本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Database-per-service 图案
松耦合是微服务架构的核心特征,因为每项单独的微服务都可以独立地从自己的数据存储中存储和检索信息。通过部署单项服务数据库模式,您可以根据应用程序和业务需求选择最合适的数据存储(例如,关系数据库或非关系数据库)。这意味着微服务不共享数据层,对微服务单个数据库的更改不会影响其他微服务,其他微服务无法直接访问单个数据存储,并且只能通过 API 访问持久数据。解耦数据存储还可以提高整个应用程序的弹性,并确保单个数据库不会出现单点故障。
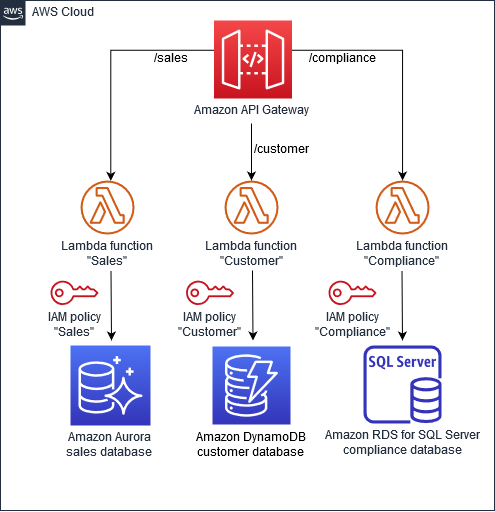
在下图中,“销售”、“客户” 和 “合规” 微服务使用不同的 AWS 数据库。这些微服务作为 AWS Lambda 函数部署,并通过 Amazon API Gateway API 进行访问。 AWS Identity and Access Management (IAM) 策略可确保数据保密,不在微服务之间共享。每项微服务都使用满足其各自需求的数据库类型;例如,“销售”使用 Amazon Aurora,“客户”使用 Amazon DynamoDB,“合规”使用适用于 SQL Server 的 Amazon Relational Database Service (Amazon RDS)。
若为以下情况,您应该考虑使用这种模式:
-
您的微服务之间需要松耦合。
-
微服务对其数据库有不同的合规性或安全性要求。
-
需要对扩展进行更精细的控制。
使用单项服务数据库模式有以下劣势:
-
实施跨多个微服务或数据存储的复杂事务和查询可能很具挑战性。
-
您必须管理多个关系数据库和非关系数据库。
-
您的数据存储必须满足 CAP 定理
的两项要求:一致性、可用性或分区容错性。
