本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
创建数据集
注意
如果您要将大于 5 GB 的数据集导入 Amazon SageMaker Canvas,我们建议您使用 Canvas 中的 Data Wrangler 功能来创建数据流。Data Wrangler 支持高级数据准备功能,例如连接和串联数据。创建数据流后,您可以将数据流导出为 Canvas 数据集,然后开始构建模型。有关更多信息,请参阅 导出以创建模型。
以下各节介绍如何在 Amazon C SageMaker anvas 中创建数据集。对于自定义模型,您可以为表格和图像数据创建数据集。对于 Ready-to-use模型,您可以使用表格和图像数据集以及文档数据集。根据以下信息选择工作流:
一个数据集可以由多个文件组成。例如,您可能有多个 CSV 格式的库存数据文件。只要这些文件的架构(或列名和数据类型)匹配,就可以将这些文件作为数据集一起上传。
Canvas 还支持管理数据集的多个版本。创建数据集时,第一个版本将标记为 V1。您可以通过更新数据集来创建数据集的新版本。您可以手动更新,也可以设置自动使用新数据更新数据集的时间表。有关更多信息,请参阅 更新数据集。
将数据导入 Canvas 时,请确保数据符合下表中的要求。这些限制因您正在构建的模型类型不同而异。
| 限制 | 2 类别、3+ 类别、数值和时间序列模型 | 文本预测模型 | 图像预测模型 | *模型的 Ready-to-use文档数据 |
|---|---|---|---|---|
支持的文件类型 |
CSV 和 Parquet(本地上传、Amazon S3 或数据库) JSON(数据库) |
CSV 和 Parquet(本地上传、Amazon S3 或数据库) JSON(数据库) |
JPG、PNG |
PDF、JPG、PNG、TIFF |
最大文件大小 |
本地上传:5 GB 数据源: PBs |
本地上传:5 GB 数据源: PBs |
每张图像 30 MB |
每个文档 5 MB |
一次可以上传的最大文件数 |
30 |
30 |
不适用 |
不适用 |
最大列数 |
1000 |
1000 |
不适用 |
不适用 |
快速构建的最大条目数(行、图像或文档) |
不适用 |
7500 行 |
5000 张图像 |
不适用 |
标准构建的最大条目数(行、图像或文档) |
不适用 |
15 万行 |
18 万张图像 |
不适用 |
快速构建的最小条目(行)数 |
2 类别:500 行 3+ 类别、数值、时间序列:不适用 |
不适用 |
不适用 |
不适用 |
标准构建的最小条目数(行、图像或文档) |
250 行 |
50 行 |
50 张图像 |
不适用 |
|
每个标签的最小条目数(行或图像) |
不适用 |
25 行 |
25 行 |
不适用 |
最小标签数量 |
2 类别:2 3+ 类别:3 数值、时间序列:不适用 |
2 |
2 |
不适用 |
|
随机抽样的最小样本量 |
500 |
不适用 |
不适用 |
不适用 |
|
随机抽样的最小样本量 |
200,000 |
不适用 |
不适用 |
不适用 |
| 最大标签数量 |
2 类别:2 3+ 类别、数值、时间序列:不适用 |
1000 |
1000 |
不适用 |
*目前只有接受文档数据的Ready-to-use 模型才支持文档数据。您无法使用文档数据构建自定义模型。
另请注意以下限制:
-
从 Amazon S3 存储桶导入数据时,请确保 Amazon S3 存储桶的名称不包含
.。如果您的存储桶名称包含.,则在尝试将数据导入 Canvas 时可能会出错。 -
对于表格数据,Canvas 不允许在本地上传和 Amazon S3 导入时选择任何扩展名为 .csv、.parquet、.parq 和 .pqt 以外的文件。CSV 文件可以使用任何常用或自定义的分隔符,除非是表示新行,否则不得使用换行符。
-
对于使用 Parquet 文件的表格数据,请注意以下几点:
-
对于图像数据,如果您有任何未标注的图像,则必须在构建模型之前对其进行标注。有关如何在 Canvas 应用程序中为图像分配标签的信息,请参阅编辑图像数据集。
-
如果您设置了自动数据集更新或自动批量预测配置,则在 Canvas 应用程序中总共只能创建 20 个配置。有关更多信息,请参阅 如何管理自动化。
导入数据集后,您可以随时在数据集页面上查看自己的数据集。
导入表格数据
使用表格数据集,您可以构建分类、数值、时间序列预测和文本预测模型。查看前面导入数据集部分中的限制表,确保您的数据符合表格数据的要求。
使用以下过程将表格数据集导入 Canvas:
-
打开你的 SageMaker 画布应用程序。
-
在左侧导航窗格中,选择数据集。
-
选择导入数据。
-
从下拉菜单中,选择表格。
-
在弹出的对话框中,在数据集名称字段中,输入数据集的名称,然后选择创建。
-
在创建表格数据集页面上,打开数据来源下拉菜单。
-
选择您的数据来源:
-
要从计算机上传文件,请选择本地上传。
-
要从其他来源(例如 Amazon S3 存储桶或 Snowflake 数据库)导入数据,请在搜索数据来源栏中搜索您的数据来源。然后,选择所需数据来源对应的图块。
注意
您只能从具有活动连接的图块中导入数据。如果要连接到无法使用的数据来源,请联系您的管理员。如果您是管理员,请参阅连接到数据来源。
以下屏幕截图显示数据来源下拉菜单。

-
-
(可选)如果您是首次连接到 Amazon Redshift 或 Snowflake 数据库,则会出现一个用于创建连接的对话框。在对话框中填写您的凭证,然后选择创建连接。如果您已经有连接,请选择您的连接。
-
从您的数据来源中,选择要导入的文件。对于本地上传和从 Amazon S3 导入,您可以选择文件。仅适用于 Amazon S3,您还可以选择在输入 S3 端点字段中直接输入 S3 URI、别名、存储桶的 ARN 或 S3 接入点,然后选择要导入的文件。对于数据库源,您可以使用左侧导航窗格中的 drag-and-drop数据表。
-
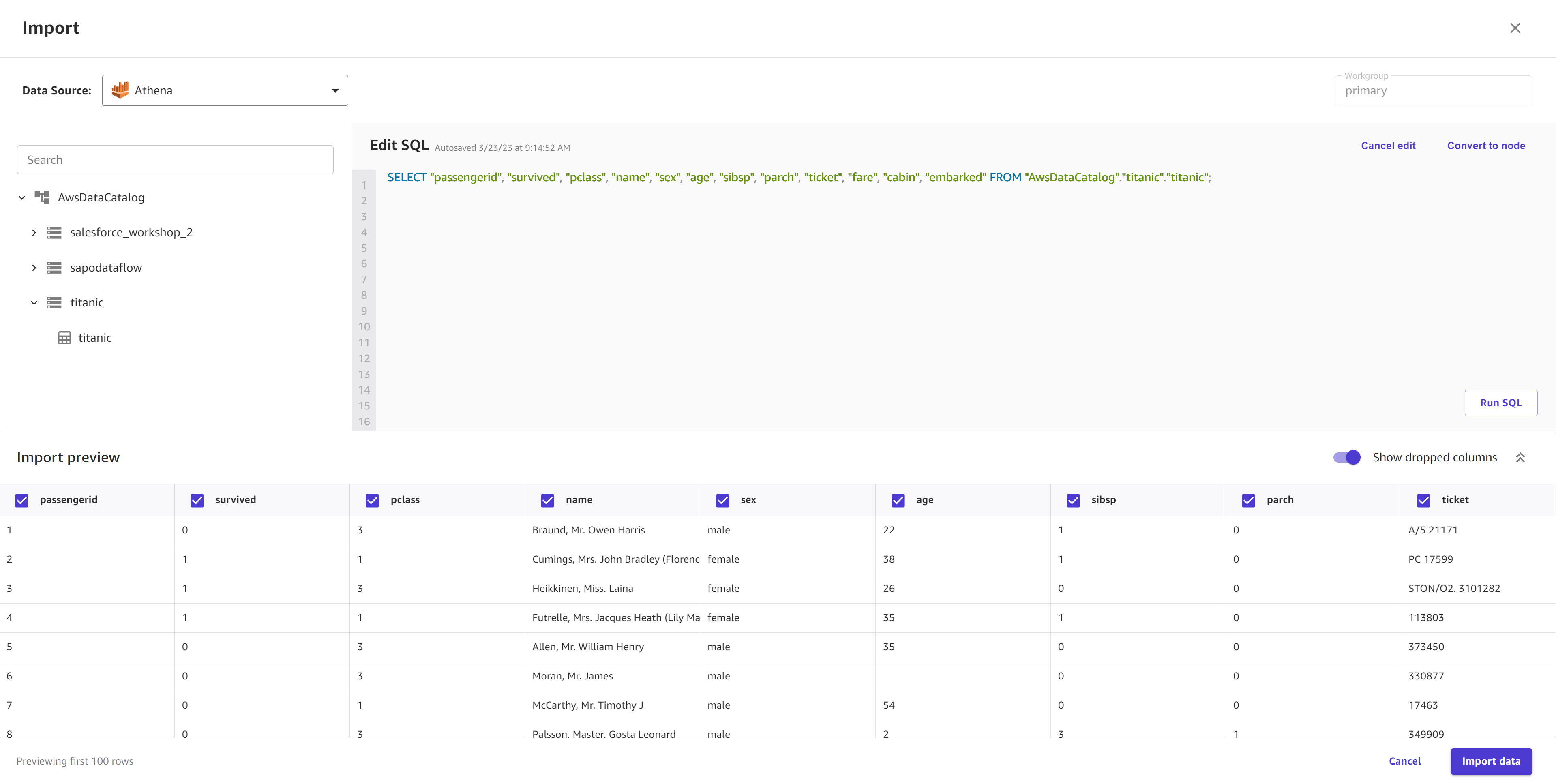
(可选)对于支持 SQL 查询的表格数据来源(例如 Amazon Redshift、Amazon Athena 或 Snowflake),您可以选择编辑 SQL,在导入前进行 SQL 查询。
以下屏幕截图显示了 Amazon Athena 数据来源的编辑 SQL 视图。
-
(可选)选择预览数据集,在导入数据前预览数据。
-
在导入设置中,输入数据集名称或使用默认数据集名称。
-
(可选)对于从 Amazon S3 导入的数据,系统会显示高级设置,您可以填写以下字段:
如果您要使用数据集的第一行作为列名,请切换使用第一行作为标题选项。如果您选择了多个文件,这适用于每个文件。
如果您要导入的是 CSV 文件,请在文件编码 (CSV) 下拉列表中选择数据集文件的编码。默认为
UTF-8。在分隔符下拉列表中,选择用于分隔数据中每个单元格的分隔符。默认分隔符为
,。您还可以指定自定义分隔符。如果您希望 Canvas 手动解析整个数据集的多行单元格,请选择多行检测。默认情况下,此选项处于未选中状态,Canvas 会通过对数据进行采样来确定是否使用多行支持。但是,Canvas 可能检测不到样本中的任何多行单元格。如果您有多行单元格,我们建议您选择多行检测选项,以强制 Canvas 检查整个数据集是否有多行单元格。
如果您已准备好导入数据,请选择创建数据集。
在数据集导入 Canvas 的过程中,您可以看到数据集页面上列出了您的数据集。在此页面上,您可以查看数据集详细信息。
当数据集的状态显示为Ready时,表示 Canvas 成功导入了您的数据,您可以继续构建模型。
如果您已连接到数据来源,例如 Amazon Redshift 数据库或 SaaS 连接器,则可以返回该连接。对于 Amazon Redshift 和 Snowflake,您可以添加另一个连接,方法是创建另一个数据集,返回导入数据页面,并选择该连接的数据来源图块。从下拉菜单中,您可以打开之前的连接或选择添加连接。
注意
对于 SaaS 平台,每个数据来源只能有一个连接。
导入图像数据
使用图像数据集,您可以构建单标签图像预测自定义模型,用于预测图像的标签。查看前面的导入数据集部分中的限制,以确保您的图像数据集符合图像数据的要求。
注意
您只能通过本地文件上传或 Amazon S3 存储桶导入图像数据集。此外,对于图像数据集,每个标签必须至少有 25 张图像。
使用以下过程将图像数据集导入 Canvas:
-
打开你的 SageMaker 画布应用程序。
-
在左侧导航窗格中,选择数据集。
-
选择导入数据。
-
从下拉菜单中,选择图像。
-
在弹出的对话框中,在数据集名称字段中,输入数据集的名称,然后选择创建。
-
在导入页面上,打开数据来源下拉菜单。
-
选择您的数据来源。要从计算机上传文件,请选择本地上传。要从 Amazon S3 导入文件,请选择 Amazon S3。
-
从您的电脑或 Amazon S3 存储桶中选择要上传的图像或图像文件夹。
-
如果您已准备好导入数据,请选择导入数据。
在数据集导入 Canvas 的过程中,您可以看到数据集页面上列出了您的数据集。在此页面上,您可以查看数据集详细信息。
当数据集的状态显示为Ready时,表示 Canvas 成功导入了您的数据,您可以继续构建模型。
在构建模型时,您可以编辑图像数据集,也可以分配或重新分配标签、添加图像或从数据集中删除图像。有关如何编辑图像数据集的更多信息,请参阅编辑图像数据集。
导入文档数据
费用分析、身份证件分析、文档分析和文档查询 Ready-to-use模型支持文档数据。您无法使用文档数据构建自定义模型。
借助文档数据集,您可以生成支出分析、身份证件分析、文档分析和文档查询 Ready-to-use模型的预测。查看创建数据集一节中的限制表,确保您的文档数据集符合文档数据的要求。
注意
您只能通过本地文件上传或 Amazon S3 存储桶导入文档数据集。
使用以下过程将文档数据集导入 Canvas:
-
打开你的 SageMaker 画布应用程序。
-
在左侧导航窗格中,选择数据集。
-
选择导入数据。
-
从下拉菜单中选择文档。
-
在弹出的对话框中,在数据集名称字段中,输入数据集的名称,然后选择创建。
-
在导入页面上,打开数据来源下拉菜单。
-
选择您的数据来源。要从计算机上传文件,请选择本地上传。要从 Amazon S3 导入文件,请选择 Amazon S3。
-
从您的计算机或 Amazon S3 存储桶中选择要上传的文档文件。
-
如果您已准备好导入数据,请选择导入数据。
在数据集导入 Canvas 的过程中,您可以看到数据集页面上列出了您的数据集。在此页面上,您可以查看数据集详细信息。
当数据集的状态显示为Ready时,表示 Canvas 已成功导入您的数据。
在数据集页面上,您可以选择数据集进行预览,最多可显示数据集的前 100 个文档。
查看数据集详细信息
对于每个数据集,您可以查看数据集中的所有文件、数据集的版本历史记录以及该数据集的任何自动更新配置。在数据集页面中,您还可以启动诸如更新数据集或自定义模型的工作原理之类的操作。
要查看数据集的详细信息,请执行以下操作:
-
打开 SageMaker 画布应用程序。
-
在左侧导航窗格中,选择数据集。
-
从数据集列表中选择您的数据集。
在数据选项卡上,您可以看到数据的预览。如果选择数据集详细信息,则可以查看数据集中的所有文件。选择一个文件以在预览中仅查看该文件中的数据。对于图像数据集,预览仅显示数据集的前 100 张图像。
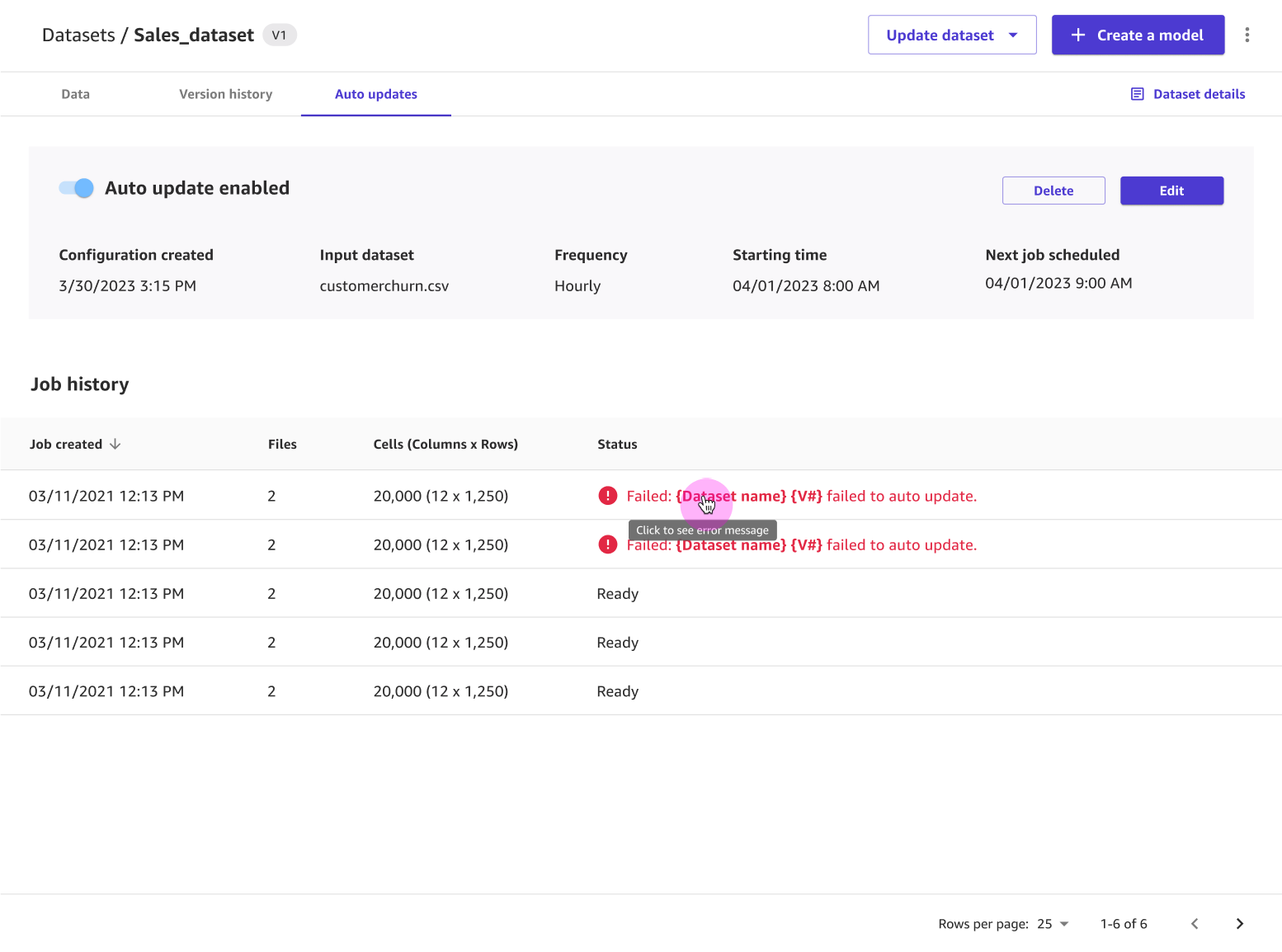
在版本历史记录选项卡上,您可以看到数据集所有版本的列表。每当更新数据集时,都会生成一个新版本。要了解有关更新数据集的更多信息,请参阅更新数据集。以下屏幕截图显示了 Canvas 应用程序中的版本历史记录选项卡。

在自动更新选项卡上,您可以启用数据集自动更新,并设置配置以定期更新数据集。要了解有关设置数据集自动更新的更多信息,请参阅配置数据集自动更新。以下屏幕截图显示了开启自动更新的自动更新选项卡,以及已对数据集执行的自动更新作业的列表。