本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
启动到 Amazon Lex V2 机器人的对话流
您可以使用该StartConversation操作在应用程序中启动用户和 Amazon Lex V2 机器人之间的直播。来自应用程序的 POST 请求会在您的应用程序和 Amazon Lex V2 机器人之间建立连接。这样,您的应用程序和机器人就能够开始通过事件相互交换信息。
仅在以下情况下支持该操作 SDKs:StartConversation
您的应用程序必须向 Amazon Lex V2 机器人发送的第一个事件是。ConfigurationEvent该事件包含诸如响应类型格式之类的信息。可以在配置事件中使用的参数如下所示:
-
responseContentType— 确定机器人是用文字还是语音回应用户输入。
-
sessionState:与机器人流式会话相关的信息,例如预先确定的意图或对话状态。
-
welcomeMessages:指定在用户与机器人对话开始时为其播放的欢迎消息。这些消息在用户提供输入之前播放。要激活欢迎消息,还须指定
sessionState和dialogAction参数的值。 -
disablePlayback:确定机器人是否应等待客户端的提示后才开始监听来电者的输入。默认情况下,播放处于激活状态,因此该字段的值为
false。 -
requestAttributes:为请求提供其他信息。
有关如何为上述参数指定值的信息,请参阅StartConversation操作ConfigurationEvent的数据类型。
机器人与您的应用程序之间的每个流只能有一个配置事件。在您的应用程序发送配置事件后,机器人可以从您的应用程序获取其他通信。
如果您已指定您的用户通过音频与 Amazon Lex V2 机器人通信,则您的应用程序可以在对话期间向该机器人发送以下事件:
-
AudioInputEvent— 包含最大大小为 320 字节的音频块。您的应用程序必须通过多个音频输入事件从服务器向机器人发送消息。该流中的每个音频输入事件都必须具有相同的音频格式。
-
DTMFInput事件 — 向机器人发送 DTMF 输入。每次 DTMF 按键都对应一个事件。
-
PlaybackCompletionEvent— 通知服务器已向他们播放了来自用户输入的响应。如果您要向用户发送音频响应,则必须使用播放完成事件。如果配置事件的
disablePlayback取值为true,则无法使用此功能。 -
DisconnectionEvent— 通知机器人用户已断开与对话的连接。
如果您已指定用户通过文本与机器人通信,则您的应用程序可以在对话期间向机器人发送以下事件:
-
TextInputEvent— 从您的应用程序发送给机器人的文本。每个文本输入事件中最多可包含 512 个字符。
-
PlaybackCompletionEvent— 通知服务器已向他们播放了来自用户输入的响应。如果您要向用户播放音频,则必须使用此事件。如果配置事件的
disablePlayback取值为true,则无法使用此功能。 -
DisconnectionEvent— 通知机器人用户已断开与对话的连接。
您必须以正确的格式对发送给 Amazon Lex V2 机器人的每个事件进行编码。有关更多信息,请参阅 事件流编码。
每个事件都有一个事件 ID。为了帮助解决流中可能出现的任何问题,请为每个输入事件分配一个唯一的事件 ID。然后,您可以通过机器人解决任何处理失败问题。
Amazon Lex V2 还为每个事件使用时间戳。除了事件 ID 之外,您还可以使用这些时间戳来帮助解决任何网络传输问题。
在用户与 Amazon Lex V2 机器人对话期间,机器人可以向用户发送以下出站事件作为响应:
-
IntentResultEvent— 包含 Amazon Lex V2 根据用户话语确定的意图。每个内部结果事件均包括:
-
inputMode:用户言语的类型。有效值为
Speech、DTMF或Text。 -
interpretations:Amazon Lex V2 根据用户言语确定的解释。
-
requestAttributes:如果您尚未使用 lambda 函数修改请求属性,则这些属性与对话开始时传递的属性相同。
-
sessionId:用于对话的会话标识符。
-
sessionState:用户与 Amazon Lex V2 的会话状态。
-
-
TranscriptEvent— 如果用户向您的应用程序提供输入,则此事件包含用户对机器人说话的脚本。如果没有用户输入,您的应用程序不会收到
TranscriptEvent。发送到应用程序的转录事件的值取决于您是将音频(语音和 DMTF)还是文本指定为对话模式:
-
语音输入转录:如果用户正在与机器人通话,则该转录事件是用户音频的转录。这是从用户开始说话到他们结束讲话的所有语音的转录。
-
DTMF 输入转录:如果用户通过键盘键入,则该转录事件包含用户在输入中按下的所有数字。
-
文本输入转录:如果用户提供文本输入,则该转录事件包含用户输入中的所有文本。
-
-
TextResponseEvent— 包含文本格式的机器人响应。默认情况下,会返回文本响应。如果您已将 Amazon Lex V2 配置为返回音频响应,则该文本用于生成音频响应。每个文本响应事件都包含机器人返回给用户的消息对象数组。
-
AudioResponseEvent— 包含根据中生成的文本合成的音频响应。
TextResponseEvent要接收音频响应事件,您必须将 Amazon Lex V2 配置为提供音频响应。所有音频响应事件都具有相同的音频格式。每个事件包含最多 100 字节的音频块。Amazon Lex V2 向您的应用程序发送一个空的音频块,其中bytes字段设置为null,表示音频响应事件已结束。 -
PlaybackInterruptionEvent— 当用户中断机器人发送到您的应用程序的响应时,Amazon Lex V2 会触发此事件以停止响应的播放。
-
HeartbeatEvent— Amazon Lex V2 会定期回发此事件,以防止您的应用程序与机器人之间的连接超时。
使用 Amazon Lex V2 机器人时音频对话事件的时序
下列图中展示了用户与 Amazon Lex V2 机器人之间的流式音频对话。应用程序会持续将音频流式传输到机器人,机器人会从该音频中寻找用户输入。在该示例中,用户和机器人都通过语音进行通信。每个图都对应一个用户言语和机器人对该言语的响应。
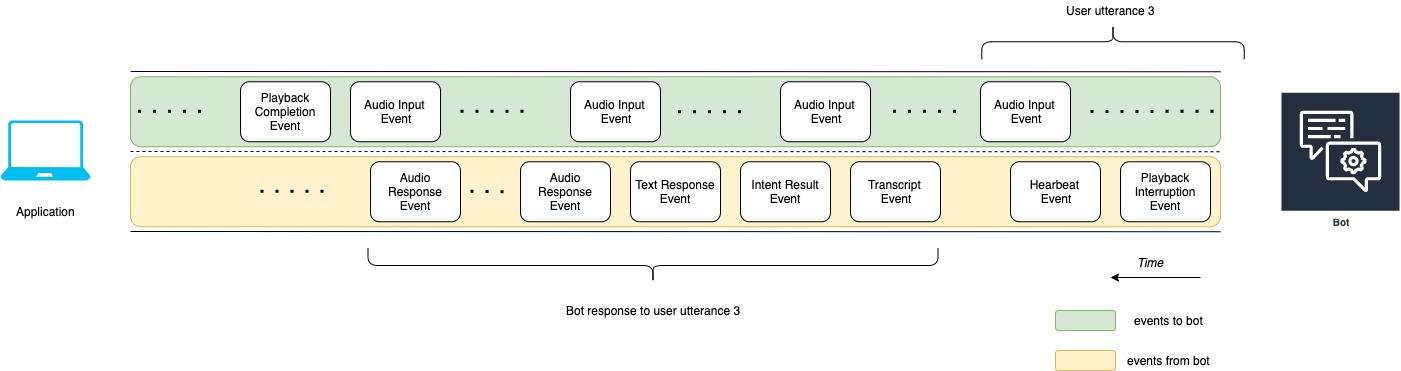
应用程序和机器人之间对话的开始如下图所示。该流传输从零时 (t0) 开始。
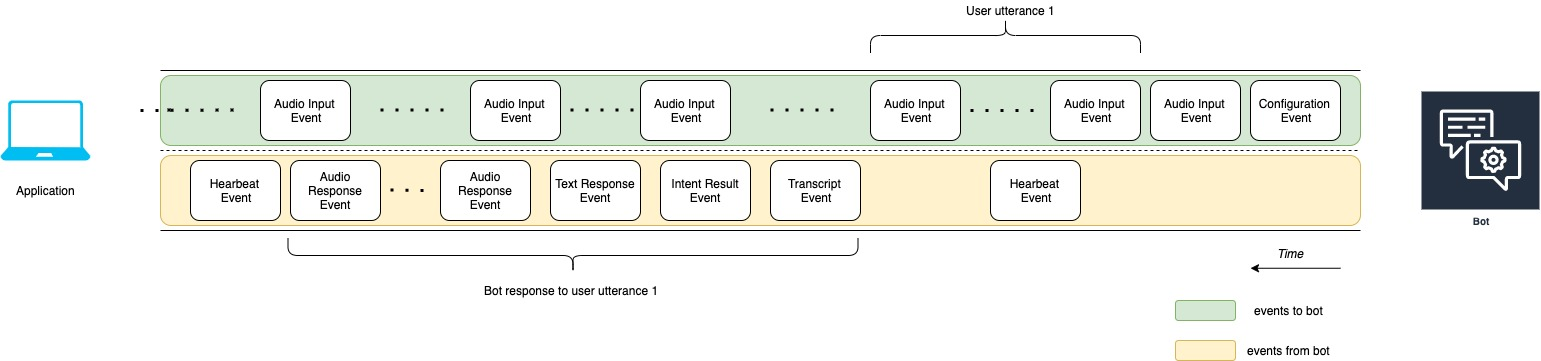
上图中的各事件如下所述:
-
t0:应用程序向机器人发送配置事件以启动流传输。
-
t1:应用程序流传输音频数据。该数据被分解为来自应用程序的一系列输入事件。
-
t2:对于用户言语 1,当用户开始说话时,机器人会检测到一个音频输入事件。
-
t2:当用户说话时,机器人会发送心跳事件以保持连接。它间歇性发送这些事件,以确保连接不会超时。
-
t3:机器人检测到用户言语已结束。
-
t4:机器人向应用程序发回一个包含用户语音转录的转录事件。这表示机器人对用户言语 1 的响应的开始。
-
t5:机器人发送意图结果事件,以指示用户想要执行的操作。
-
t6:机器人开始在文本响应事件中以文本形式提供响应。
-
t7:机器人向应用程序发送一系列音频响应事件,以便为用户播放。
-
t8:机器人发送另一个心跳事件以间歇性地保持连接。
下图是对上图的延续。它显示应用程序向机器人发送播放完成事件,表明它已停止为用户播放音频响应。应用程序向用户播放机器人对用户言语 1 的响应。用户通过用户言语 2 来回应机器人对用户言语 1 的响应。
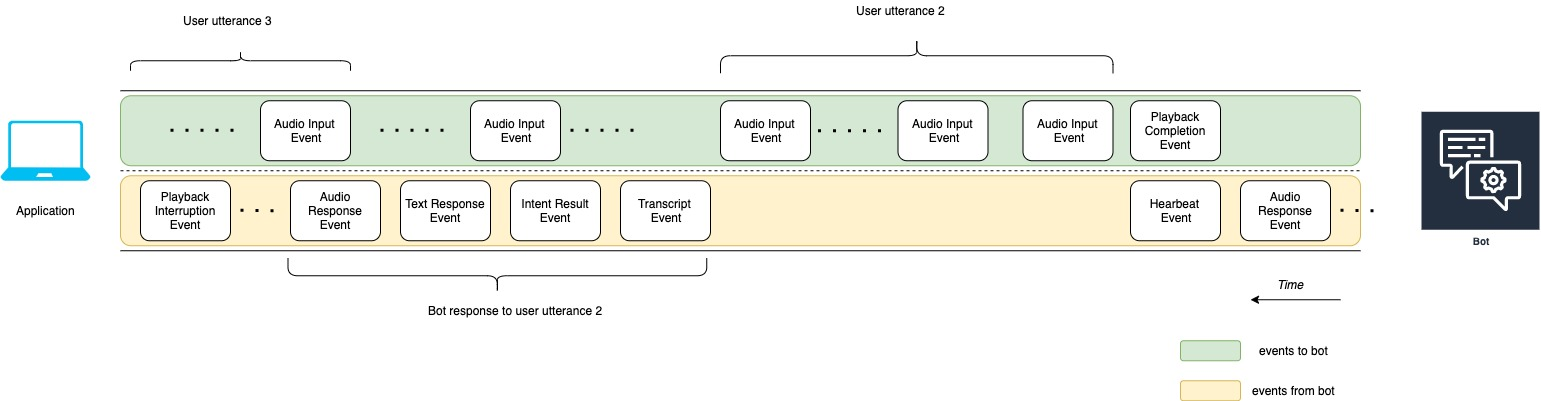
上图中的各事件如下所述:
-
t10:应用程序发送播放完成事件,表示它已完成向用户播放机器人消息。
-
t11:应用程序将用户响应作为用户言语 2 发送回机器人。
-
t12:关于机器人对用户言语 2 的响应,机器人会等待用户停止说话,然后开始提供音频响应。
-
t13:当机器人向应用程序发送机器人对用户言语 2 的响应时,会检测到用户言语 3 的开始。机器人会停止机器人对用户言语 2 的响应,并发送播放中断事件。
-
t14:机器人向应用程序发送播放中断事件,表示用户已中断提示。
下图显示了机器人对用户言语 3 的响应,以及机器人响应用户言语后对话仍在继续。