本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon Keyspaces:工作原理
Amazon Keyspaces 消除了 Cassandra 的管理开销。要了解原因,不妨先从 Cassandra 架构开始,然后将其与 Amazon Keyspaces 进行比较。
High-level 架构:Apache Cassandra 与亚马逊 Keyspaces
传统的 Apache Cassandra 部署在由一个或多个节点组成的集群中。您负责管理各个节点,并随着集群的扩展添加和删除节点。
客户端程序通过连接到其中一个节点并发出 Cassandra 查询语言 (CQL) 语句,来访问 Cassandra。CQL 类似于 SQL,后者是关系数据库中常用的语言。虽然 Cassandra 并不是关系数据库,不过 CQL 提供了一个熟悉的界面,可用于查询和操作 Cassandra 中的数据。
下图显示了一个由四个节点构成的简单 Apache Cassandra 集群。
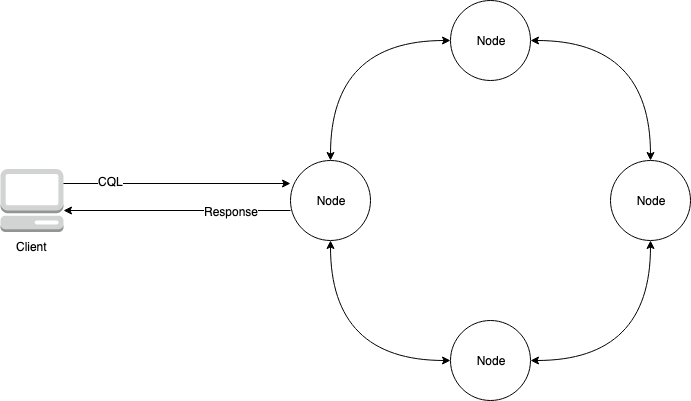
生产 Cassandra 部署可能由数百个节点构成,这些节点在一个或多个物理数据中心内的数百台物理计算机上运行。这会给应用程序开发人员带来运营负担,这些人员除了安装、维护和操作软件之外,还需要预置、修补和管理服务器。
使用 Amazon Keyspaces(Apache Cassandra 兼容),您无需预置、修补或管理服务器,因此可以专注于构建更好的应用程序。Amazon Keyspaces 提供两种读取和写入吞吐能力:按需和预置。您可以根据工作负载的可预测性和可变性选择表的吞吐容量模式,以优化读取和写入价格。
借助按需模式,您只需为您的应用程序实际执行的读取和写入付费。您无需事先指定表的吞吐能力。Amazon Keyspaces 几乎能在应用流量上升或下降时立即满足您的需求,因此对于流量不可预测的应用程序来说,它是一个不错的选择。
如果您的应用程序流量可预测,并且可以提前预测表的容量需求,那么预置容量模式可以帮助您优化吞吐量的价格。使用预置容量模式时,请指定您的应用程序预计每秒需要执行的读取和写入次数。您可以通过启用自动扩展来自动增加和减少表的预置容量。
在以下情况下,您可以每天更改一次表的容量模式:您需要了解有关工作负载的流量模式的更多信息,或如果您预计流量会突增(例如,您预计会发生导致大量表流量的重大事件)。有关预置读取和写入容量的更多信息,请参阅在 Amazon Keyspaces 中配置 read/write 容量模式。
Amazon Keyspaces(Apache Cassandra 兼容)将数据的三个副本存储在多个可用区
下图显示了 Amazon Keyspaces 的架构。
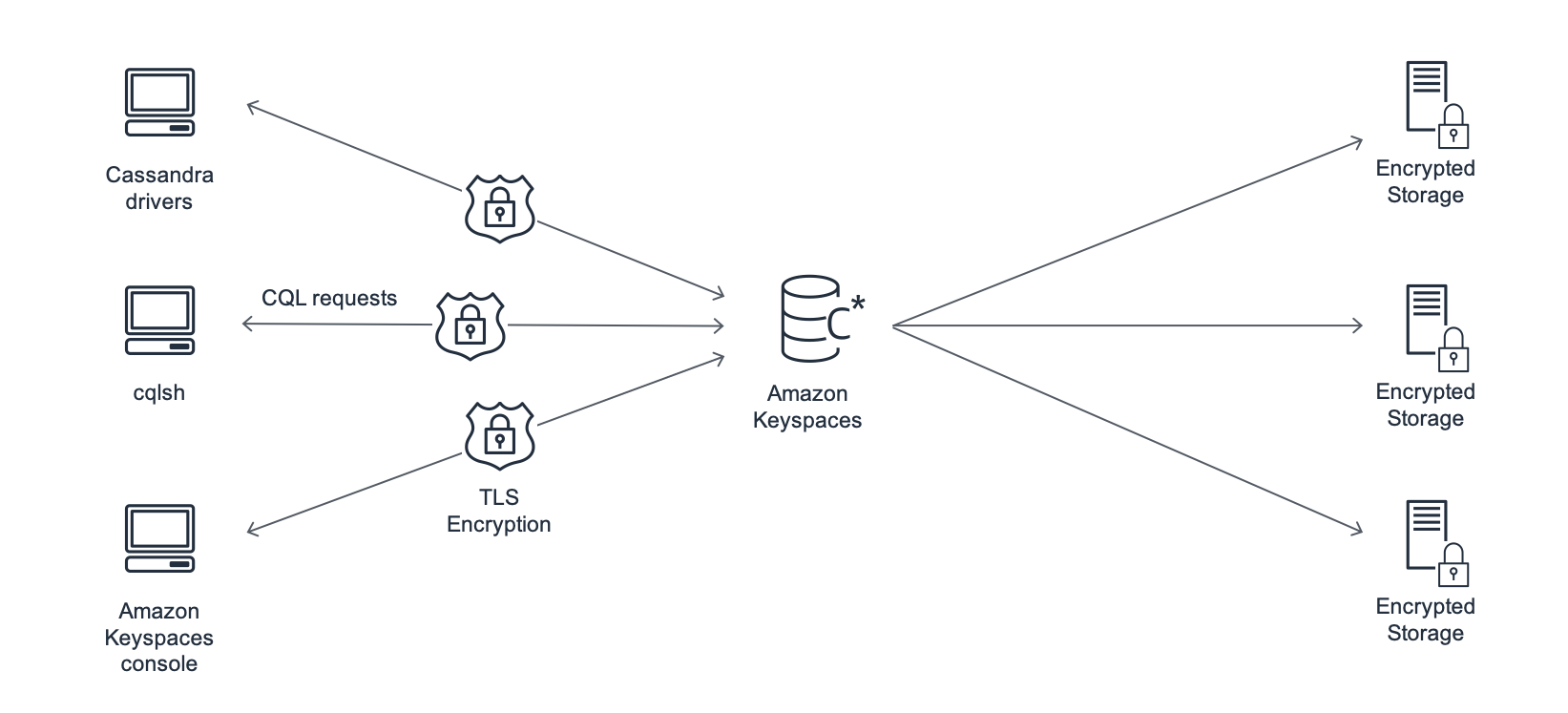
客户端程序通过连接到预先确定的端点(主机名和端口号)并发出 CQL 语句来访问 Amazon Keyspaces。有关可用端点的列表,请参阅Amazon Keyspaces 的服务端点。
Cassandra 数据模型
业务案例数据的建模方式对于从 Amazon Keyspaces 实现最佳性能至关重要。较差的数据模型会显著地降低性能。
尽管 CQL 与 SQL 类似,但 Cassandra 后端与关系数据库后端存在明显的不同,必须采取不同的方法。下面是需要考虑的一些更重要的问题:
- 存储
-
可以在表中直观地显示您的 Cassandra 数据,其中每行表示一条记录,每列表示该记录中的一个字段。
- 表设计:查询优先
-
CQL 中没有
JOIN。因此,您应该根据数据的性质,以及需要如何访问数据来满足业务使用案例的要求,设计您的表。这可能会导致重复数据的逆规范化。您应该专门为特定的访问模式设计每个表。 - 分区
-
您的数据存储在磁盘分区中。存储数据的分区数以及数据在分区之间的分布方式由您的分区键 决定。分区键的定义方式会对查询的性能产生重大影响。有关最佳实践,请参阅如何在 Amazon Keyspaces 中高效使用分区键。
- 主键
-
在 Cassandra 中,数据以键/值对的形式存储。每个 Cassandra 表必须有一个主键,这对于表中的每一行是唯一键。主键是一个必需的分区键与多个可选的聚类列的组合。组成主键的数据在表中的所有记录之间必须是唯一的。
-
分区键 - 主键的分区键部分是必需的,可确定数据存储在集群的哪个分区中。分区键可以是单个列,也可以是由两列或多个列组成的复合值。如果单列分区键会导致单个分区或极少数分区拥有大部分数据,从而承受大部分磁盘 I/O 操作,则可以使用复合分区键。
-
聚类列 - 主键的可选聚类列部分决定如何在每个分区中聚类和排序数据。如果在主键中包含聚类列,则聚类列可以包含一列或多列。如果聚类列中有多列,则排序顺序由聚类列中列出的顺序从左到右确定。
-
有关 NoSQL 设计和 Amazon Keyspaces 的更多信息,请参阅 NoSQL 设计的主要区别和设计原则。有关 Amazon Keyspaces 和数据建模的更多信息,请参阅数据建模最佳实践:设计数据模型的建议。
通过应用程序访问 Amazon Keyspaces
Amazon Keyspaces(Apache Cassandra 兼容)实施 Apache Cassandra 查询语言 (CQL) API,因此您可以使用您已在使用的 CQL 和 Cassandra 驱动程序。要更新您的应用程序,只需更新您的 Cassandra 驱动程序或 cqlsh 配置以指向 Amazon Keyspaces 服务端点即可。有关所需凭证的更多信息,请参阅为 Amazon Keyspaces 创建和配置 AWS 证书。
注意
为了帮助您入门,您可以在上的 Amazon Keyspaces 代码示例存储库中找到使用各种 Cassandra 客户端驱动程序连接到亚马逊密钥空间的端到端代码示例。GitHub
考虑以下 Python 程序,该程序连接到 Cassandra 集群并查询表。
from cassandra.cluster import Cluster #TLS/SSL configuration goes here ksp = 'MyKeyspace' tbl = 'WeatherData' cluster = Cluster(['NNN.NNN.NNN.NNN'], port=NNNN) session = cluster.connect(ksp) session.execute('USE ' + ksp) rows = session.execute('SELECT * FROM ' + tbl) for row in rows: print(row)
要对 Amazon Keyspaces 运行同一个程序,您需要:
-
添加集群终端节点和端口:例如,可以将主机替换为服务终端节点,例如端口号为
9142的cassandra.us-east-1.amazonaws.com。 -
添加 TLS/SSL 配置:有关使用 Cassandra 客户端 Python 驱动程序添加 TLS/SSL 配置以连接到 Amazon Keyspaces 的更多信息,请参阅。使用 Cassandra Python 客户端驱动程序以编程方式访问 Amazon Keyspaces
