本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在 Amazon OpenSearch Ingestion 中设置角色和用户
Amazon OpenSearch Ingestion 使用各种权限模型和 IAM 角色,来允许源应用程序写入管道以及允许管道写入接收器。在开始社区数据之前,必须根据自己的用例创建一个或多个具有具体权限的 IAM 角色。
至少需要以下角色才能成功设置管道。
下图演示了典型的管道设置,其中诸如 Amazon S3 或 Fluent Bit 之类的数据来源使用不同的账户写入管道。在这种情况下,客户端需要担任提取角色才能访问管道。有关更多信息,请参阅 跨账户提取。
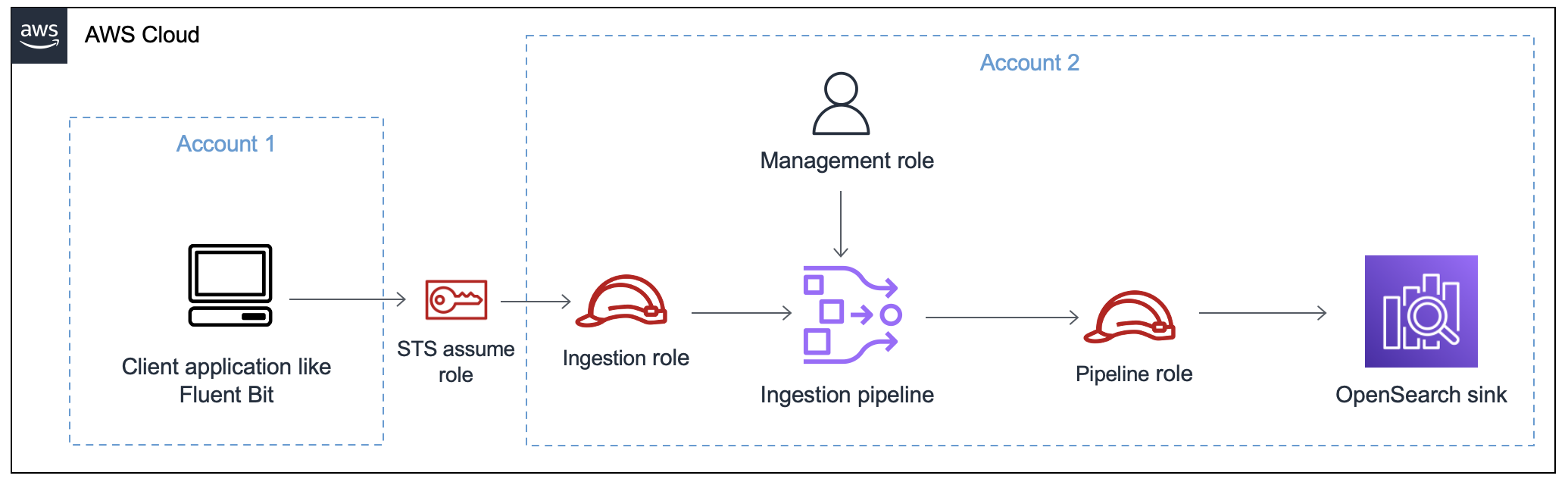
欲了解简易设置指南,请参阅教程:使用 Amazon OpenSearch Ingestion 将数据提取到域。
管理角色
除了创建和修改管道所需的基本 osis:* 权限外,您还需要管道角色资源的 iam:PassRole 权限。任何 AWS 服务 接受角色的人都必须使用此权限。OpenSearch Ingestion 每次需要将数据写入接收器时都会担任该角色。这有助于管理员确保仅批准的用户可配置具有能够授予权限的角色的 OpenSearch Ingestion。有关更多信息,请参阅向用户授予将角色传递给 AWS 服务 的权限。
如果您使用的是(AWS Management Console使用蓝图并稍后检查您的管道),则需要以下权限才能创建和更新管道:
{ "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Resource":"*", "Action":[ "osis:CreatePipeline", "osis:GetPipelineBlueprint", "osis:ListPipelineBlueprints", "osis:GetPipeline", "osis:ListPipelines", "osis:GetPipelineChangeProgress", "osis:ValidatePipeline", "osis:UpdatePipeline" ] }, { "Resource":[ "arn:aws:iam::your-account-id:role/pipeline-role" ], "Effect":"Allow", "Action":[ "iam:PassRole" ] } ] }
如果您使用的是(AWS CLI不预先验证您的管道或使用蓝图),则需要以下权限才能创建和更新管道:
{ "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Resource":"*", "Action":[ "osis:CreatePipeline", "osis:UpdatePipeline" ] }, { "Resource":[ "arn:aws:iam::your-account-id:role/pipeline-role" ], "Effect":"Allow", "Action":[ "iam:PassRole" ] } ] }
管道角色
管道需要一定的权限才能向其接收器写入。这些权限取决于接收器是 OpenSearch 服务域还是 OpenSearch 无服务器集合。
此外,管道可能需要权限才能从源应用程序(如果源应用程序是基于拉取的插件)拉取,以及写入 S3 死信队列(如果已配置)。
写入域接收器
OpenSearch Ingestion 管道需要权限才能写入配置为其接收器的 OpenSearch Service 域。这些权限包括能够描述域以及向其发送 HTTP 请求。
要向管道提供写入接收器所需的权限,请先创建具有所需权限的 AWS Identity and Access Management(IAM)角色。公有和 VPC 管道需要相同的权限。然后,在域访问策略中指定管道角色,以便该域可以接受来自管道的写入请求。
最后,将角色 ARN 指定为管道配置中 sts_role_arn 选项的值:
version: "2" source: http: ... processor: ... sink: - opensearch: ... aws: sts_role_arn: arn:aws:iam::your-account-id:role/pipeline-role
有关完成其中每个步骤的说明,请参阅允许管道访问域。
写入集合接收器
OpenSearch Ingestion 管道需要权限才能写入配置为其接收器的 OpenSearch 无服务器集合。这些权限包括能够描述集合以及向其发送 HTTP 请求。
首先,创建 IAM 角色,该角色具有访问所有资源的 aoss:BatchGetCollection权限 (*)。然后,将此角色包含在数据访问策略中,并为其提供在集合中创建索引、更新索引、描述索引和写入文档的权限。最后,将角色 ARN 指定为管道配置中 sts_role_arn 选项的值。
有关完成其中每个步骤的说明,请参阅允许管道访问集合。
写入死信队列
如果将管道配置为写入死信队列sts_role_arn 选项。此角色中包含的权限允许管道访问您指定为 DLQ 事件目的地的 S3 存储桶。
您必须在所有管道组件中使用相同的 sts_role_arn。因此,您必须为提供 DLQ 访问权限的管道角色附加单独的权限策略。至少必须允许该角色对存储桶资源执行 S3:PutObject 操作:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "WriteToS3DLQ", "Effect": "Allow", "Action": "s3:PutObject", "Resource": "arn:aws:s3:::my-dlq-bucket/*" } ] }
然后,您可以在管道的 DLQ 配置中指定角色:
... sink: opensearch: dlq: s3: bucket: "my-dlq-bucket" key_path_prefix: "dlq-files" region: "us-west-2" sts_role_arn: "arn:aws:iam::your-account-id:role/pipeline-role"
提取角色
OpenSearch Ingestion 目前支持的所有源插件(S3 除外)都使用基于推送的架构。这意味着源应用程序将数据推送到管道,而不是管道从源中拉取数据。
因此,您必须向源应用程序授予将数据摄取到 OpenSearch Ingestion 管道所需的权限。至少,必须向签署请求的角色授予 osis:Ingest 操作的权限,从而允许其向管道发送数据。公有和 VPC 管道端点需要相同的权限。
以下示例策略允许关联主体将数据摄取到名为 my-pipeline 的单个管道:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "PermitsWriteAccessToPipeline", "Effect": "Allow", "Action": "osis:Ingest", "Resource": "arn:aws:osis:region:your-account-id:pipeline/pipeline-name" } ] }
有关更多信息,请参阅 将 Amazon OpenSearch Ingestion 管道与其他服务和应用程序集成。
跨账户提取
您可能需要从其他(AWS 账户例如应用程序账户)将数据摄取到管道中。要配置跨账户提取,请在与管道相同的账户中定义一个提取角色,并在提取角色和应用程序账户之间建立信任关系:
{ "Version": "2012-10-17", "Statement": [{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::external-account-id:root" }, "Action": "sts:AssumeRole" }] }
然后,将您的应用程序配置为担任提取角色。应用程序账户必须向应用程序角色 AssumeRole 授予管道账户中提取角色的权限。
有关详细步骤和 IAM policy 示例,请参阅提供跨账户摄取访问权限。
