我们不再更新 Amazon Machine Learning 服务,也不再接受新用户使用该服务。本文档可供现有用户使用,但我们不会再对其进行更新。有关更多信息,请参阅什么是 Amazon Machine Learning。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Cross-Validation
Cross-validation 是一种评估机器学习模型的技术,方法是根据可用输入数据的子集训练多个机器学习模型,然后根据数据的互补子集对其进行评估。使用交叉验证来检测过度拟合,即无法泛化模式。
在 Amazon ML 中,您可以使用 K 折交叉验证方法执行交叉验证。在 K 折交叉验证中,您将输入数据拆分为 k 个数据子集(也称为折叠)。 您在除某个子集 (k-1) 之外的所有子集上训练 ML 模型,然后在训练时未使用的子集上评估该模型。此过程将重复执行 k 次,每次使用一个预留用于评估的不同子集(训练中不包含的子集)。
下图显示了在 4 折交叉验证过程中创建和训练的四个模型中为每个模型生成的训练子集和补充评估的示例。模型一使用第一个 25% 的数据进行评估,使用其余 75% 的数据进行训练。模型二使用第二个 25%(25% 到 50%)的子集进行评估,使用其余三个数据子集进行训练,依此类推。
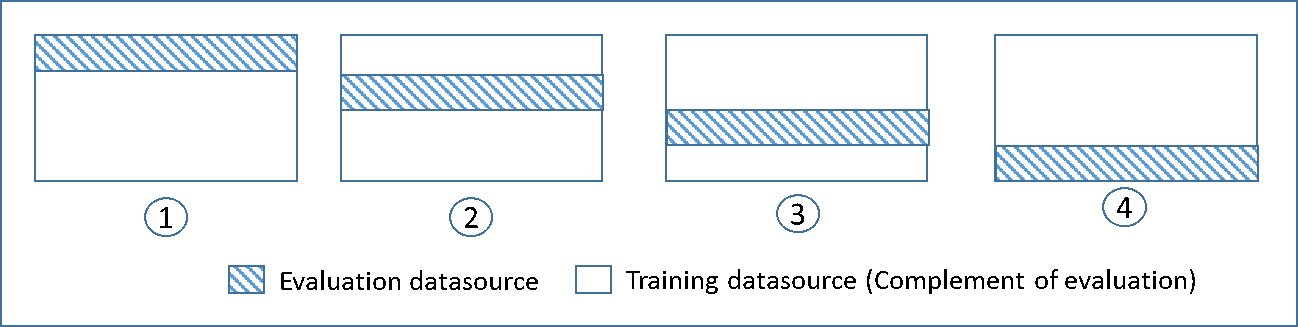
每个模型使用补充数据源进行训练和评估,包含评估数据源中的数据,并且仅限于训练数据源中不包含的所有数据。您可以使用 DataRearrangement、createDatasourceFromS3 和 createDatasourceFromRedShift API 中的 createDatasourceFromRDS 参数为这些子集中的每个子集创建数据源。在 DataRearrangement 参数中,通过指定每个分段的开始和结束位置来指定数据源将包含的数据的子集。要创建补充 4K 折交叉验证所需的补充数据源,请按照以下示例所示指定 DataRearrangement 参数:
模型一:
用于评估的数据源:
{"splitting":{"percentBegin":0, "percentEnd":25}}
用于训练的数据源:
{"splitting":{"percentBegin":0, "percentEnd":25, "complement":"true"}}
模型二:
用于评估的数据源:
{"splitting":{"percentBegin":25, "percentEnd":50}}
用于训练的数据源:
{"splitting":{"percentBegin":25, "percentEnd":50, "complement":"true"}}
模型三:
用于评估的数据源:
{"splitting":{"percentBegin":50, "percentEnd":75}}
用于训练的数据源:
{"splitting":{"percentBegin":50, "percentEnd":75, "complement":"true"}}
模型四:
用于评估的数据源:
{"splitting":{"percentBegin":75, "percentEnd":100}}
用于训练的数据源:
{"splitting":{"percentBegin":75, "percentEnd":100, "complement":"true"}}
执行 4 折交叉验证会生成四个模型、四个训练模型的数据源、四个评估模型的数据源和四个评估,每个模型一个。Amazon ML 为每个评估生成模型性能指标。例如,在适用于二进制分类问题的 4 折交叉验证中,每个评估都会报告曲线下面积 (AUC) 指标。您可以通过计算四个 AUC 指标的平均值获得整体性能测量值。有关 AUC 指标的信息,请参阅衡量 ML 模型准确度。
有关显示如何创建交叉验证和计算模型分数平均值的示例代码,请参阅 Amazon ML 示例代码
调整您的模型
对模型执行交叉验证后,如果模型的表现未达到您的标准,您可以调整下一个模型的设置。有关过度拟合的更多信息,请参阅模型拟合:欠拟合与过度拟合。有关正则化的更多信息,请参阅正则化。有关更改正则化设置的更多信息,请参阅使用自定义选项创建 ML 模型。
