本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
扩展集群容量
如果你的任务花费了太多时间,但执行者消耗了足够的资源,而且 Spark 创建的任务量与可用内核相比很大,可以考虑扩展集群容量。要评估这是否合适,请使用以下指标。
CloudWatch 指标
-
检查CPU负载和内存利用率以确定执行程序是否消耗了足够的资源。
-
检查作业运行了多长时间,以评估处理时间是否过长,无法实现您的绩效目标。
在以下示例中,四个执行器以超过 97% 的CPU负载运行,但是大约三个小时后处理仍未完成。
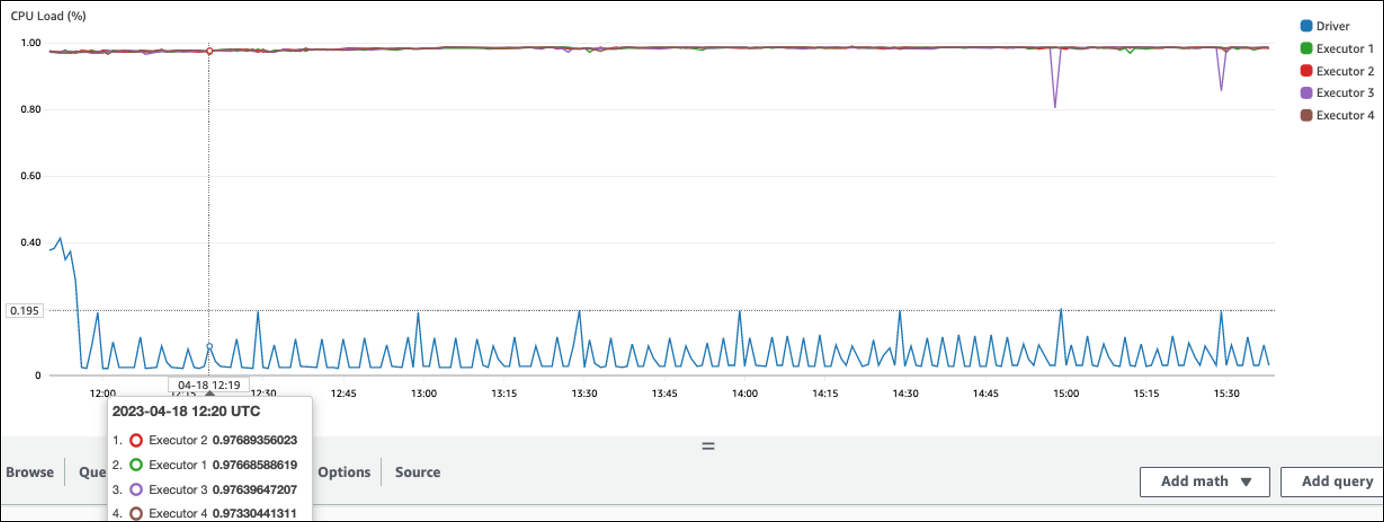
注意
如果CPU负载较低,您可能无法从扩展集群容量中受益。
Spark UI
在 Jo b 选项卡或 St age 选项卡上,您可以看到每个作业或阶段的任务数。在以下示例中,Spark 创建了58100任务。

在 Executor 选项卡上,您可以看到执行者和任务的总数。在以下屏幕截图中,每个 Spark 执行器都有四个内核,可以同时执行四个任务。
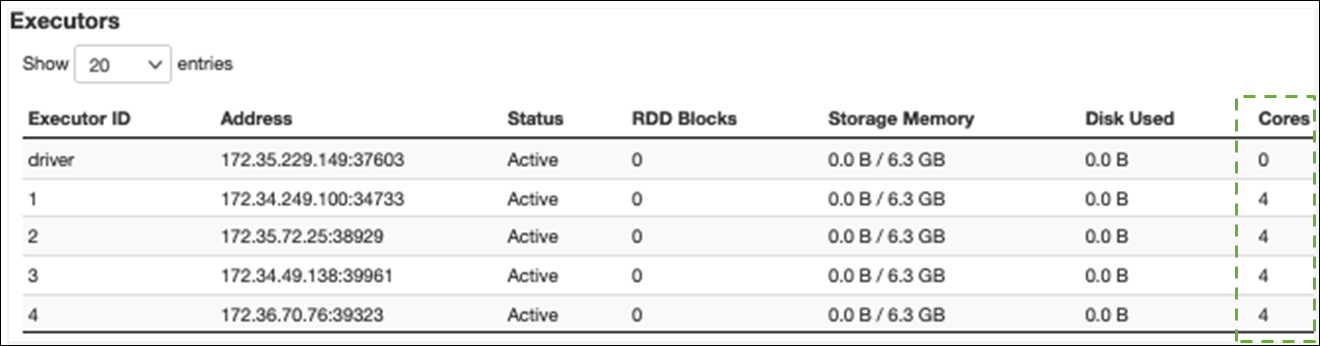
在此示例中,Spark 任务的数量(58100)远大于执行器可以同时处理的 16 个任务(4 个执行器 × 4 个内核)。
如果您发现这些症状,请考虑扩展集群。您可以使用以下选项扩展集群容量:
-
启用 AWS Glue Auto Sc aling — 在 3.0 或更高 AWS Glue 版本中,A uto Scaling 可用于 AWS Glue 提取、转换和加载 (ETL) 以及流式处理作业。 AWS Glue 根据每个阶段的分区数量或作业运行时生成微批量的速率,自动在集群中添加和移除工作程序。
如果您发现即使启用了 Auto Scaling,工作人员数量也不会增加,请考虑手动添加工作线程。但是,请注意,手动扩展一个阶段可能会导致许多工作人员在后期阶段处于闲置状态,而性能提升为零的成本更高。
启用 Auto Scaling 后,你可以在执行者指标中看到 CloudWatch 执行者的数量。使用以下指标来监控 Spark 应用程序中对执行者的需求:
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors -
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
有关指标的更多信息,请参阅AWS Glue 使用 Amazon CloudWatch 指标进行监控。
-
-
向外扩展:增加 AWS Glue 员工人数 — 您可以手动增加 AWS Glue 员工人数。仅在观察到闲置工作人员之前添加工作人员。那时,增加更多员工将增加成本,而不会改善业绩。有关更多信息,请参阅并行化任务。
-
向上扩展:使用更大的工作器类型 — 您可以手动更改 AWS Glue 工作程序的实例类型,以使用具有更多内核、内存和存储空间的工作程序。较大的工作线程类型使您可以垂直扩展和运行密集型数据集成作业,例如内存密集型数据转换、倾斜聚合以及涉及 PB 级数据的实体检测检查。
在 Spark 驱动程序需要更大容量的情况下,向上扩展还有帮助,例如,因为任务查询计划非常大。有关工作人员类型和绩效的更多信息,请参阅 AWS 大数据博客文章使用新的大型工作器 AWS Glue 类型 G.4X 和 G.8X 来扩展 Apache Spark 作业
。 使用较大的工作人员还可以减少所需的员工总数,从而减少密集型操作(例如加入)中的混乱,从而提高绩效。
