AWS Glue 任务运行洞察是 AWS Glue 中的一个功能,可为 AWS Glue 任务简化任务调试和进行优化。AWS Glue 可提供 Spark UI 和 CloudWatch 日志和指标,以便监控您的 AWS Glue 任务。使用此功能,您可获得有关 AWS Glue 任务执行情况的信息:
失败的 AWS Glue 任务脚本的行号。
在您的作业失败之前,在 Spark 查询计划中最后执行的 Spark 操作。
在按时间排序的日志流中显示与故障相关的 Spark 异常事件。
根本原因分析和解决问题的建议措施(如优化脚本)。
常见的 Spark 事件(与 Spark 操作有关的日志消息),其中包含解决根本原因的推荐操作。
使用 AWS Glue 任务的 CloudWatch 日志中的两个新日志流,您可以获得所有这些洞察。
要求
AWS Glue 作业运行见解功能可用于 AWS Glue 版本 2.0、3.0、4.0 和 5.0。您可以按照现有任务的迁移指南从较早的 AWS Glue 版本进行升级。
为 AWS Glue ETL 作业启用任务运行洞察
您可以通过 AWS Glue Studio 或 CLI 启用任务运行洞察。
AWS Glue Studio
通过 AWS Glue Studio 创建任务时,您可以在 Job Details(任务详细信息)选项卡下启用或禁用任务运行洞察。确认生成作业洞察框是否处于选中状态。

命令行
如果通过 CLI 创建任务,则可以通过简单的新 job parameter(任务参数)启动任务运行:--enable-job-insights = true。
默认情况下,任务运行洞察日志流在 AWS Glue 连续录入使用的同一个默认日志组下进行创建,也就是 /aws-glue/jobs/logs-v2/。您可以使用相同的参数集来设置自定义日志组名称、日志筛选条件和日志组配置以进行连续日志录入。有关更多信息,请参阅启用 AWS Glue 任务的连续日志录入。
在 CloudWatch 中访问作业运行洞察日志流
启用任务运行洞察功能后,任务运行失败时可能会创建两个日志流。当任务成功完成后,两个流都不会生成。
异常分析日志流:
<job-run-id>-job-insights-rca-driver。该数据流提供以下功能:导致失败的 AWS Glue 任务脚本的行号。
Spark 查询计划 (DAG) 中最后执行的 Spark 操作。
来自与异常相关的 Spark 驱动程序和执行器的简明时序事件。您可以找到详细信息,例如完整的错误消息、失败的 Spark 任务及其执行者 ID,这些信息可帮助您专注于特定执行者的日志流,以便在需要时进行更深入的调查。
基于规则的洞察流式传输:
根本原因分析和如何修复错误的建议(例如使用特定的任务参数来优化性能)。
作为根本原因分析的基础和建议的行动的相关 Spark 事件。
注意
第一个流仅在任何异常触发事件可用于失败的任务运行时存在,第二个流仅在任何洞察可用于失败的任务运行时存在。例如,如果您的任务成功完成,则不会生成任何流;如果您的任务失败,但是没有服务定义的规则可以与您的失败场景匹配,那么将只生成第一个流。
如果通过 AWS Glue Studio 创建任务,则在“任务运行详细信息”选项卡(任务运行洞察)下,还可提供指向上述流式传输的链接,即“简明和综合错误日志”和“错误分析和指导”。
AWS Glue 任务运行洞察的示例
在本节中,我们将举例说明任务运行洞察功能如何帮助您解决失败任务中的问题。在本例中,用户忘记在用来分析和构建基于其数据的机器学习模型的 AWS Glue 任务中导入所需的模块 (tensorflow)。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.types import *
from pyspark.sql.functions import udf,col
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
data_set_1 = [1, 2, 3, 4]
data_set_2 = [5, 6, 7, 8]
scoresDf = spark.createDataFrame(data_set_1, IntegerType())
def data_multiplier_func(factor, data_vector):
import tensorflow as tf
with tf.compat.v1.Session() as sess:
x1 = tf.constant(factor)
x2 = tf.constant(data_vector)
result = tf.multiply(x1, x2)
return sess.run(result).tolist()
data_multiplier_udf = udf(lambda x:data_multiplier_func(x, data_set_2), ArrayType(IntegerType(),False))
factoredDf = scoresDf.withColumn("final_value", data_multiplier_udf(col("value")))
print(factoredDf.collect())
如果没有任务运行洞察功能,当任务失败时,您只会看到 Spark 抛出的以下消息:
An error occurred while calling o111.collectToPython. Traceback (most recent call last):
消息不明确,限制了您的调试体验。在这种情况下,此功能在两个 CloudWatch 日志流中为您提供了更多洞察:
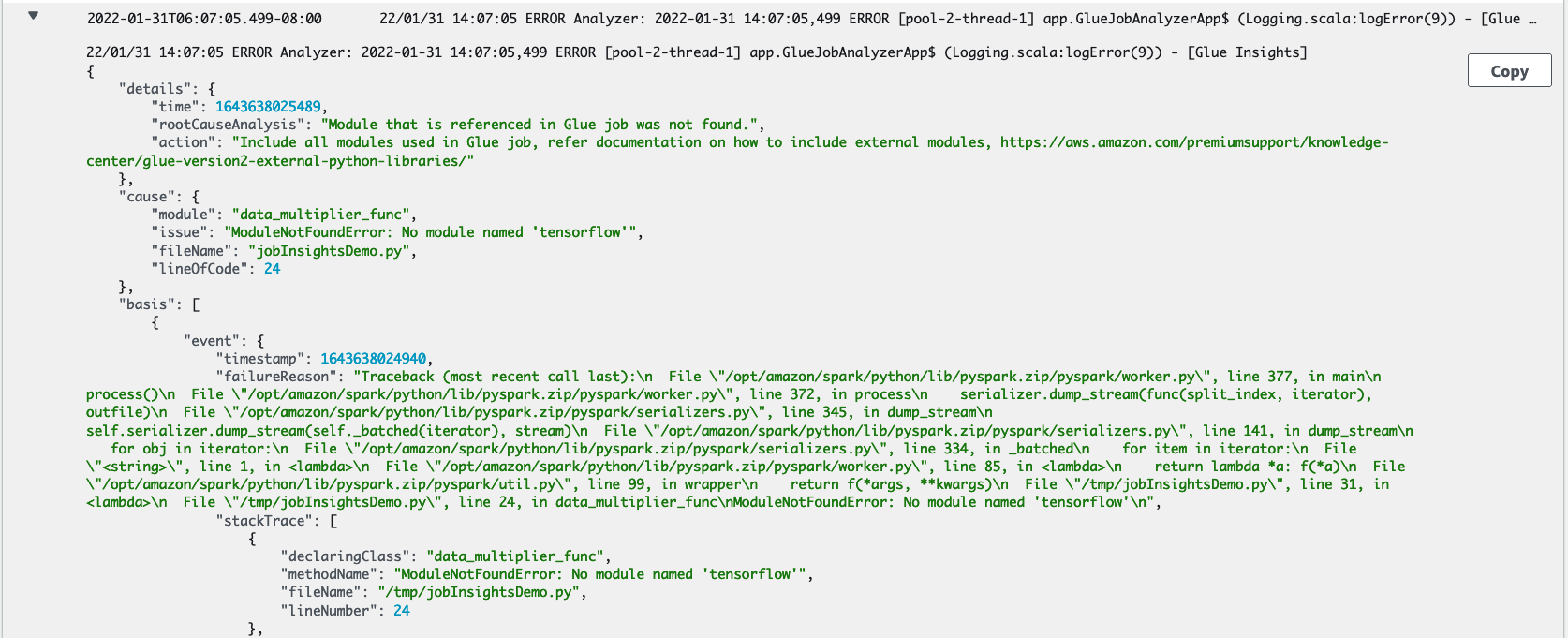
job-insights-rca-driver日志流:异常事件:此日志流为您提供与从 Spark 驱动程序和不同分布式工作人员收集的故障相关的 Spark 异常事件。这些事件有助于您理解异常在错误代码跨 Spark 任务、执行器和分布在 AWS Glue 工作器中的阶段执行时的时间顺序传播。
行号:这个日志流标识了第 21 行,我们对此进行调用,以导入导致失败的缺失 Python 模块;它还将第 24 行(对 Spark 操作
collect()的调用)标识为脚本中最后执行的一行。
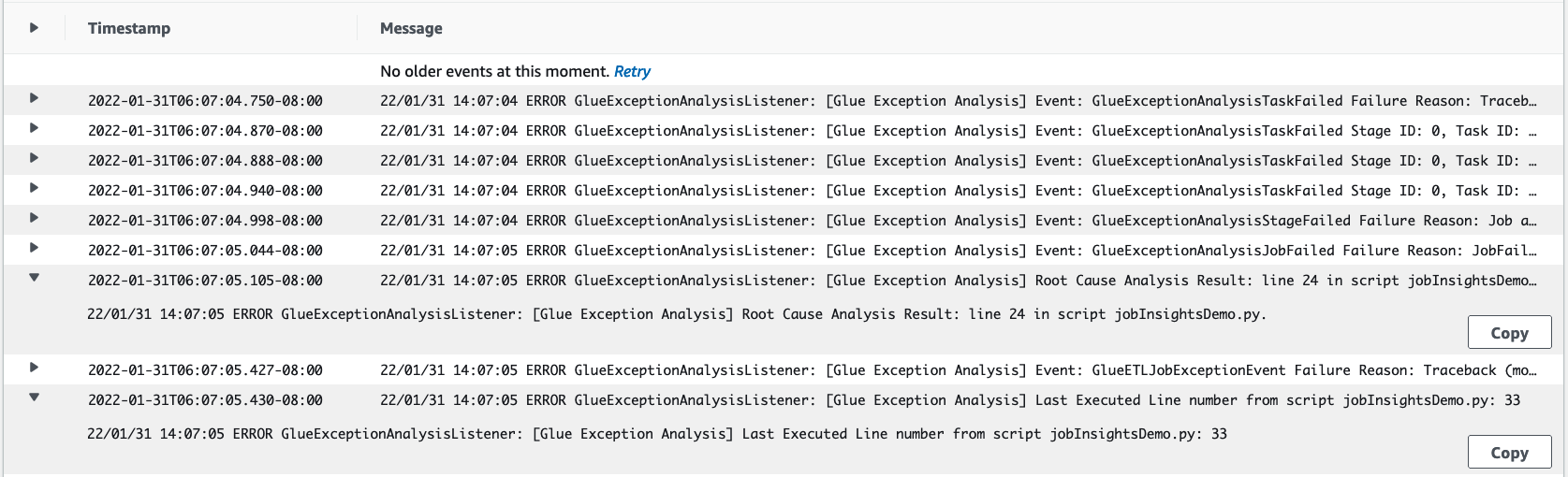
job-insights-rule-driver日志流:根本原因和建议:除了脚本中错误的行号和上次执行的行号之外,此日志流还显示了根本原因分析和建议,供您遵循 AWS Glue 文档并设置必要的任务参数,以便在 AWS Glue 任务中使用额外的 Python 模块。
基础事件:此日志流还显示了使用服务定义的规则评估的 Spark 异常事件,以推断根本原因并提供建议。