本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Apache Spark 中的关键话题
本节介绍了 Apache Spark 的基本概念和调整 Apache Spark 性能 AWS Glue 的关键主题。在讨论现实世界的调整策略之前,了解这些概念和主题很重要。
架构
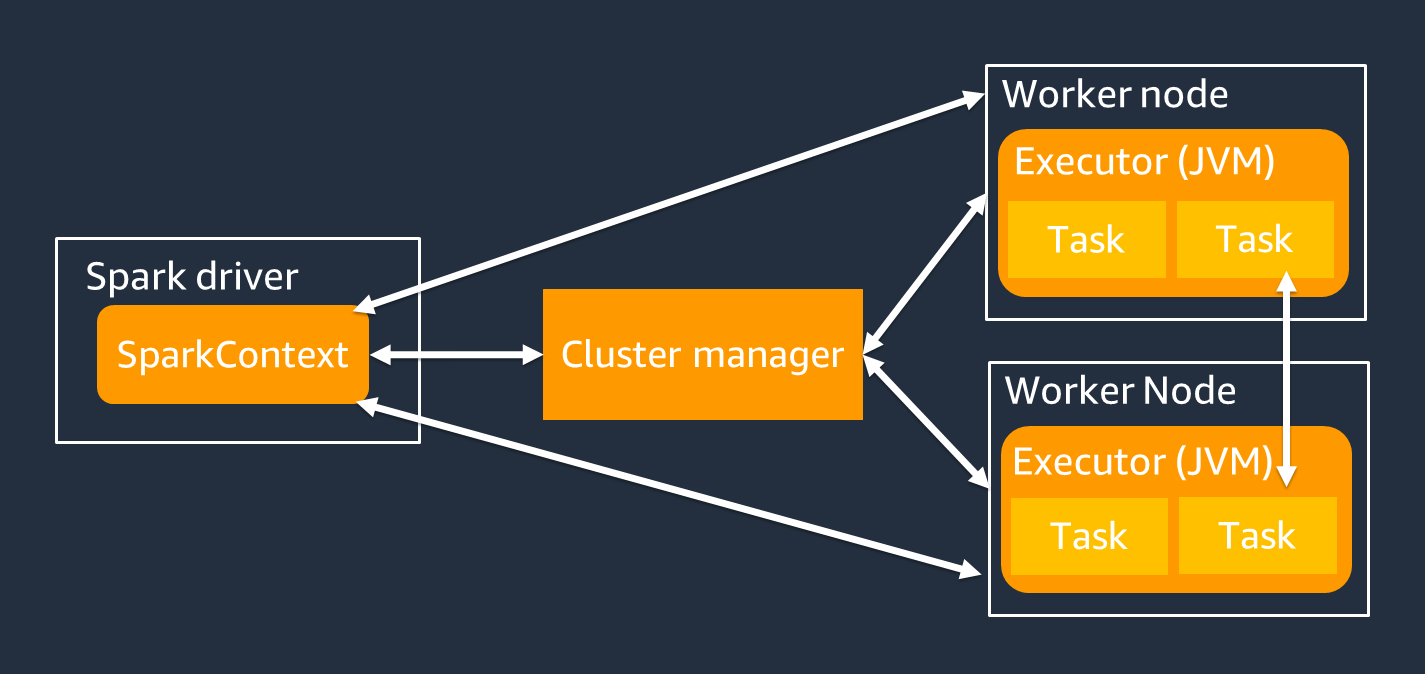
Spark 驱动程序主要负责将您的 Spark 应用程序拆分为可由单个工作人员完成的任务。Spark 驱动程序有以下职责:
-
main()在你的代码中运行 -
生成执行计划
-
与集群管理器一起配置 Spark 执行器,集群管理器管理集群上的资源
-
为 Spark 执行者安排任务和请求任务
-
管理任务进度和恢复
在作业运行中,您可以使用SparkContext对象与 Spark 驱动程序进行交互。
Spark 执行器是用于保存数据和运行从 Spark 驱动程序传递的任务的工作程序。Spark 执行者的数量将随着集群的大小而增加和减少。
注意
Spark 执行器有多个插槽,因此可以并行处理多个任务。默认情况下,Spark 支持每个虚拟 CPU (vCPU) 内核执行一项任务。例如,如果执行器有四个 CPU 内核,则它可以同时运行四个任务。
弹性分布式数据集
Spark 负责存储和跟踪 Spark 执行器间的大型数据集的复杂工作。在为 Spark 作业编写代码时,无需考虑存储的细节。Spark 提供了弹性分布式数据集 (RDD) 抽象,这是一组可以并行操作的元素,可以跨集群的 Spark 执行器进行分区。
下图显示了 Python 脚本在典型环境中运行和在 Spark 框架 (PySpark) 中运行时,如何将数据存储在内存中的差异。
![Python val [1,2,3 N],Apache Spark rdd = sc.parallelize [1,2,3 N]。](images/store-data-memory.png)
-
Python — 使用 Python 脚本编写
val = [1,2,3...N]可将数据保存在运行代码的单台计算机上的内存中。 -
PySpark— Spark 提供 RDD 数据结构,用于加载和处理分布在多个 Spark 执行器上的内存中的数据。您可以使用诸如之类的代码生成 RDD
rdd = sc.parallelize[1,2,3...N],并且 Spark 可以自动在多个 Spark 执行器之间分发数据并将其保存到内存中。在许多 AWS Glue 工作中,你可以使用 throu RDDs gh AWS Glue DynamicFrames和 Spark DataFrames。这些抽象允许您定义 RDD 中的数据架构,并使用这些附加信息执行更高级别的任务。由于它们在 RDDs 内部使用,因此数据在以下代码中以透明方式分发并加载到多个节点:
-
DynamicFrame
dyf= glueContext.create_dynamic_frame.from_options( 's3', {"paths": [ "s3://<YourBucket>/<Prefix>/"]}, format="parquet", transformation_ctx="dyf" ) -
DataFrame
df = spark.read.format("parquet") .load("s3://<YourBucket>/<Prefix>")
-
RDD 具有以下功能:
-
RDDs 由分成多个部分的数据组成,称为分区。每个 Spark 执行器在内存中存储一个或多个分区,数据分布在多个执行器上。
-
RDDs 是不可变的,这意味着它们在创建后无法更改。要更改 a DataFrame,您可以使用变换,这些变换将在下一节中定义。
-
RDDs 跨可用节点复制数据,以便它们可以自动从节点故障中恢复。
懒惰的评估
RDDs 支持两种类型的操作:变换(从现有数据集创建新数据集)和操作(在对数据集运行计算后向驱动程序返回值)。
-
变换 — 因为变换 RDDs 是不可变的,所以只能通过使用转换来更改它们。
例如,
map是一种转换,它将每个数据集元素传递给一个函数,然后返回一个表示结果的新 RDD。请注意,该map方法不返回输出。Spark 存储未来的抽象转换,而不是让你与结果进行交互。在你调用操作之前,Spark 不会对变换采取行动。 -
操作-使用转换,您可以制定逻辑转换计划。要启动计算,请运行诸如、
writecountshow、或collect之类的操作。Spark 中的所有转换都是懒惰的,因为它们不会立即计算结果。相反,Spark 会记住应用于某些基础数据集的一系列转换,例如亚马逊简单存储服务 (Amazon S3) Service 对象。只有当操作要求将结果返回给驱动程序时,才会计算变换。这种设计使Spark能够更高效地运行。例如,假设通过
map转换创建的数据集仅被大幅减少行数的转换所消耗,例如reduce。然后,您可以将经过两次转换的较小数据集传递给驱动程序,而不是传递较大的映射数据集。
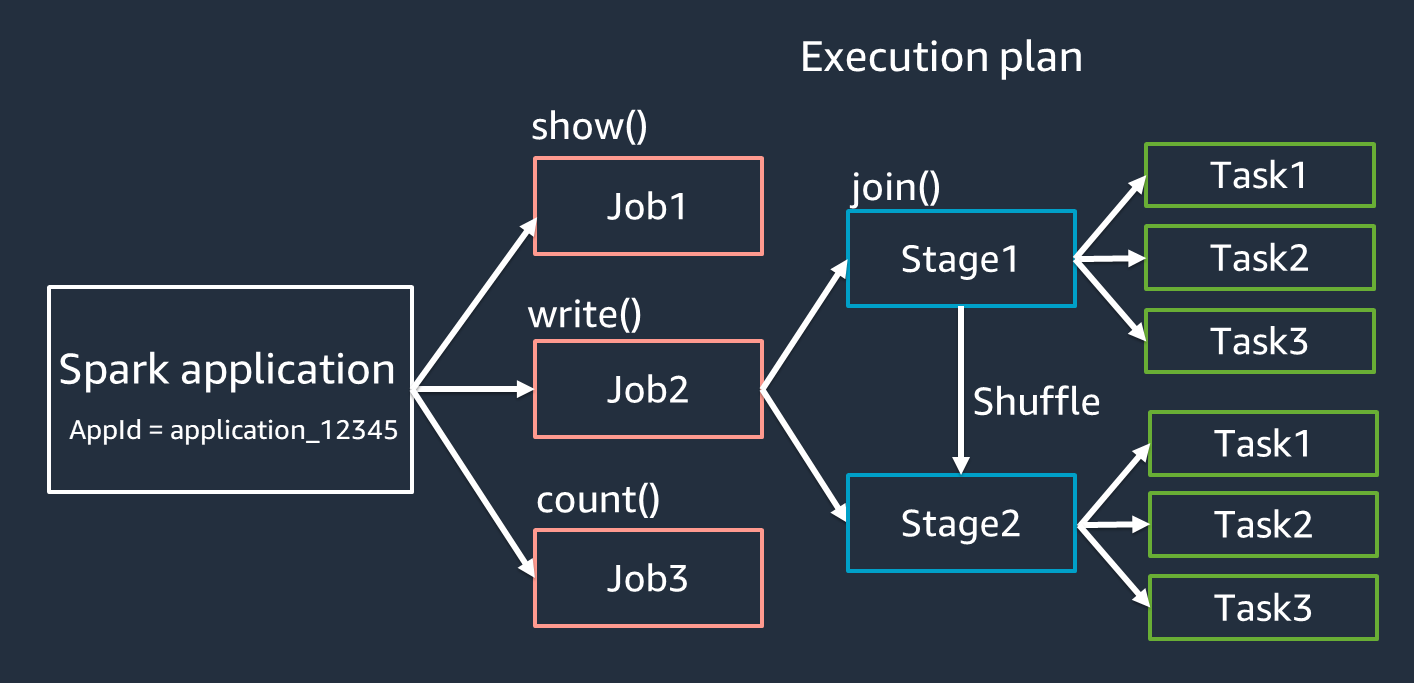
Spark 应用程序的术语
本节介绍了 Spark 应用程序的术语。Spark 驱动程序创建执行计划,并以多种抽象形式控制应用程序的行为。以下术语对于使用 Spark UI 进行开发、调试和性能调整非常重要。
-
应用程序-基于 Spark 会话(Spark 上下文)。由唯一 ID 标识,例如
<application_XXX>。 -
作业-基于为 RDD 创建的操作。一项作业由一个或多个阶段组成。
-
阶段 — 基于为 RDD 创建的洗牌。一个阶段由一个或多个任务组成。shuffle 是 Spark 用于重新分配数据的机制,以便在 RDD 分区中对数据进行不同的分组。某些变换(例如
join())需要随机播放。在 “优化洗牌” 调整练习中更详细地讨论了随机播放。 -
任务-任务是 Spark 计划的最小处理单位。为每个 RDD 分区创建任务,任务数是该阶段同时执行的最大数量。
注意
在优化并行度时,任务是需要考虑的最重要因素。任务的数量随RDD的数量而变化
并行
Spark 对加载和转换数据的任务进行并行处理。
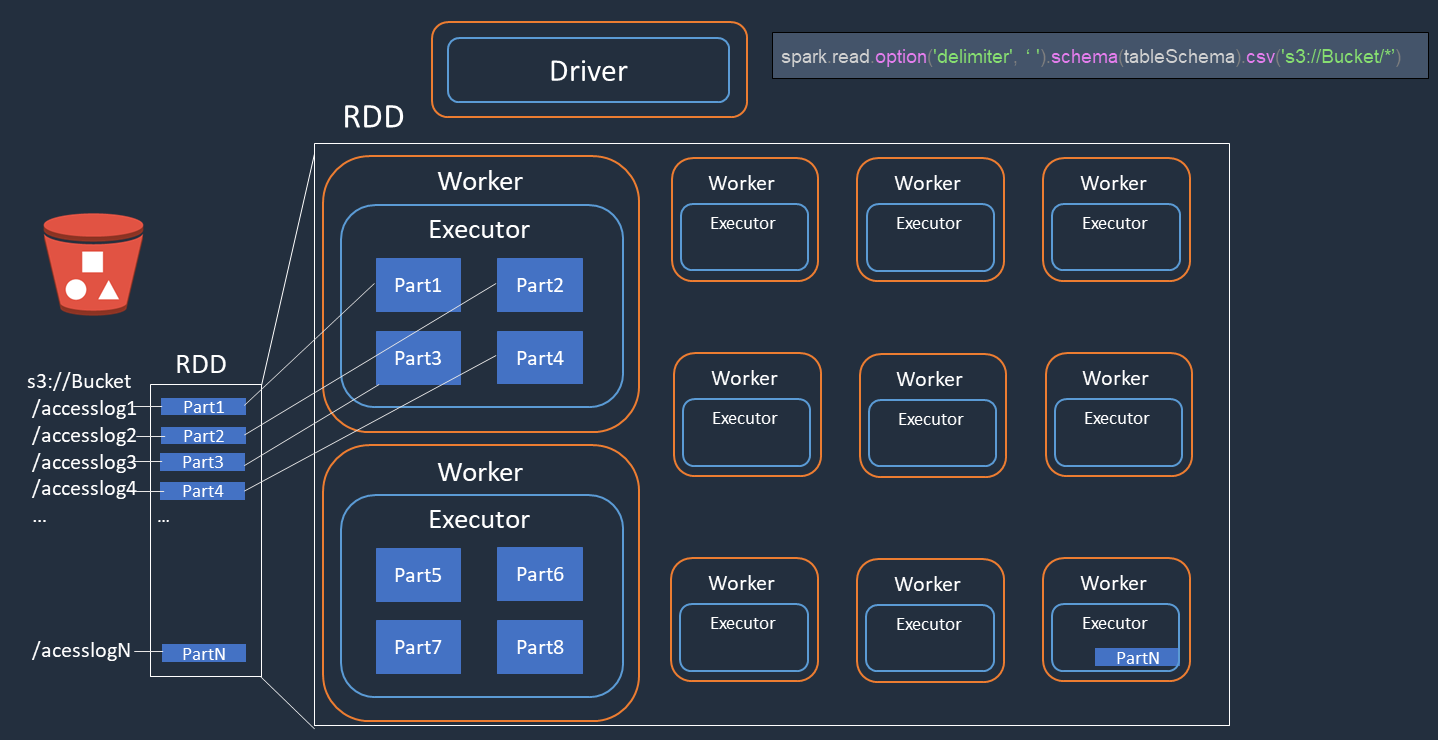
举一个示例,您在 Amazon S3 上对访问日志文件(命名accesslog1 ... accesslogN)执行分布式处理。下图显示了分布式处理流程。
-
Spark 驱动程序创建执行计划,用于在许多 Spark 执行器之间进行分布式处理。
-
Spark 驱动程序根据执行计划为每个执行者分配任务。默认情况下,Spark 驱动程序会为每个 S3 对象 () 创建 RDD 分区(每个分区对应一个 Spark 任务
Part1 ... N)。然后,Spark 驱动程序将任务分配给每个执行者。 -
每个 Spark 任务都会下载其分配的 S3 对象,并将其存储在 RDD 分区的内存中。这样,多个 Spark 执行器就可以并行下载和处理其分配的任务。
有关初始分区数量和优化的更多详细信息,请参阅 Parallelize 任务部分。
催化剂优化器
在内部,Spark 使用名为 Catalyst 优化器的
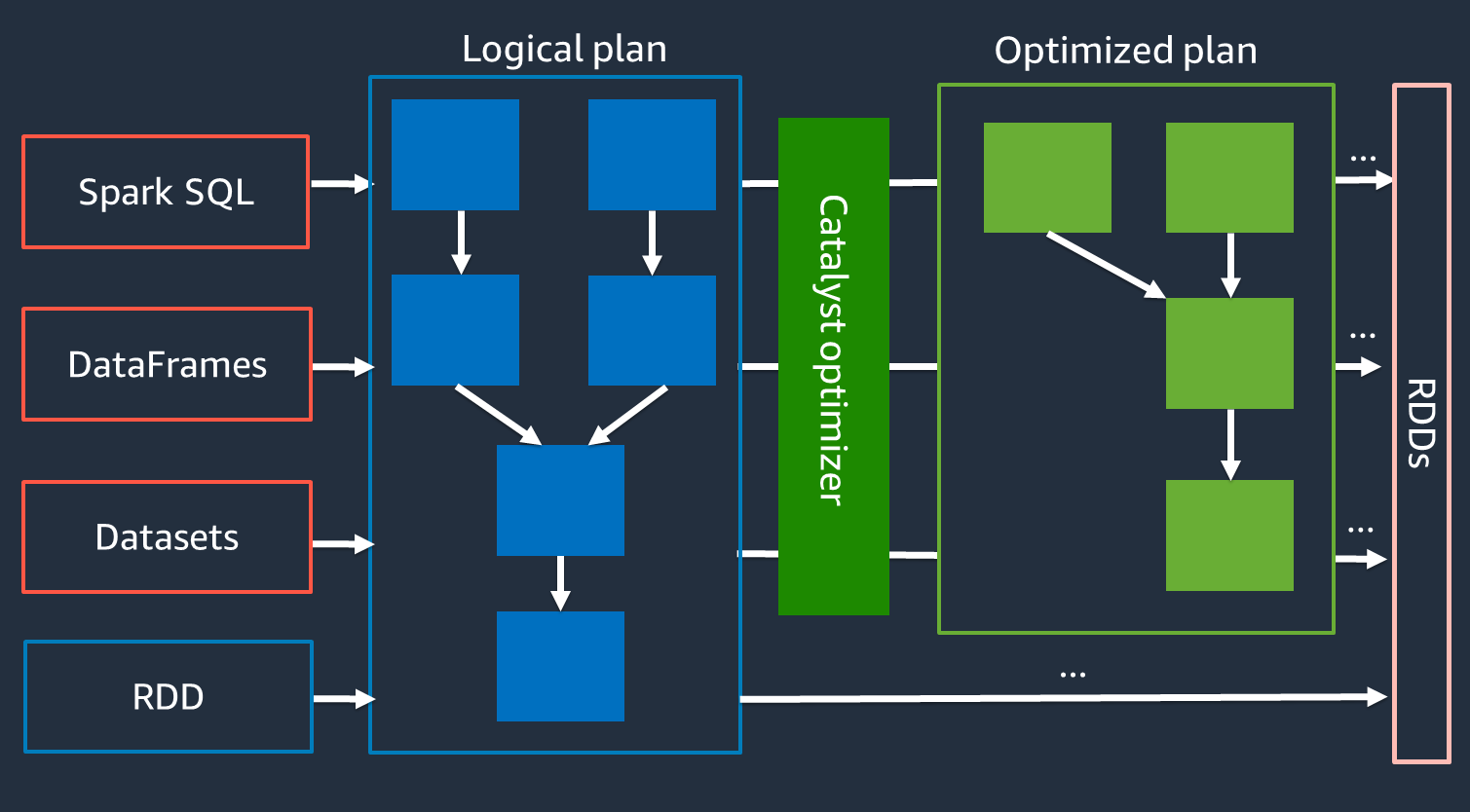
由于 Catalyst 优化器不能直接与 RDD API 配合使用,因此高级优化器 APIs 通常比低级 RDD API 更快。对于复杂联接,Catalyst 优化器可以通过优化作业运行计划来显著提高性能。你可以在 Spark 用户界面的 SQL 选项卡上查看 Spark 作业的优化计划。
自适应查询执行
Catalyst 优化器通过名为 “自适应查询执行” 的过程来执行运行时优化。自适应查询执行使用运行时统计信息在作业运行时重新优化查询的运行计划。Adaptive Query Execution 为性能挑战提供了多种解决方案,包括合并洗牌后的分区、将排序合并联接转换为广播联接以及倾斜联接优化,如以下各节所述。
自适应查询执行在 AWS Glue 3.0 及更高版本中可用,在 AWS Glue 4.0(Spark 3.3.0)及更高版本中默认启用。可以在代码spark.conf.set("spark.sql.adaptive.enabled",
"true")中使用来开启和关闭自适应查询执行。
合并洗牌后的分区
此功能根据输出统计信息在每次洗牌后减少 RDD 分区(合并)。map它简化了运行查询时对 shuffle 分区号的调整。您无需设置 shuffle 分区号即可适合您的数据集。在你有足够大的初始洗牌分区数之后,Spark 可以在运行时选择正确的洗牌分区号。
当spark.sql.adaptive.enabled和spark.sql.adaptive.coalescePartitions.enabled都设置为 true 时,将启用合并后洗牌分区。有关更多信息,请参阅 Apache Spark 文档
将排序合并联接转换为广播联接
此功能可识别您何时连接两个大小截然不同的数据集,并根据该信息采用更有效的联接算法。有关更多详细信息,请参阅 Apache Spark 文档
倾斜连接优化
数据倾斜是 Spark 作业最常见的瓶颈之一。它描述了一种情况,即数据偏向特定 RDD 分区(以及随之而来的特定任务),这会延迟应用程序的总体处理时间。这通常会降低联接操作的性能。倾斜联接优化功能通过将倾斜的任务拆分(并在需要时复制)为大小大致相等的任务来动态处理排序合并联接中的偏差。
此功能在设置spark.sql.adaptive.skewJoin.enabled为 true 时启用。有关更多详细信息,请参阅 Apache Spark 文档
