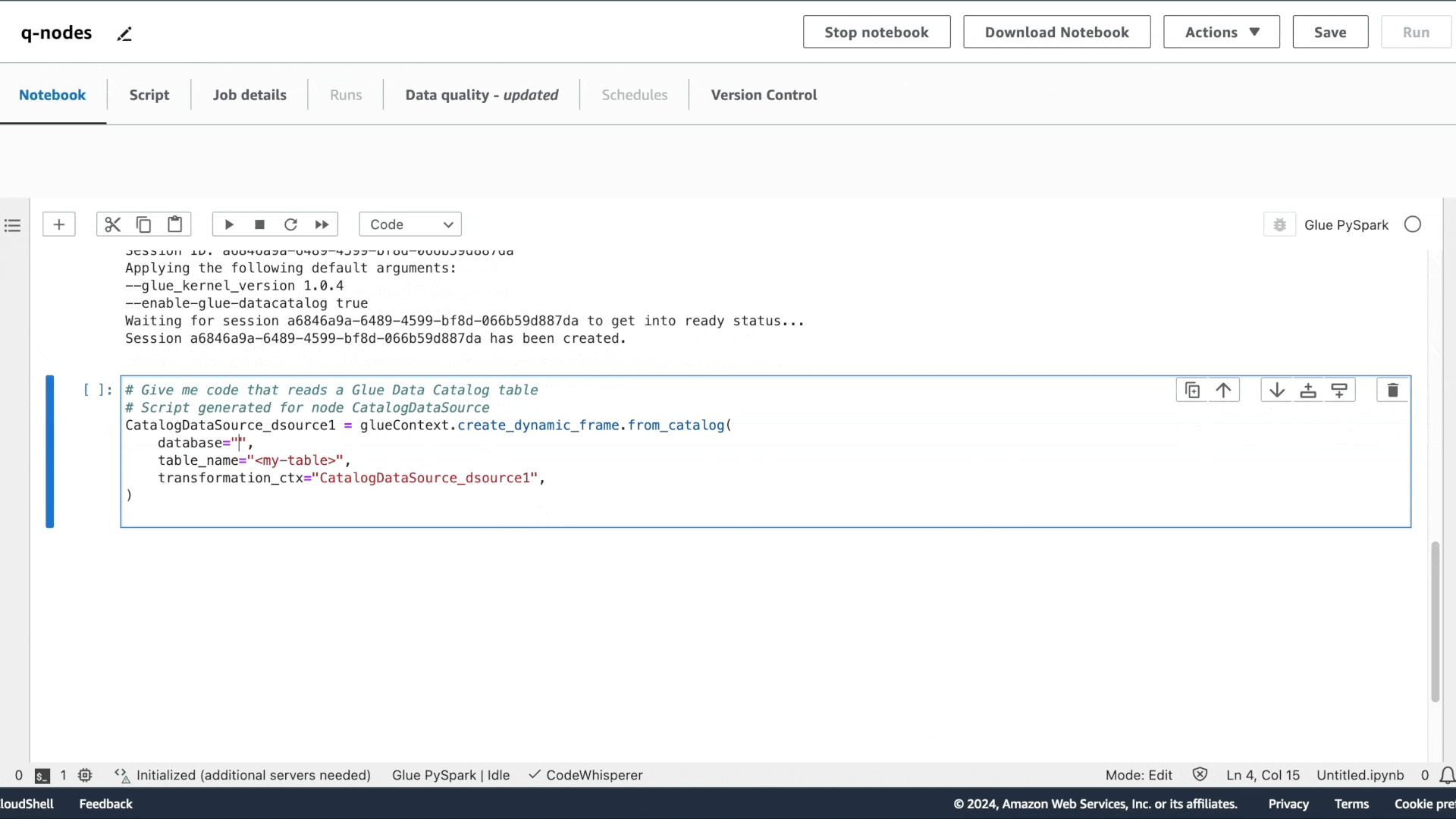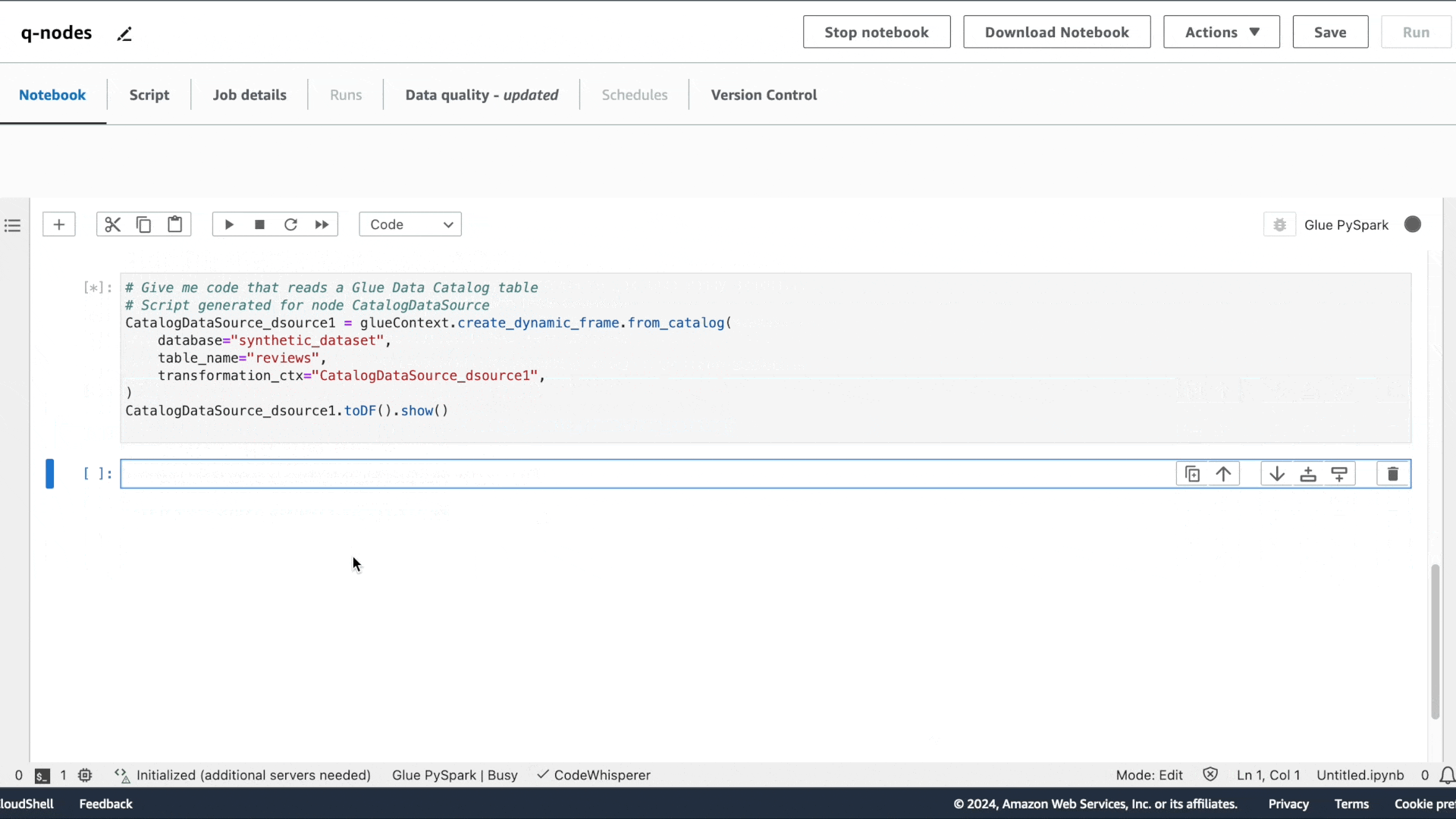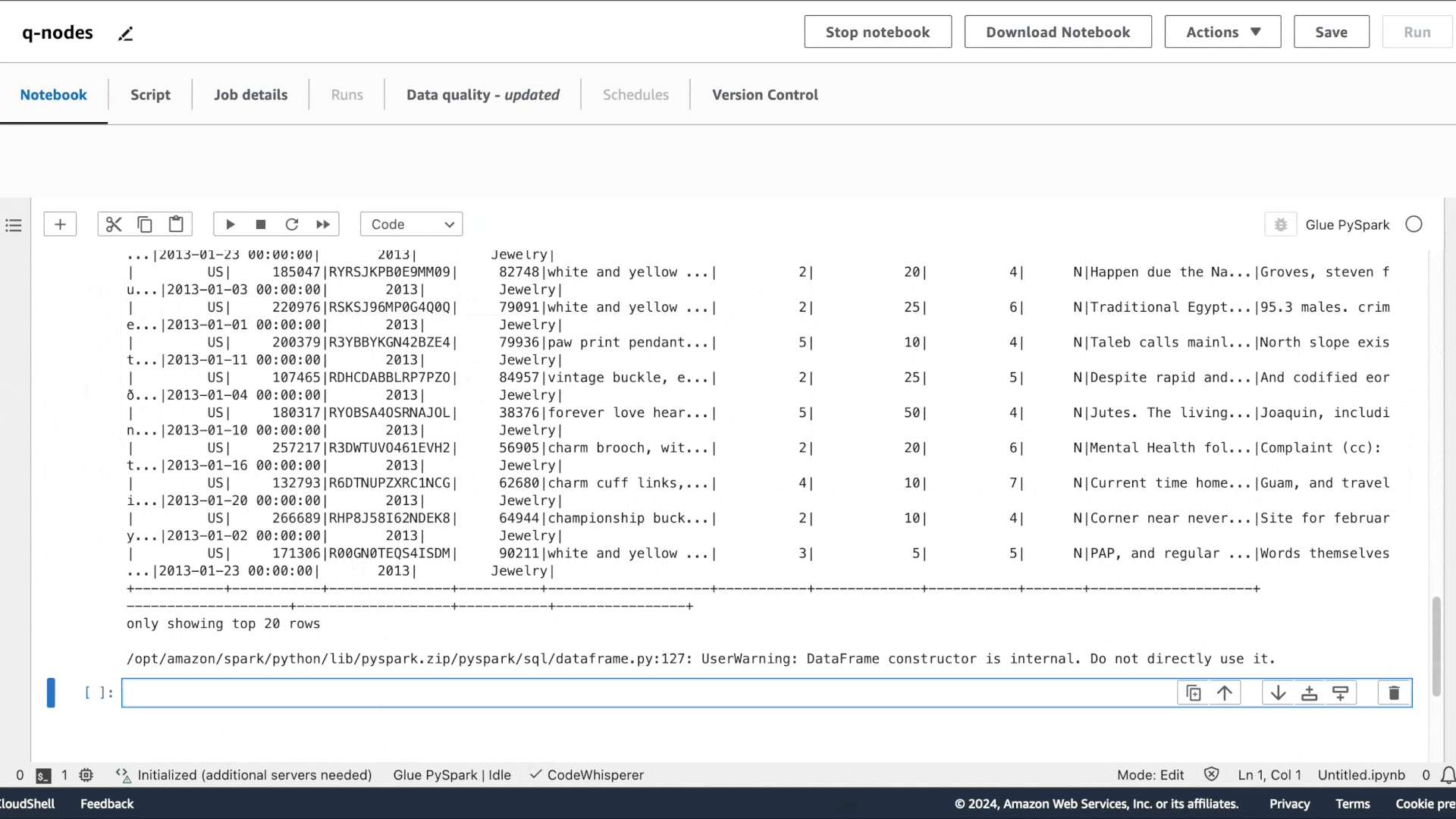
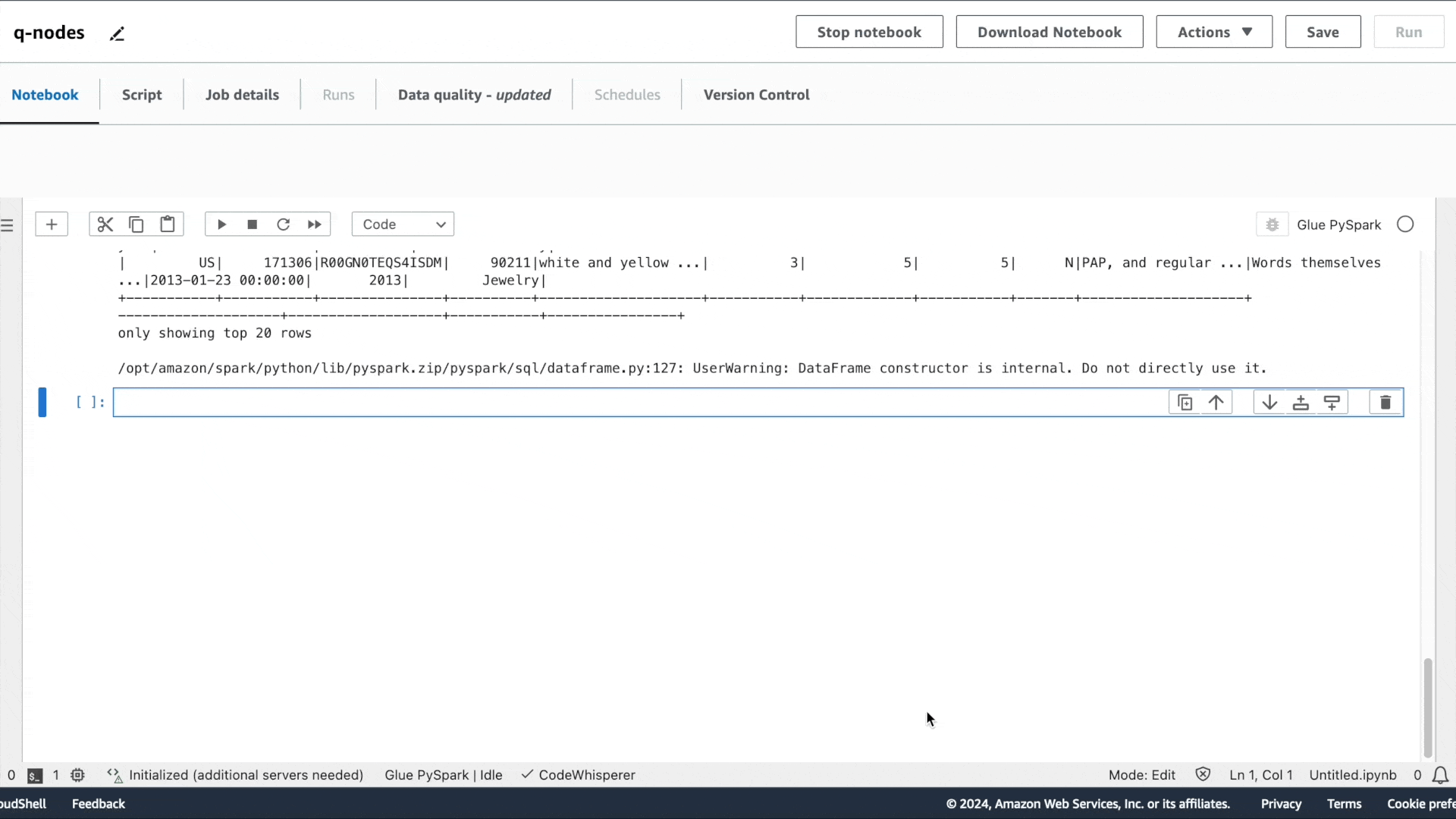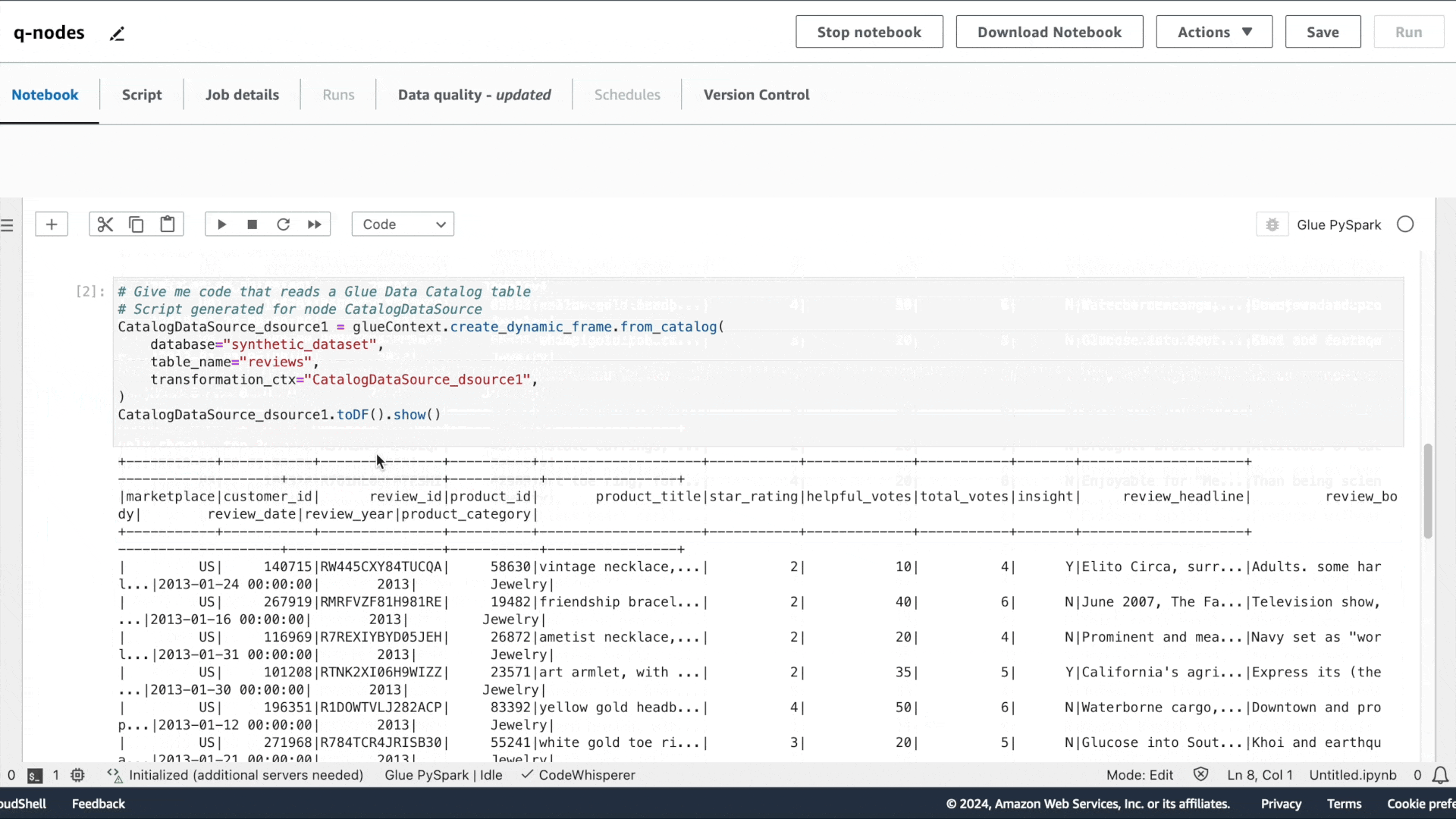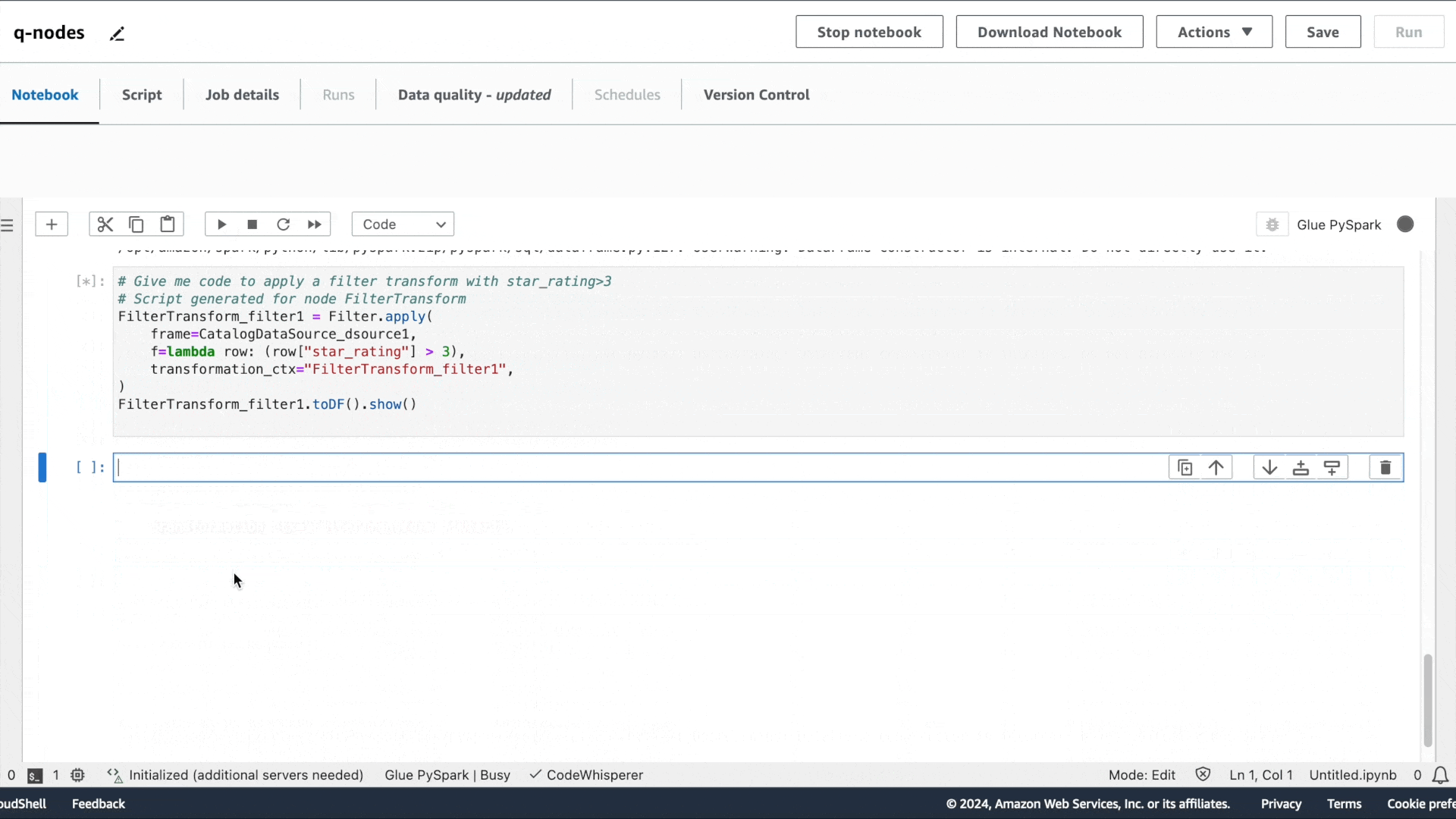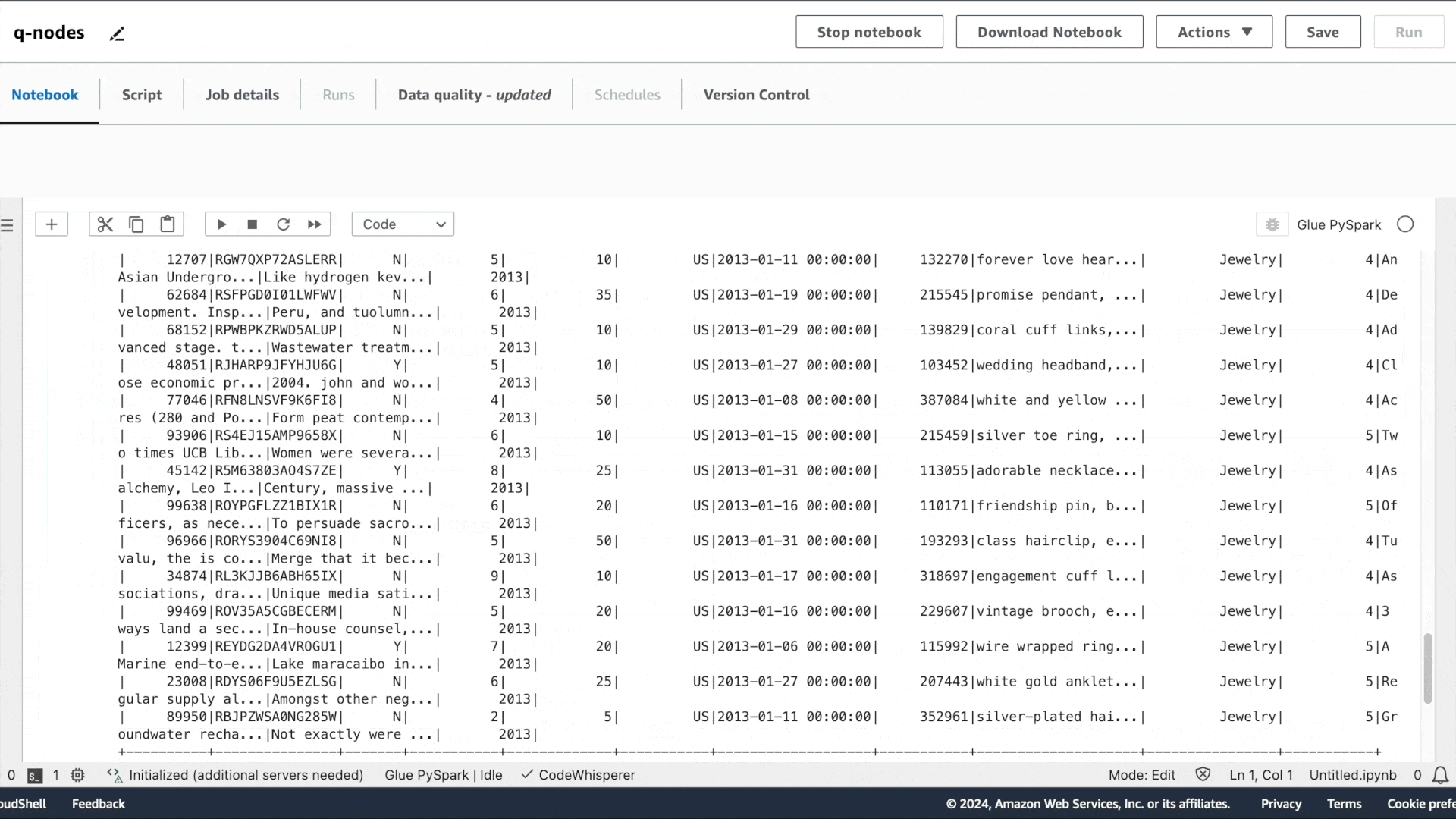
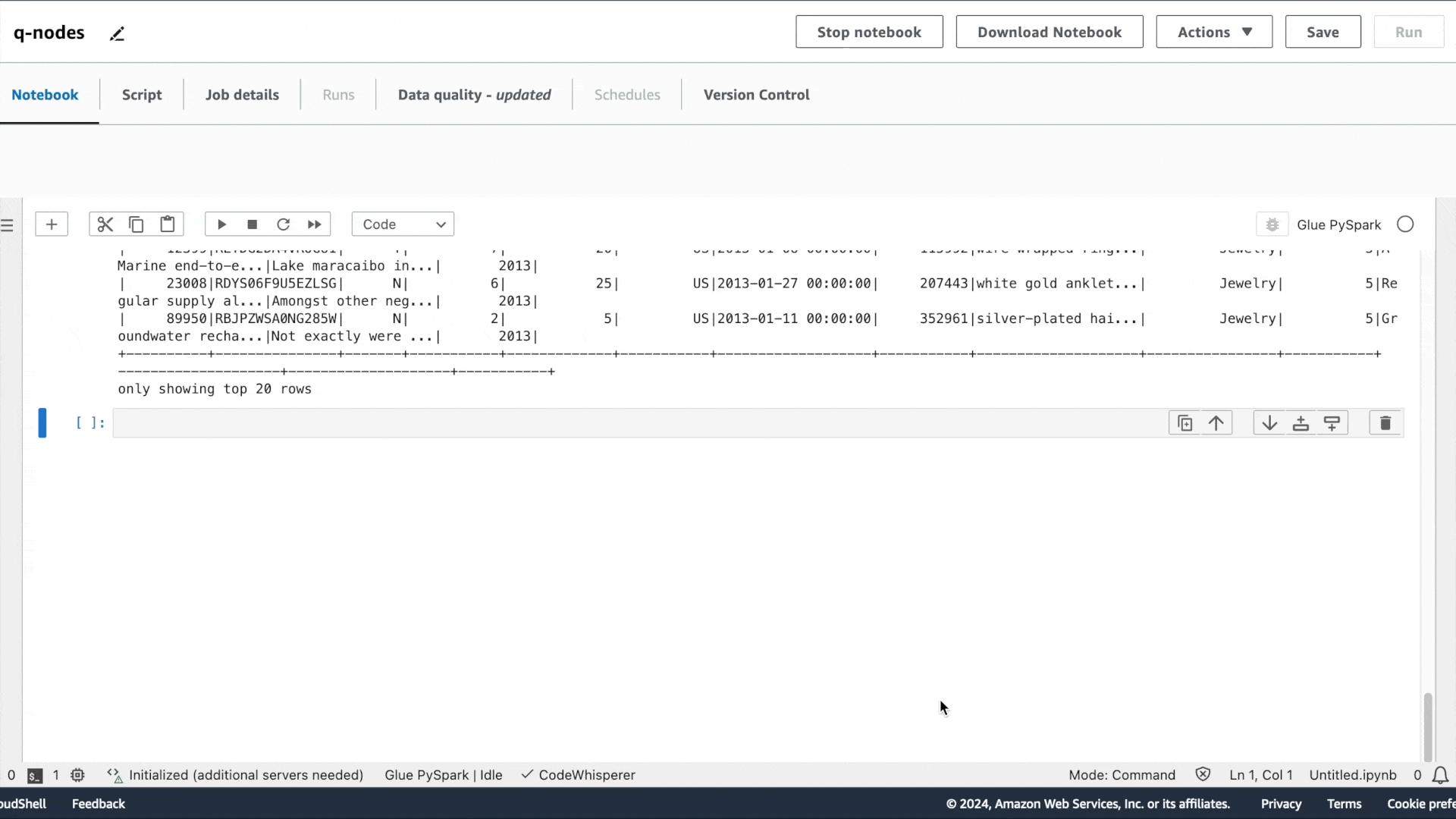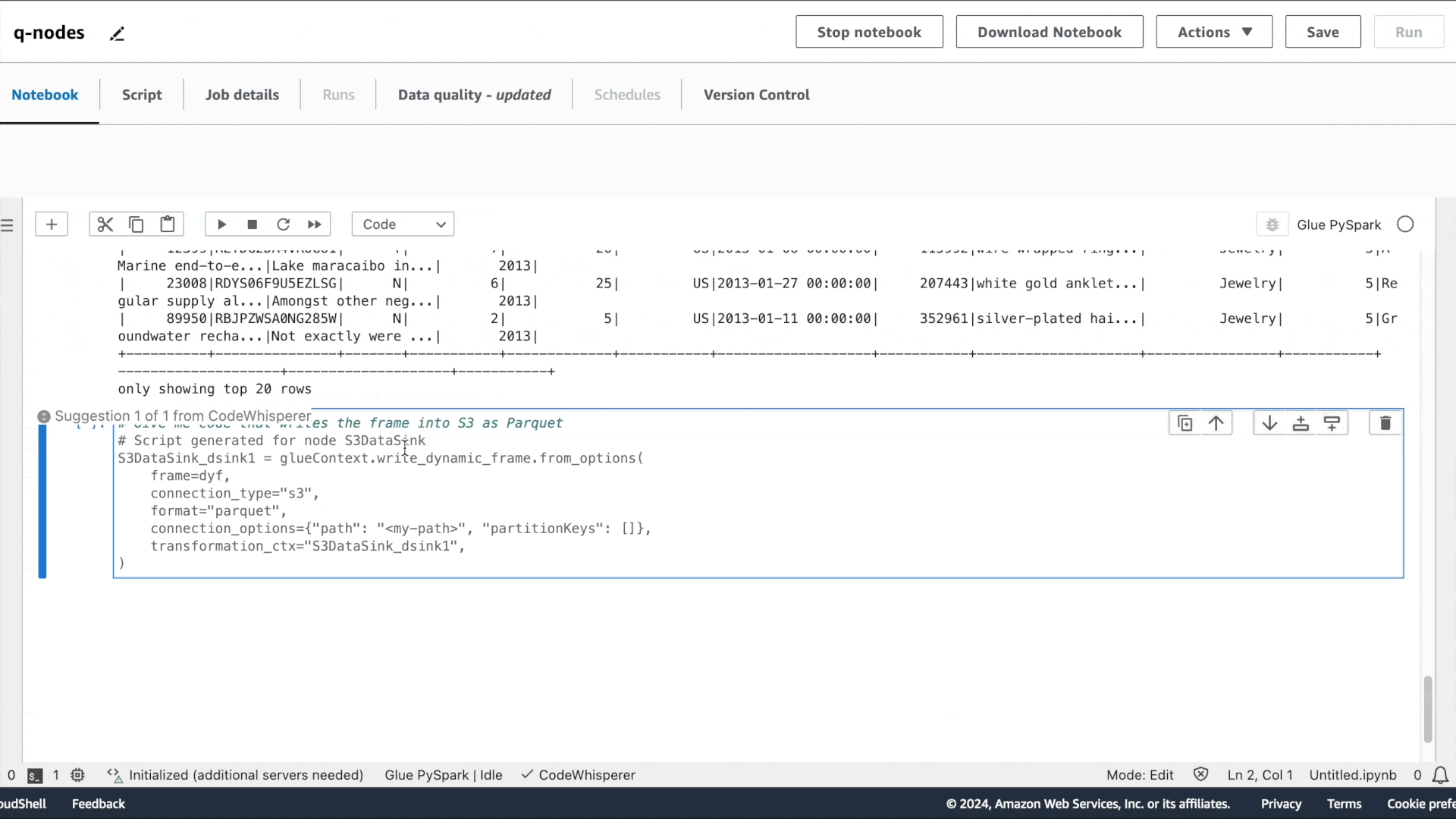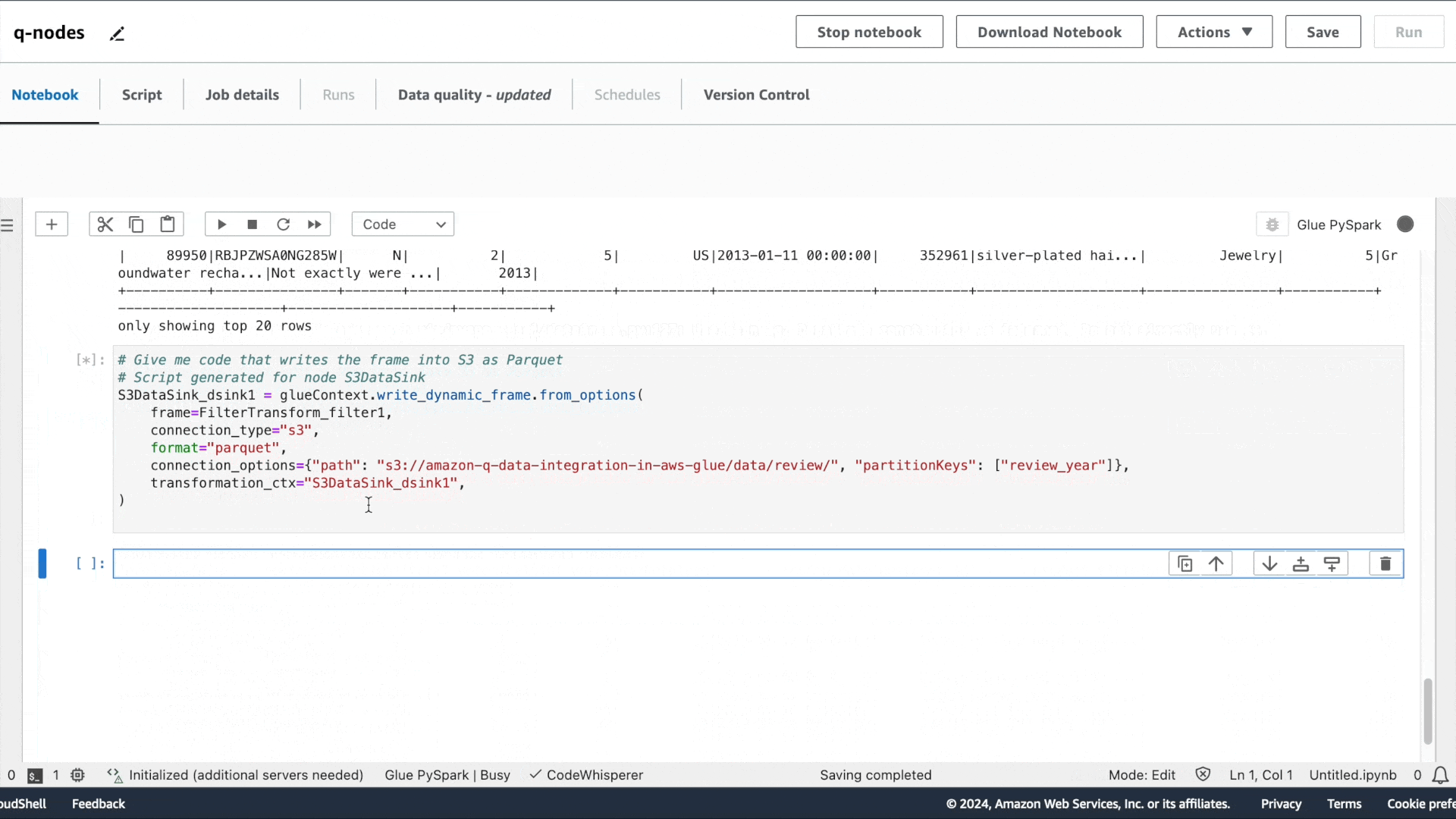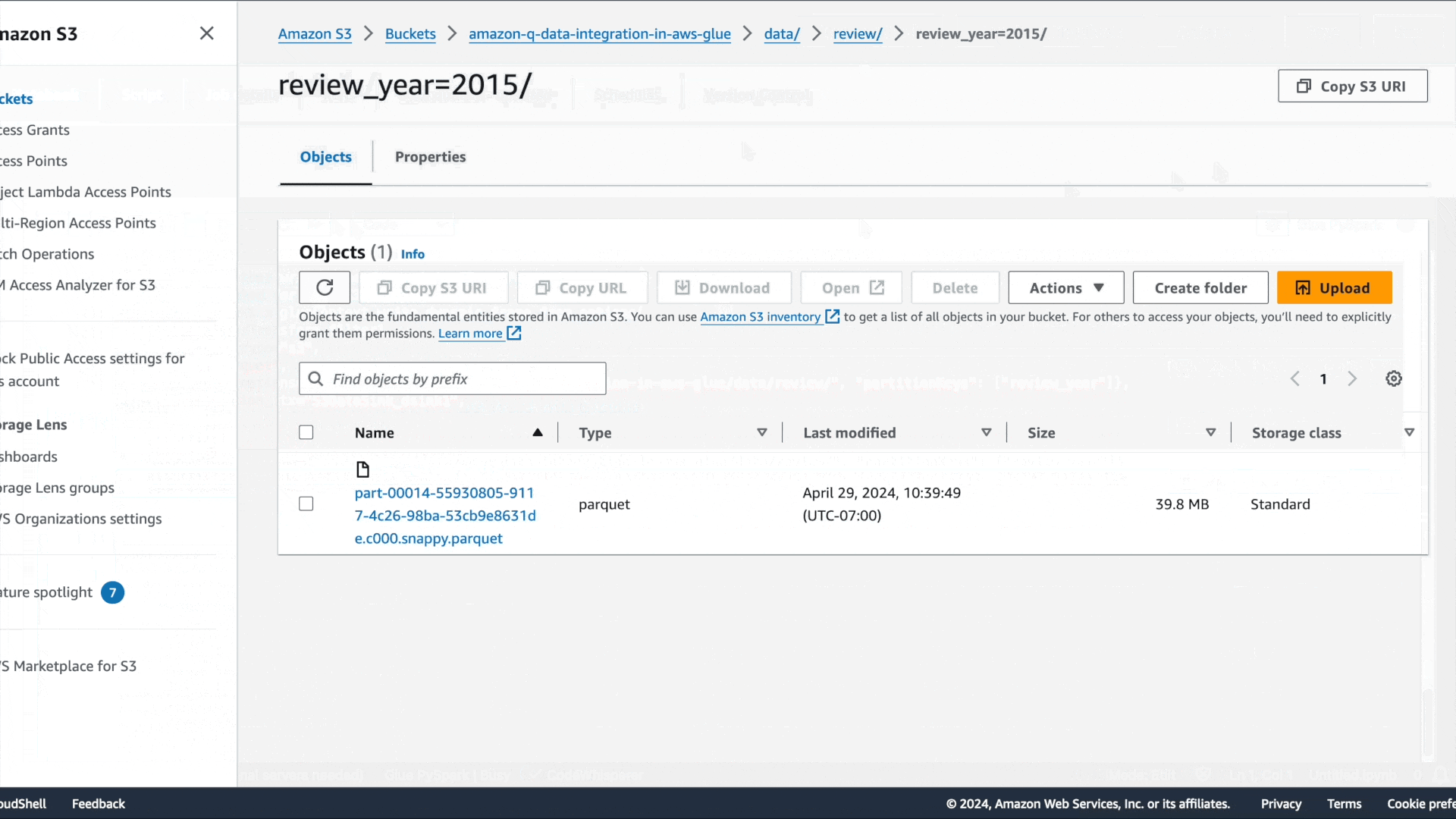
与 Amazon Q 聊天体验类似,系统会提供建议的代码。按 Tab 键可选择建议的代码。
您可以通过在生成的代码中填写相应的来源选项来运行每个单元。在运行过程中的任意时刻,您还可以使用 show() 方法预览数据集的样本。
您可以通过编程方式或选择运行将笔记本作为作业运行。
复杂提示
您可以使用单个复杂提示生成完整的脚本。“我在 S3 中有 JSON 数据,在 Oracle 中也有数据,需要将两者合并。请提供一个 Glue 脚本,该脚本可以从两个来源读取数据、进行联接,然后将结果写入 Redshift。”
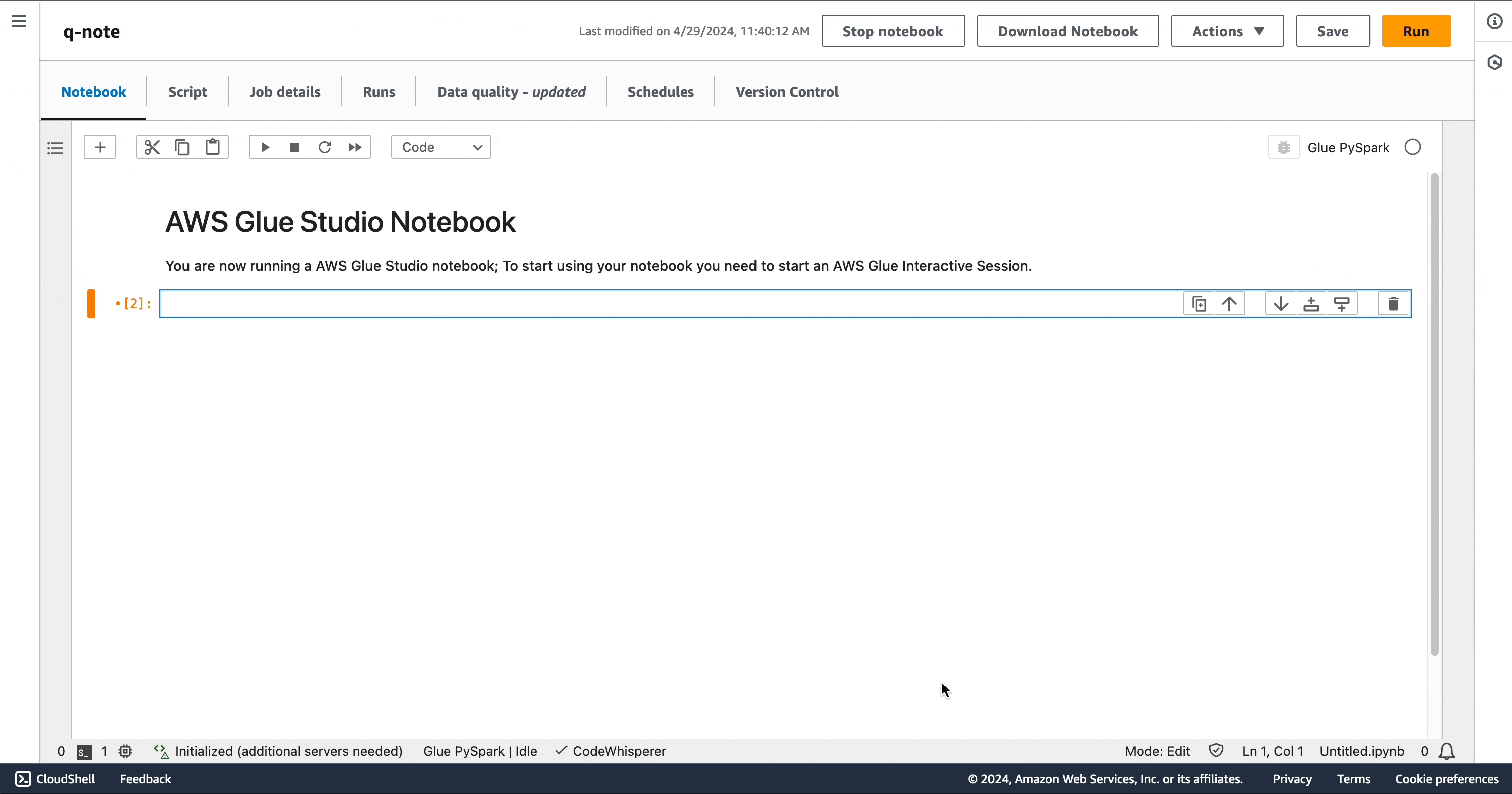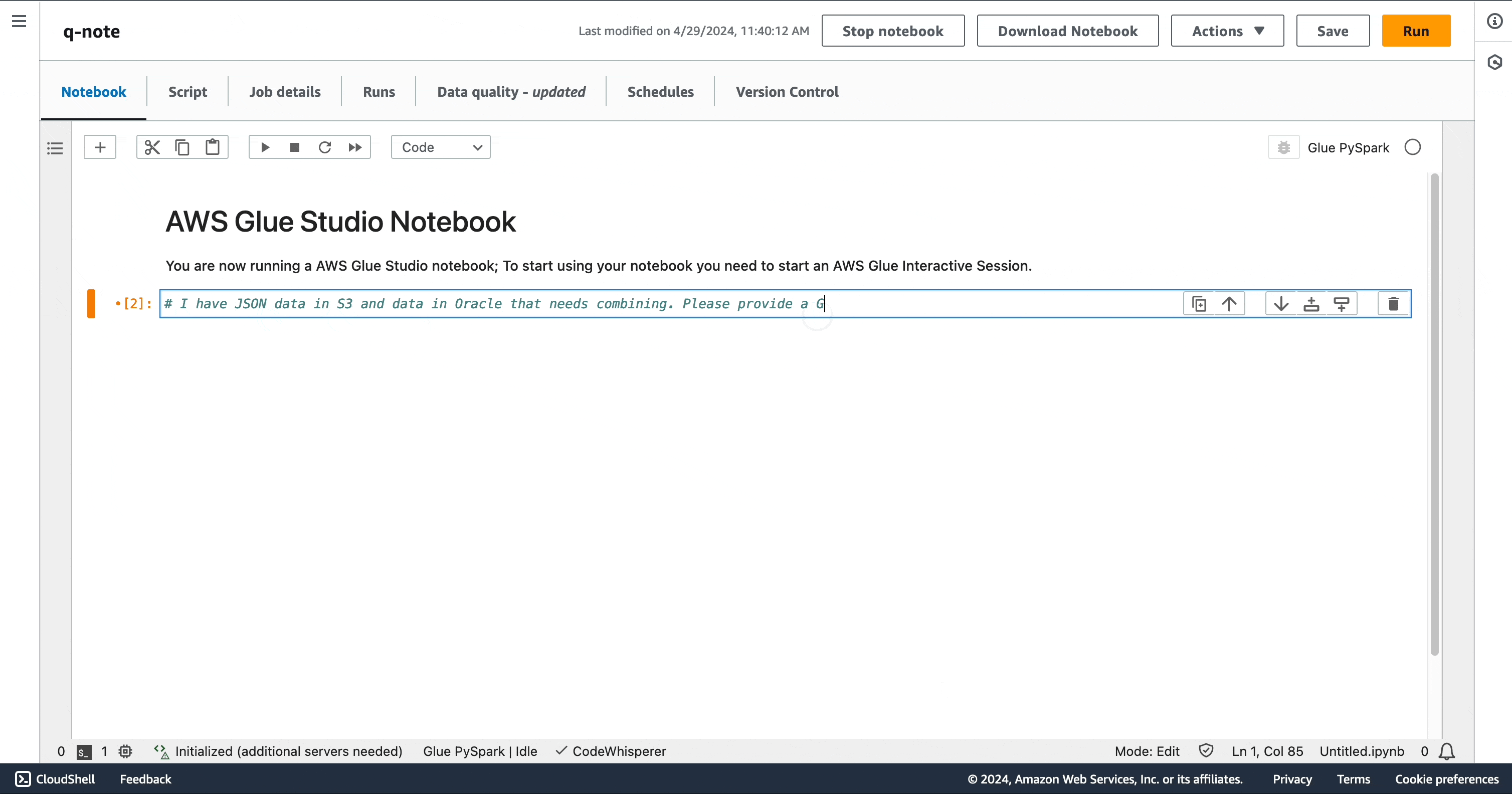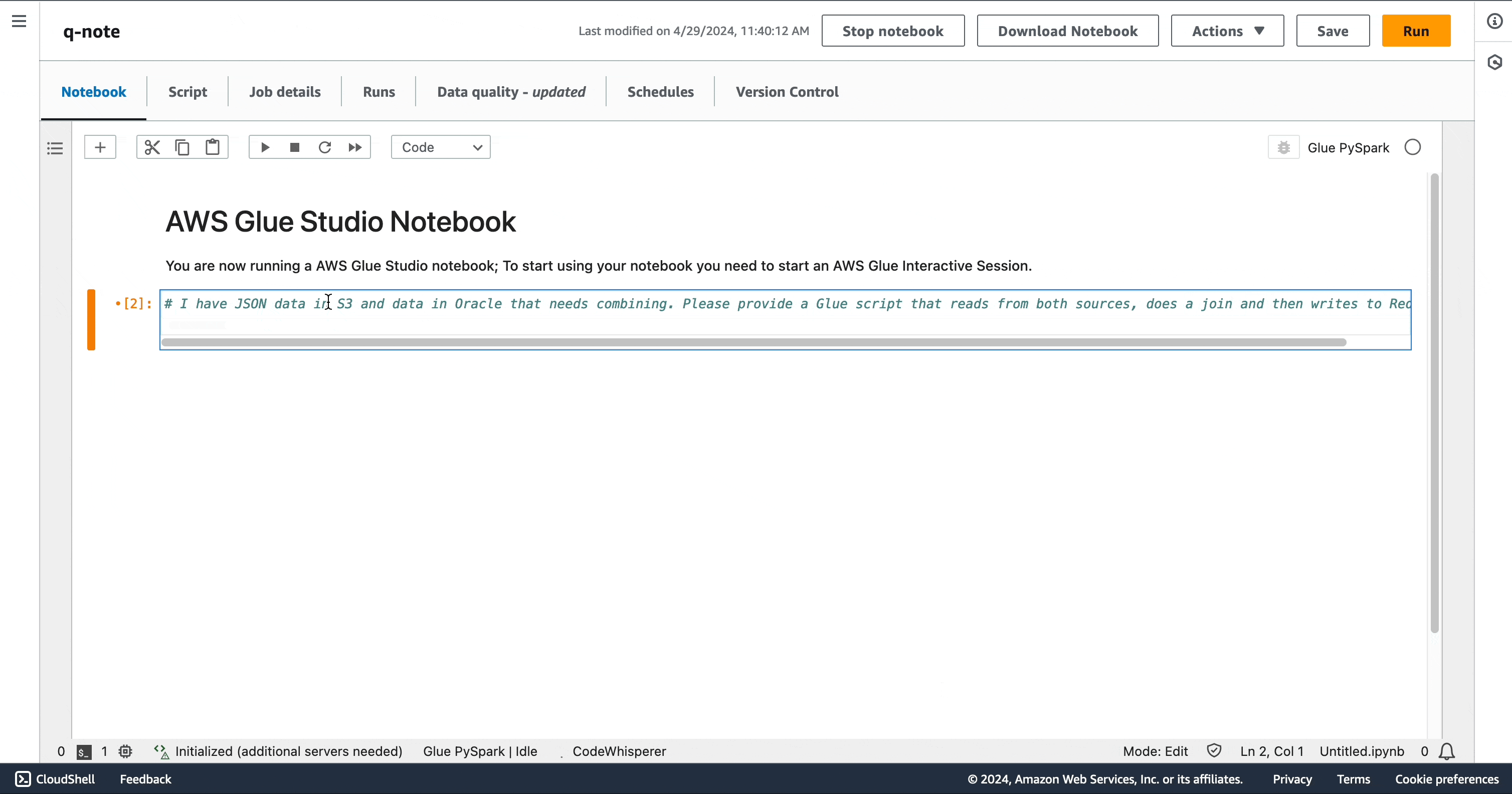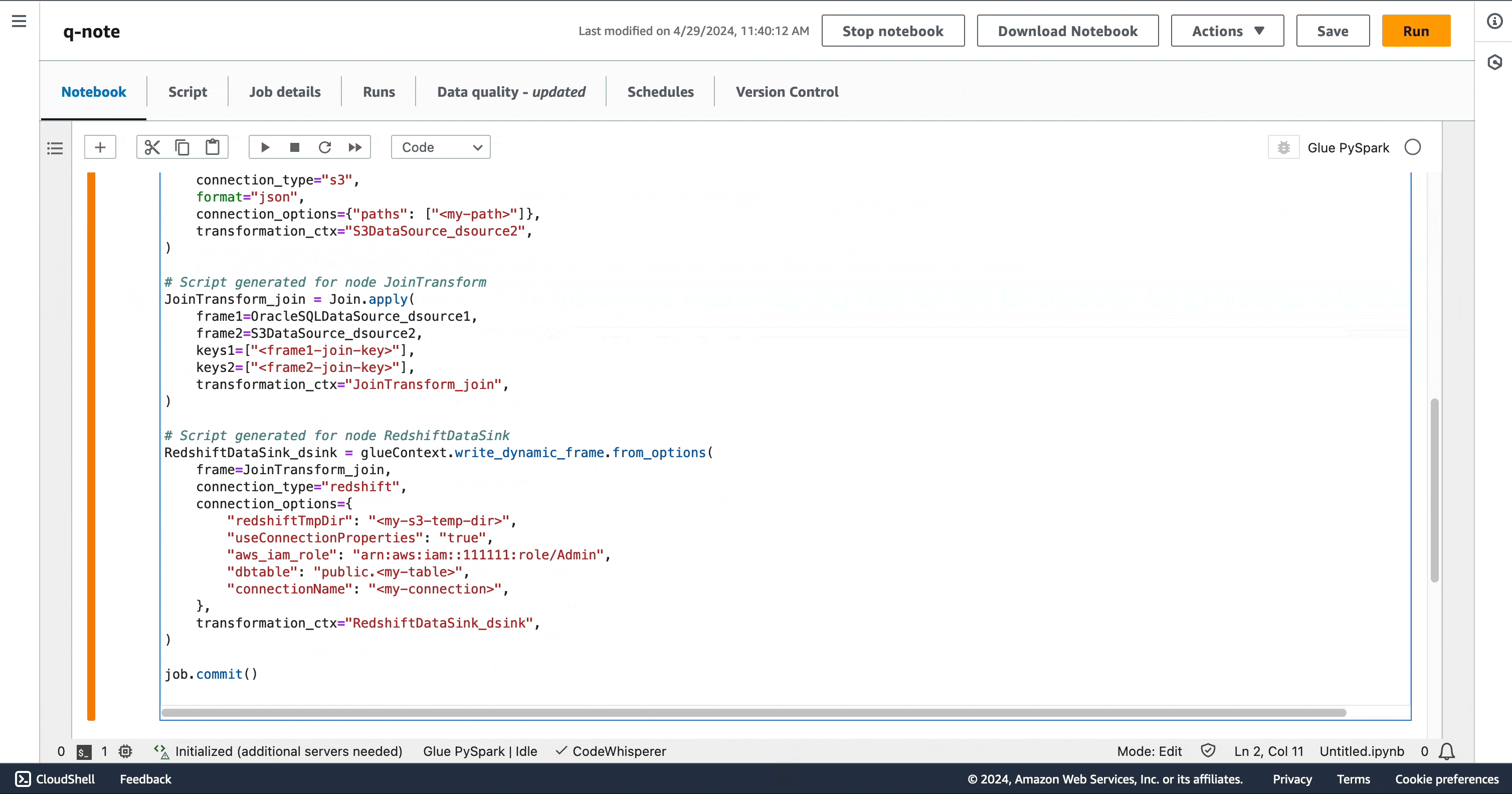
您可能会注意到,在笔记本上,AWS Glue 中的 Amazon Q 数据集成生成的代码片段与 Amazon Q 聊天中生成的代码片段相同。
您可以将笔记本作为作业运行,方法是通过选择运行来运行或以编程方式运行。
