本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
事件溯源模式
意图
在事件驱动架构中,事件溯源模式将导致状态更改的事件存储在数据存储中。这有助于捕获和维护有关状态变化的完整历史记录,并可提高可审计性、可追溯性和分析过去状态的能力。
动机
多个微服务可以协作处理请求,并且它们通过事件进行通信。这些事件可能导致状态(数据)更改。按照事件对象的出现顺序来存储可以提供有关数据实体当前状态的宝贵信息,以及有关数据实体如何到达该状态的其他信息。
适用性
在以下情况下使用事件溯源模式:
-
跟踪需要应用程序中发生事件的不可变历史记录。
-
多语言数据预测需要来自单一事实来源(SSOT)。
-
Point-in 需要对应用程序状态进行时间重构。
-
Long-term 不需要存储应用程序状态,但您可能需要根据需要对其进行重建。
-
工作负载具有不同的读取和写入卷。例如,您有不需要实时处理的写入密集型工作负载。
-
需要更改数据捕获(CDC)来分析应用程序性能和其他指标。
-
出于报告和合规目的,系统中发生的所有事件都需要审计数据。
-
您想通过在重播过程中更改(插入、更新或删除)事件来派生假设场景,进而确定可能的结束状态。
问题和注意事项
-
乐观并发控制:此模式存储导致系统状态更改的每个事件。多个用户或服务可能尝试同时更新同一条数据,从而导致事件冲突。当同时创建和应用冲突事件时,便会发生这些冲突,从而导致最终的数据状态与现实不符。要解决此问题,您可以实施策略来检测事件冲突并解决冲突。例如,您可以通过纳入版本控制或向事件添加时间戳来跟踪更新顺序,从而实现乐观的并发控制方案。
-
复杂度:实施事件溯源需要将思维方式从传统的 CRUD 运营转变为事件驱动的思维。用于将系统恢复到其原始状态的重播过程可能很复杂,用以确保数据的幂等性。事件存储、备份和快照也会增加复杂度。
-
最终一致性:由于使用命令查询责任分割(CQRS)模式或实体化视图更新数据会出现延迟,因此从事件中派生的数据预测是最终一致的。当使用者处理来自事件存储的数据且发布者发送新数据时,数据投影或应用程序对象可能无法代表当前状态。
-
查询:与传统数据库相比,从事件日志中检索当前数据或聚合数据可能更复杂、更耗时,对于复杂的查询和报告任务尤其如此。为了缓解此问题,通常使用 CQRS 模式实现事件溯源。
-
事件存储的大小和成本:随着事件的持续持久化,事件存储的大小可能会呈指数级增长,尤其是在事件吞吐量高或保留期较长的系统中。因此,您必须定期将事件数据归档到经济高效的存储中,以防止事件存储变得过大。
-
事件存储的可扩展性:事件存储必须同时有效地处理大量的写入和读取操作。扩展事件存储可能具有挑战性,因此拥有可提供分片和分区的数据存储非常重要。
-
效率和优化:选择或设计可高效处理写入和读取操作的事件存储。应针对应用程序的预期事件量和查询模式,优化事件存储。在重构应用程序状态时,实施索引和查询机制可以加快事件的检索速度。您也可以考虑使用提供查询优化功能的专门事件存储数据库或库。
-
快照:您必须通过基于时间的激活定期对事件日志进行备份。重播上次已知成功备份数据时的事件,应该会导致应用程序状态的时间点恢复。恢复点目标(RPO)是指自上一个数据恢复点以来可接受的最长时间。RPO 决定了从上一个恢复点到服务中断之间,可接受的数据丢失情况。数据和事件存储每日快照的频率应基于应用程序的 RPO 确定。
-
时间敏感性:按其发生顺序对事件进行存储。因此,在实施此模式时,网络可靠性是需要考虑的重要因素之一。延迟问题可能导致不正确的系统状态。使用最多一次的先入先出(FIFO)队列将事件传送到事件存储。
-
事件重播性能:重播大量事件以重构当前应用程序状态,可能很耗时。需要进行优化以提高性能,尤其是在重播归档数据中的事件时。
-
外部系统更新:使用事件溯源模式的应用程序可能会更新外部系统中的数据存储,并可能将这些更新捕获为事件对象。在事件重播期间,如果外部系统预计不会有更新,则这种情况可能会成为问题。在这种情况下,您可以使用功能标志来控制外部系统的更新。
-
外部系统查询:当外部系统调用对调用的日期和时间敏感时,可以将接收到的数据存储在内部数据存储中,以便在重播期间使用。
-
事件版本控制:随着应用程序的发展,事件(架构)的结构可能更改。需要对事件实施版本控制策略,以确保向后和向前兼容。这可能包括在事件有效负载中包含版本字段,并在重播期间适当地处理不同的事件版本。
实施
High-level 建筑
命令和事件
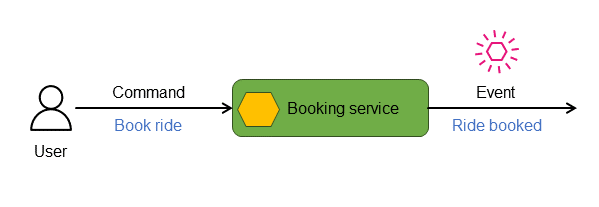
在分布式、事件驱动的微服务应用程序中,命令代表发送至服务的指令或请求,其目的通常是启动其状态的更改。该服务会处理这些命令,并评估命令的有效性和对当前状态的适用性。如果命令成功运行,则该服务会发出一个表示所采取的操作和相关状态信息的事件,进行响应。例如,在下图中,预订服务通过发出“乘车已预订”事件来响应“预定乘车”命令。
事件存储
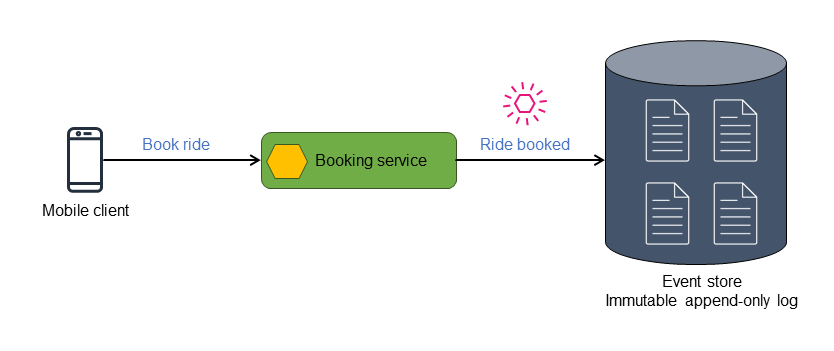
事件记录到不可变、仅追加、按时间顺序排列的存储库,或称为事件存储的数据存储中。每个状态更改都会被视为一个单独的事件对象。通过按事件发生顺序重播事件,可以重构具有已知初始状态、当前状态和任何时间点视图的实体对象或数据存储。
事件存储充当所有操作和状态变化的历史记录,也是宝贵的单一事实来源。您可以使用事件存储通过重播处理器传递事件,进而派生系统的最终最新状态;重播处理器应用这些事件来生成最新系统状态的准确表示。您还可以使用事件存储通过重播处理器重播事件,从而生成状态的时间点视角。在事件溯源模式中,最新事件对象可能无法完全代表当前状态。您可以通过以下三种方式之一派生当前状态:
-
通过汇总相关事件。将相关的事件对象组合起来生成当前状态以供查询。这种方法通常与 CQRS 模式结合使用,因为事件被合并并写入只读数据存储中。
-
通过使用实体化视图。您可以使用带有实体化视图模式的事件溯源来计算或汇总事件数据,并获取相关数据的当前状态。
-
通过重播事件。可以重播事件对象,以执行生成当前状态的操作。
下图显示了存储在事件存储中的 Ride booked 事件。
事件存储发布其存储的事件,然后可以对事件进行筛选并路由到相应的处理器以进行后续操作。例如,可以将事件路由到视图处理器,该处理器汇总状态并显示实体化视图。将事件转换为目标数据存储的数据格式。可以将对这种架构进行扩展,以派生不同类型的数据存储,从而实现数据的多语言持久性。
下图介绍了乘车预订应用程序中的事件。应用程序内发生的所有事件都会存储在事件存储中。然后,对存储的事件进行筛选,并路由至不同的使用者。
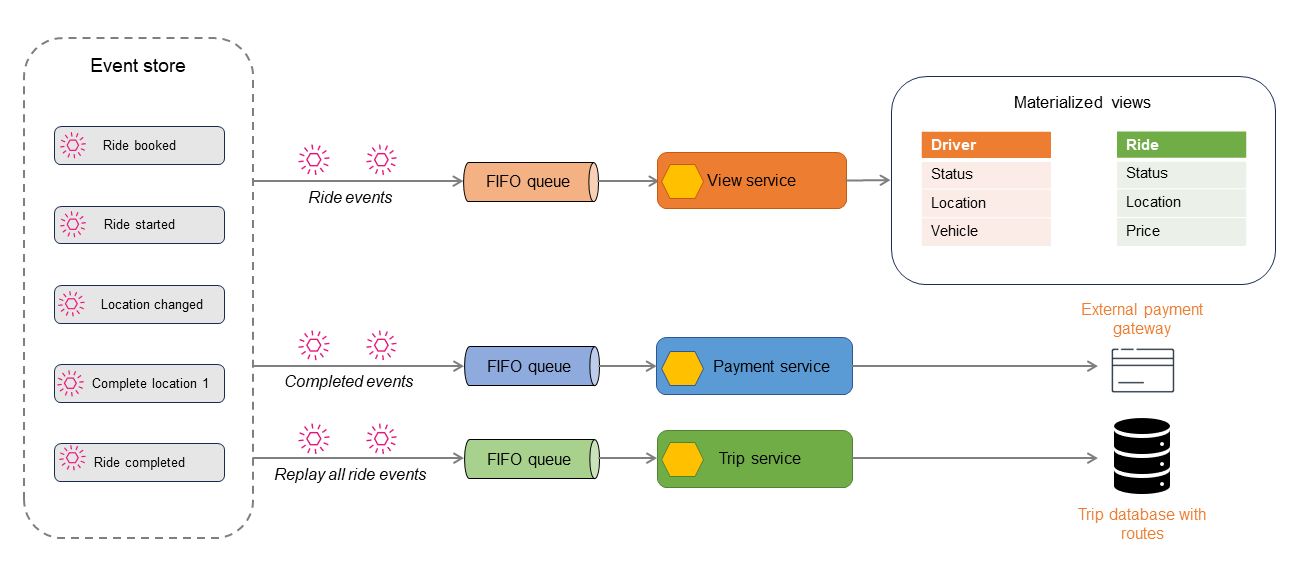
通过使用 CQRS 或实体化视图模式,乘车事件可用于生成只读数据存储。您可以通过查询读取存储来获取乘车、司机或预订的当前状态。某些事件(例如 Location changed 或 Ride completed)会发布给其他使用者进行付款处理。乘车完成后,将重播所有乘车事件,以建立乘车历史记录,供审计或报告之用。
事件溯源模式通常用于需要时间点恢复的应用程序,也经常用于必须使用单一事实来源以不同的格式投影数据时。这两种操作都需要重播过程来运行事件并派生所需的结束状态。重播处理器可能还需要一个已知的起点,理想情况下不需要从应用程序启动开始,因为那不够高效。建议您定期拍摄系统状态的快照,并应用较少的事件来派生最新的状态。
使用亚马逊云科技服务来实施
在以下架构中,将 Amazon Kinesis Data Streams 用作事件存储。该服务将应用程序更改作为事件,对其进行捕获和管理,并提供高吞吐量和实时数据流解决方案。要在 AWS 上实施事件采购模式,您还可以根据应用程序的需求使用亚马逊 EventBridge 和适用于 Apache Kafka 的亚马逊托管流媒体(亚马逊 MSK)等服务。
为了增强持久性并支持审计,您可以将 Kinesis Data Streams 捕获的事件归档到 Amazon Simple Storage Service(Amazon S3)中。此双存储方法有助于安全地保留历史事件数据,以备将来分析和合规之用。
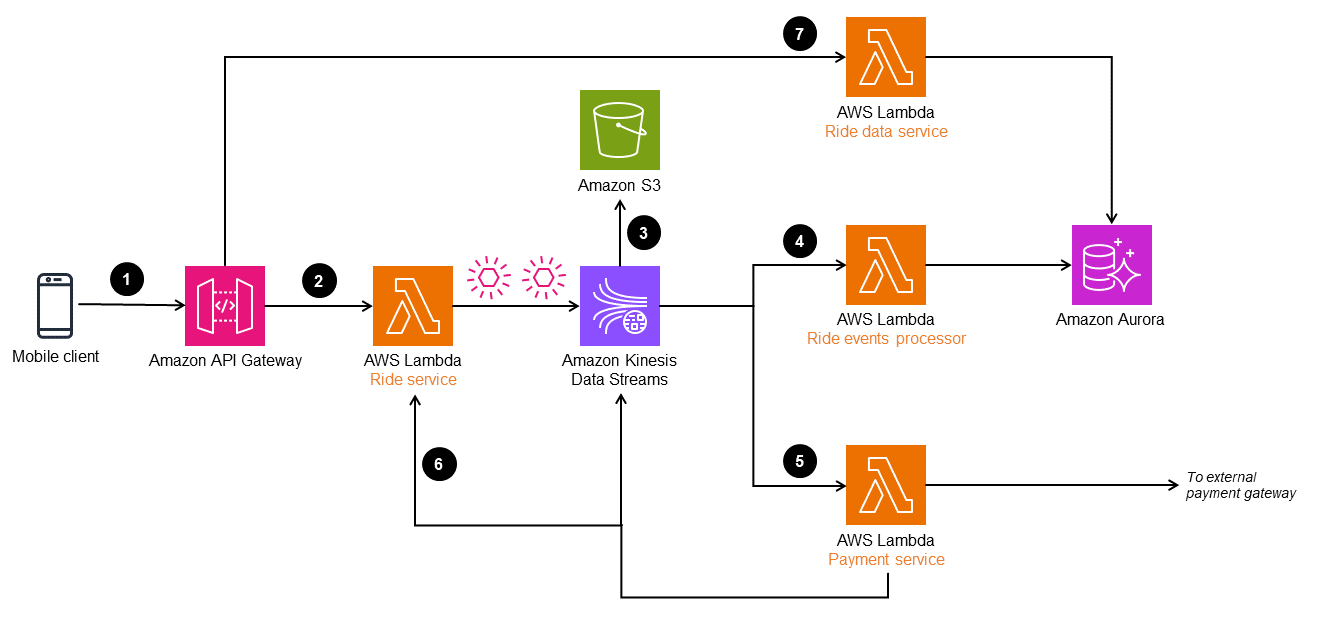
工作流包含以下步骤:
-
乘车预订请求是通过移动客户端向 Amazon API Gateway 端点提出的。
-
乘车微服务(
Ride serviceLambda 函数)接收请求,转换对象,然后发布到 Kinesis Data Streams。 -
将 Kinesis Data Streams 中的事件数据存储在 Amazon S3 中,以用于合规和审计历史记录。
-
这些事件由
Ride event processorLambda 函数转换和处理,并存储在 Amazon Aurora 数据库中,为乘车数据提供实体化视图。 -
已完成的乘车事件会被筛选并发送到外部支付网关进行付款处理。付款完成后,将向 Kinesis Data Streams 发送另一个事件以更新乘车数据库。
-
乘车完成后,乘车事件将重播到
Ride serviceLambda 函数中,以构建路线和乘车历史记录。 -
乘车信息可通过
Ride data service读取,该服务从 Aurora 数据库读取信息。
API Gateway 还可以在无需 Ride service Lambda 函数的情况下,将事件对象直接发送到 Kinesis Data Streams。但是,在叫车服务等复杂系统中,可能需要对事件对象进行处理和丰富,然后才能将其摄入数据流。出于这个原因,该架构具有在将事件发送到 Kinesis Data Streams 之前对其进行处理的 Ride service。
参考博客文章
