本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
并行化任务
要优化性能,必须并行处理数据加载和转换任务。正如我们在 Apache Spark 的关键主题中所讨论的那样,弹性分布式数据集 (RDD) 分区的数量很重要,因为它决定了并行度。Spark 创建的每个任务都以 1:1 的方式对应一个 RDD 分区。要获得最佳性能,您需要了解 RDD 分区数量是如何确定的,以及如何优化该数量。
如果您没有足够的并行度,则将在CloudWatch指标和 Spark UI 中记录以下症状。
CloudWatch 指标
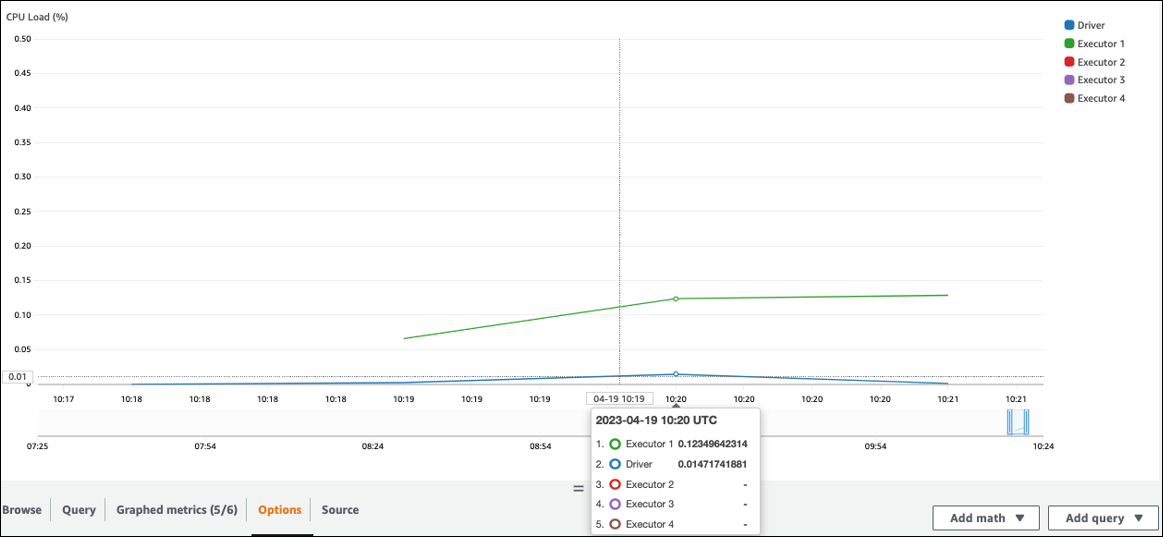
检查 CPU 负载和内存利用率。如果某些执行器在工作的某个阶段没有进行处理,那么改进并行度是合适的。在本例中,在可视化时间范围内,E xecutor 1 正在执行一项任务,但其余的执行者(2、3 和 4)却没有。你可以推断出 Spark 驱动程序没有为这些执行者分配任务。
Spark UI
在 Spark 用户界面的舞台选项卡上,您可以看到一个阶段中的任务数量。在本例中,Spark 只执行了一项任务。

此外,事件时间轴显示 E xecutor 1 正在处理一项任务。这意味着该阶段的工作完全由一个执行人完成,而其他执行人则处于闲置状态。

如果您发现这些症状,请针对每个数据源尝试以下解决方案。
并行处理来自 Amazon S3 的数据加载
要并行处理从 Amazon S3 加载的数据,请先检查默认分区数。然后,您可以手动确定分区的目标数量,但一定要避免分区过多。
确定默认分区数
对于 Amazon S3,Spark RDD 分区的初始数量(每个分区对应于一个 Spark 任务)由您的 Amazon S3 数据集的特征(例如格式、压缩和大小)决定。当您使用存储在 Amazon S3 DataFrame 中的 CSV 对象创建 AWS Glue DynamicFrame或 Spark 时,RDD 分区的初始数量 (NumPartitions) 可以大致计算如下:
-
对象大小 <= 64 MB:
NumPartitions = Number of Objects -
对象大小 > 64 MB:
NumPartitions = Total Object Size / 64 MB -
不可拆分 (gzip):
NumPartitions = Number of Objects
如减少数据扫描量部分所述,Spark 将大型 S3 对象分成可以并行处理的拆分。当对象大于拆分大小时,Spark 会拆分对象,并为每次拆分创建一个 RDD 分区(和任务)。Spark 的拆分大小取决于您的数据格式和运行时环境,但这是一个合理的起始近似值。有些对象使用不可拆分的压缩格式(例如 gzip)进行压缩,因此 Spark 无法对其进行拆分。
该NumPartitions值可能会有所不同,具体取决于您的数据格式、压缩率、 AWS Glue 版本、 AWS Glue 工作器数量和 Spark 配置。
例如,当你使用 Spark 加载一个 10 GB 的csv.gz对象时 DataFrame,Spark 驱动程序将只创建一个 RDD 分区 (NumPartitions=1),因为 gzip 是不可拆分的。这会导致一个特定 Spark 执行器承受沉重的负担,并且不会将任何任务分配给其余的执行器,如下图所示。
在 Spark Web UI Stage 选项卡上查看该阶段的实际任务数 (NumPartitions),或者df.rdd.getNumPartitions()在代码中运行以检查并行度。
遇到 10 GB 的 gzip 文件时,请检查生成该文件的系统是否可以将其生成为可拆分的格式。如果这不是一个选项,则可能需要扩展集群容量来处理文件。要对加载的数据高效运行转换,您需要使用重新分区在集群中的工作程序之间重新平衡 RDD。
手动确定目标分区数
根据数据的属性和Spark对某些功能的实现,尽管底层工作仍然可以并行化,但最终的NumPartitions价值可能会很低。如果太小,NumPartitions则运行df.repartition(N)以增加分区的数量,以便可以将处理分布在多个 Spark 执行器上。
在这种情况下,运行df.repartition(100)将NumPartitions从 1 增加到 100,从而创建 100 个数据分区,每个分区都有可以分配给其他执行者的任务。
该操作repartition(N)将所有数据平均分开(10 GB/100 个分区 = 100 MB/分区),从而避免数据偏向某些分区。
注意
当运行诸如之类的洗牌操作join时,分区的数量会根据或的值动态增加spark.sql.shuffle.partitions或spark.default.parallelism减少。这便于在 Spark 执行者之间更有效地交换数据。有关更多信息,请参阅 Spark 文档
在确定目标分区数量时,您的目标是最大限度地利用已配置 AWS Glue 的工作程序。 AWS Glue 工作人员的数量和 Spark 任务的数量通过 v 的数量相关CPUs。 Spark 支持每个 vCPU 内核执行一项任务。在 3.0 或更高 AWS Glue 版本中,您可以使用以下公式计算目标分区数。
# Calculate NumPartitions by WorkerType numExecutors = (NumberOfWorkers - 1) numSlotsPerExecutor = 4 if WorkerType is G.1X 8 if WorkerType is G.2X 16 if WorkerType is G.4X 32 if WorkerType is G.8X NumPartitions = numSlotsPerExecutor * numExecutors # Example: Glue 4.0 / G.1X / 10 Workers numExecutors = ( 10 - 1 ) = 9 # 1 Worker reserved on Spark Driver numSlotsPerExecutor = 4 # G.1X has 4 vCpu core ( Glue 3.0 or later ) NumPartitions = 9 * 4 = 36
在此示例中,每个 G.1X 工作程序向 Spark 执行器 () 提供四个 vCPU 内核。spark.executor.cores = 4Spark 支持每个 vCPU 内核执行一个任务,因此 G.1X Spark 执行器可以同时运行四个任务()。numSlotPerExecutor如果任务花费的时间相等,则此数量的分区可以充分利用群集。但是,有些任务会比其他任务花费更长的时间,从而导致内核处于空闲状态。如果发生这种情况,可以考虑numPartitions乘以 2 或 3 来分解并有效地安排瓶颈任务。
分区太多
分区数量过多会导致任务数量过多。由于与分布式处理(例如管理任务和 Spark 执行器之间的数据交换)相关的开销,这会导致 Spark 驱动程序负载过重。
如果作业中的分区数量大大超过目标分区数,请考虑减少分区数量。您可以使用以下选项减少分区:
-
如果您的文件大小非常小,请使用 AWS Glue Group Files。您可以减少因启动 Apache Spark 任务来处理每个文件而导致的过度并行度。
-
用于
coalesce(N)将分区合并在一起。这是一个低成本的过程。减少分区数量时,优coalesce(N)于repartition(N),因为repartition(N)执行洗牌可以平均分配每个分区中的记录量。这会增加成本和管理开销。 -
使用 Spark 3.x 自适应查询执行。正如 Apache Spark 中的关键主题部分所述,自适应查询执行提供了一种自动合并分区数量的功能。当你在执行之前无法知道分区数量时,你可以使用这种方法。
并行化从 JDBC 加载数据
Spark RDD 分区的数量由配置决定。请注意,默认情况下,通过SELECT查询仅运行一个任务来扫描整个源数据集。
两者 AWS Glue DynamicFrames 和 Spark 都 DataFrames 支持跨多个任务并行加载 JDBC 数据。这是通过使用where谓词将一个查询拆分为多个SELECT查询来完成的。要并行化从 JDBC 读取,请配置以下选项:
-
对于 AWS Glue DynamicFrame,设置
hashfield(或hashexpression)和hashpartition。要了解更多信息,请参阅并行读取 JDBC 表。connection_mysql8_options = { "url": "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test", "dbtable": "medicare_tb", "user": "test", "password": "XXXXXXXXX", "hashexpression":"id", "hashpartitions":"10" } datasource0 = glueContext.create_dynamic_frame.from_options( 'mysql', connection_options=connection_mysql8_options, transformation_ctx= "datasource0" ) -
对于 Spark DataFrame
numPartitions,请设置partitionColumnlowerBound、、和upperBound。要了解更多信息,请参阅 JDBC 到其他数据库。df = spark.read \ .format("jdbc") \ .option("url", "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test") \ .option("dbtable", "medicare_tb") \ .option("user", "test") \ .option("password", "XXXXXXXXXX") \ .option("partitionColumn", "id") \ .option("numPartitions", "10") \ .option("lowerBound", "0") \ .option("upperBound", "1141455") \ .load() df.write.format("json").save("s3://bucket_name/Tests/sparkjdbc/with_parallel/")
使用 ETL 连接器时,从 DynamoDB 并行加载数据
Spark RDD 分区的数量由dynamodb.splits参数决定。要并行处理来自 Amazon DynamoDB 的读取,请配置以下选项:
-
增加的价值
dynamodb.splits。 -
按照 Spark 的 ETL 的连接类型和选项中所述的公式来优化参数。 AWS Glue
并行处理来自 Kinesis Data Streams 的数据加载
Spark RDD 分区的数量由源 Amazon Kinesis Data Streams 数据流中的分片数量决定。如果您的数据流中只有几个分片,则只有几个 Spark 任务。这可能会导致下游流程的并行度降低。要并行处理来自 Kinesis Data Streams 的读取,请配置以下选项:
-
从 Kinesis Data Streams 加载数据时,增加分片数量以获得更多的并行度。
-
如果您在微批处理中的逻辑足够复杂,请考虑在删除不需要的列之后,在批次开始时对数据进行重新分区。
有关更多信息,请参阅优化 AWS Glue 流式传输 ETL 作业的成本和性能的最佳实践
数据加载后并行执行任务
要在数据加载后并行执行任务,请使用以下选项增加 RDD 分区的数量:
-
重新分区数据以生成更多的分区,尤其是在无法并行处理加载本身的情况下,在初始加载之后立即生成。
在
repartition()DynamicFrame 或上调用 DataFrame,指定分区数。一个好的经验法则是可用内核数量的两到三倍。但是,在写入分区表时,这可能会导致文件爆炸式增长(每个分区都可能在每个表分区中生成一个文件)。为避免这种情况,您可以 DataFrame按列重新分区。它使用表分区列,因此在写入之前对数据进行整理。您可以指定更多数量的分区,而无需在表分区上放置小文件。但是,请注意避免数据倾斜,在这种倾斜中,某些分区值最终会包含大部分数据,从而延迟任务的完成。
-
出现洗牌时,增加该值。
spark.sql.shuffle.partitions这也可以帮助解决洗牌时的任何内存问题。当你的洗牌分区超过 2,001 个时,Spark 会使用压缩的内存格式。如果您有一个接近该值的数字,则可能需要将该
spark.sql.shuffle.partitions值设置为超过该限制以获得更有效的表示形式。
