本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
导出
在 Data Wrangler 流中,可以将所做的部分或全部转换导出到数据处理管道中。
Data Wrangler 流是您对数据执行的一系列数据准备步骤。在数据准备过程中,需要对数据进行一次或多次转换。每次转换都是使用转换步骤完成的。该流包含一系列节点,这些节点代表您的数据导入和您执行的转换。有关节点的示例,请参阅下面的图像。

上图显示了带两个节点的 Data Wrangler 流。来源 – 采样节点显示您从中导入数据的数据来源。数据类型节点指示 Data Wrangler 已执行转换将数据集转换为可用格式。
添加到 Data Wrangler 流的每个转换都显示为一个附加节点。有关可添加的转换的信息,请参阅转换数据。下图显示了 Data Wrangler 流,其中的Rename-column节点用于更改数据集中列的名称。
可以将数据转换导出到以下位置:
-
Amazon S3
-
管道
-
Amazon SageMaker 专题商店
-
Python Code
重要
我们建议您使用 IAM AmazonSageMakerFullAccess 托管策略来授予使用 Data Wrangler 的 AWS 权限。如果您不使用托管式策略,则可以使用 IAM 策略,向 Data Wrangler 授予对 Amazon S3 存储桶的访问权限。有关托管式策略的更多信息,请参阅安全性和权限。
导出数据流时,您需要为所使用的 AWS 资源付费。可以使用成本分配标签来组织和管理这些资源的成本。您负责为用户配置文件创建这些标签,Data Wrangler 会自动将标签应用于用来导出数据流的资源。有关更多信息,请参阅使用成本分配标签。
导出到 Amazon S3
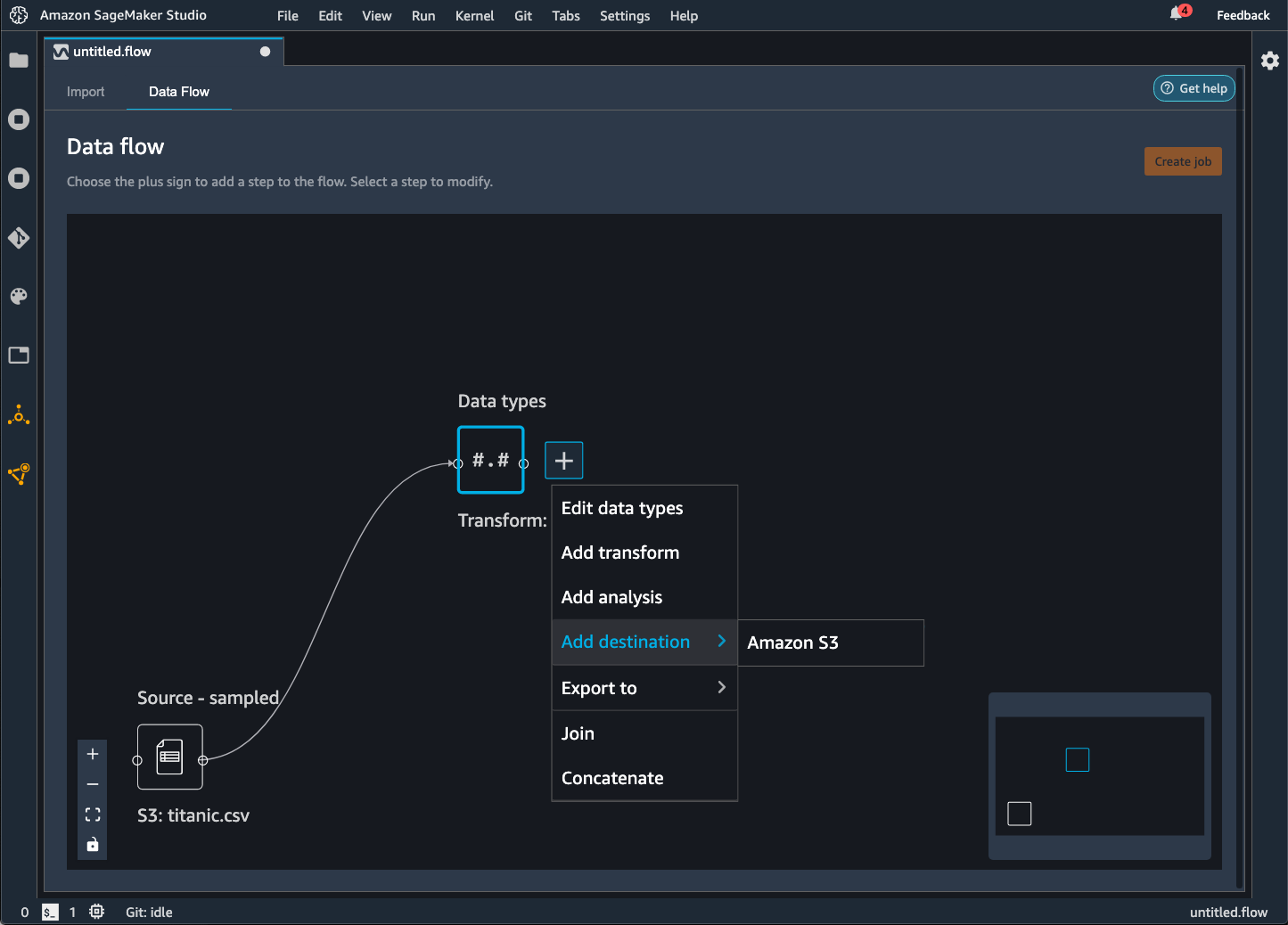
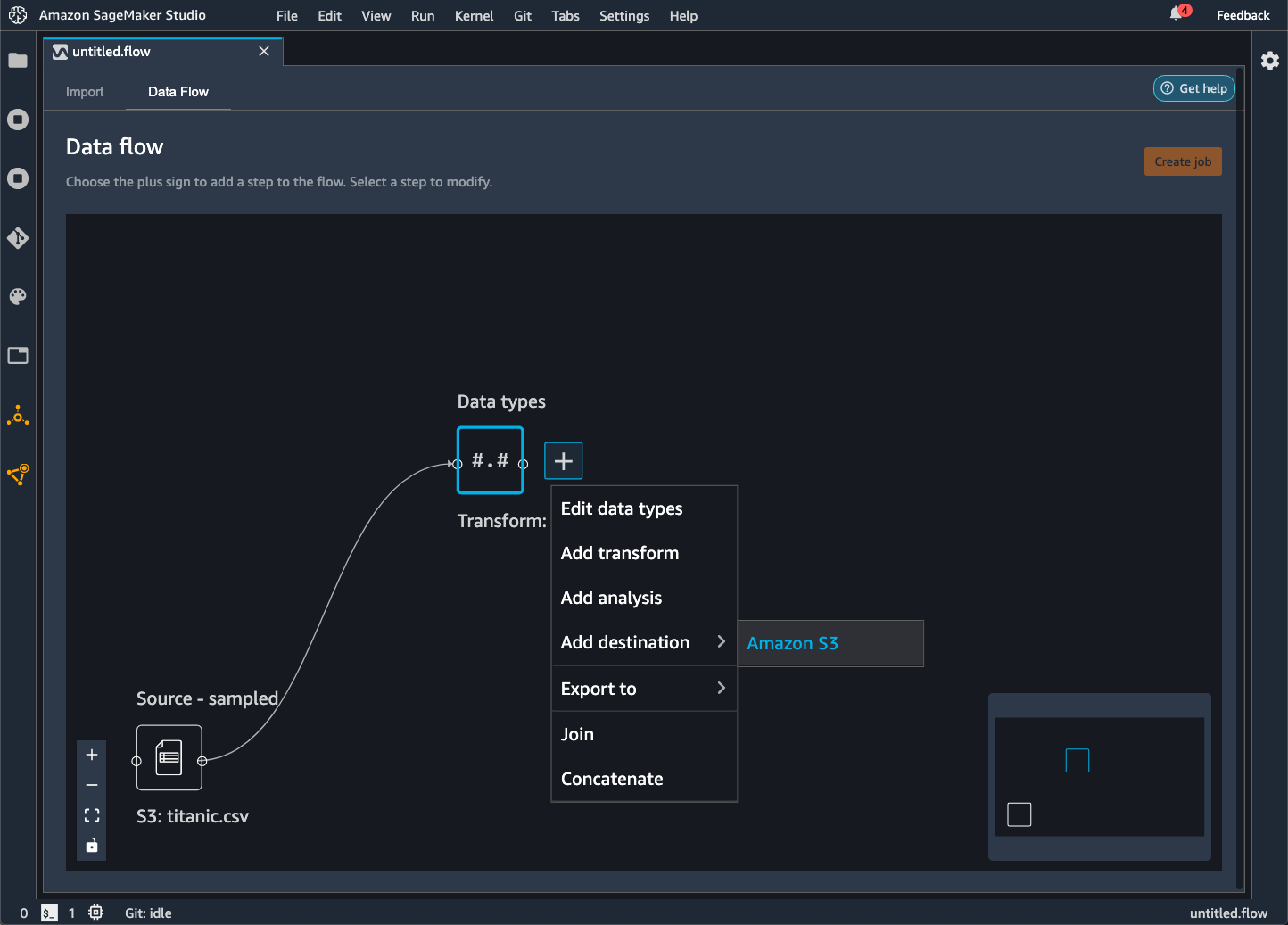
利用 Data Wrangler,您可以将数据导出到 Amazon S3 存储桶中的某个位置。您可以使用以下方法之一指定该位置:
-
目标节点 – Data Wrangler 在处理完数据后存储数据的位置。
-
导出目标 – 将转换后生成的数据导出到 Amazon S3。
-
导出数据 – 对于小数据集,可以快速导出转换的数据。
使用以下部分详细了解这些方法中的每种方法。



当您将数据流导出到 Amazon S3 存储桶时,Data Wrangler 会将流文件的副本存储在 S3 存储桶中。它将流文件存储在 data_wrangler_flows 前缀下。如果您使用默认的 Amazon S3 存储桶来存储流文件,它将使用以下命名约定:sagemaker-。例如,如果您的账号是 111122223333,并且在 us-east-1 中使用 Studio Classic,那么导入的数据集将存储在 region-account
numbersagemaker-us-east-1-111122223333 中。在本示例中,您在 us-east-1 中创建的 .flow 文件存储在 s3://sagemaker- 中。region-account
number/data_wrangler_flows/
导出到管道
当你想要构建和部署大规模机器学习 (ML) 工作流程时,你可以使用 Pipelines 来创建管理和部署 SageMaker AI 作业的工作流程。借助 Pipelines,您可以构建工作流程来管理 SageMaker AI 数据准备、模型训练和模型部署作业。你可以使用 Pipelines 来使用 SageMaker AI 提供的第一方算法。有关管道的更多信息,请参阅SageMaker 管道。
当您将数据流中的一个或多个步骤导出到 Pipelines 时,Data Wrangler 会创建一个可用于定义、实例化、运行和管理管道的 Jupyter Notebook。
使用 Jupyter 笔记本创建管道
使用以下步骤创建 Jupyter Notebook,将您的 Data Wrangler 流导出到 Pipelines。
使用以下步骤生成 Jupyter Notebook 并运行,将您的 Data Wrangler 流导出到 Pipelines。
-
选择要导出的节点旁边的 +。
-
选择导出目标。
-
选择 Pipelines(通过 Jupyter Notebook)。
-
运行 Jupyter 笔记本。

您可以使用 Data Wrangler 生成的 Jupyter 笔记本来定义管道。管道包括由 Data Wrangler 流定义的数据处理步骤。
通过将步骤添加到笔记本的以下代码中的 steps 列表,您可以向管道添加其他步骤:
pipeline = Pipeline( name=pipeline_name, parameters=[instance_type, instance_count], steps=[step_process], #Add more steps to this list to run in your Pipeline )
有关定义管道的更多信息,请参阅定义 SageMaker AI 管道。
导出到推理端点
在 Data Wrangler 流程中创建 SageMaker AI 串行推理管道,在推理时使用 Data Wrangler 流程处理数据。推理管道是一系列步骤,可用于生成对新数据进行预测的经过训练的模型。Data Wrangler 中的串行推理管道可转换原始数据,并将数据提供给机器学习模型进行预测。在 Studio Classic 中,您可以通过 Jupyter Notebook 创建、运行和管理推理管道。有关访问笔记本的更多信息,请参阅使用 Jupyter 笔记本创建推理端点。
在笔记本中,您可以训练机器学习模型,也可以指定已训练的模型。你可以使用 Amazon A SageMaker utopilot 或 XGBoost 使用你在 Data Wrangler 流程中转换的数据来训练模型。
利用管道,您可以执行批量或实时推理。您也可以将 Data Wrangler 流程添加到 “ SageMaker 模型注册表”。有关托管模型的更多信息,请参阅Multi-model 端点。
重要
如果 Data Wrangler 流具有以下转换,则无法将该流导出到推理端点:
-
联接
-
串联
-
分组依据
如果必须使用上述转换来准备您的数据,请使用以下过程。
使用不支持的转换为推理准备数据
-
创建 Data Wrangler 流。
-
应用前面的不受支持的转换。
-
将数据导出到 Amazon S3 存储桶。
-
创建单独的 Data Wrangler 流。
-
导入您在前面的流中导出的数据。
-
应用其余的转换。
-
使用我们提供的 Jupyter 笔记本创建串行推理管道。
有关将数据导出到 Amazon S3 存储桶的信息,请参阅导出到 Amazon S3。有关打开用于创建串行推理管道的 Jupyter 笔记本的信息,请参阅使用 Jupyter 笔记本创建推理端点。
Data Wrangler 会忽略那些在推理时删除数据的转换。例如,如果您使用删除缺失项配置,Data Wrangler 会忽略处理缺失值转换。
如果您重新拟合整个数据集的转换,则转换会延续到您的推理管道。例如,如果使用了中位数来估算缺失值,则重新拟合转换所得的中位数将应用于您的推理请求。在使用 Jupyter 笔记本或将数据导出到推理管道时,可以重新拟合 Data Wrangler 流中的转换。有关重新拟合转换的信息,请参阅重新拟合整个数据集的转换并导出。
串行推理管道支持以下数据类型的输入和输出字符串。每个数据类型都有一组要求。
支持的数据类型
-
text/csv– CSV 字符串的数据类型-
字符串不能具有标头。
-
用于推理管道的特征必须与训练数据集内的特征顺序相同。
-
特征之间必须有一个逗号分隔符。
-
记录必须使用一个换行符分隔。
下面是可在推理请求中提供的有效格式的 CSV 字符串示例。
abc,0.0,"Doe, John",12345\ndef,1.1,"Doe, Jane",67890 -
-
application/json– JSON 字符串的数据类型-
数据集内用于推理管道的特征的顺序必须与训练数据集内的特征顺序相同。
-
数据必须具有特定架构。可以将架构定义为具有一组
features的单个instances对象。每个features对象都表示一个观测值。
下面是可在推理请求中提供的有效格式的 JSON 字符串示例。
{ "instances": [ { "features": ["abc", 0.0, "Doe, John", 12345] }, { "features": ["def", 1.1, "Doe, Jane", 67890] } ] } -
使用 Jupyter 笔记本创建推理端点
按照以下过程操作,导出您的 Data Wrangler 流以创建推理管道。
要使用 Jupyter 笔记本创建推理管道,请执行以下操作。
-
选择要导出的节点旁边的 +。
-
选择导出目标。
-
选择 SageMaker AI 推理管道(通过 Jupyter 笔记本)。
-
运行 Jupyter 笔记本。
当您运行 Jupyter 笔记本时,会创建一个推理流构件。推理流构件是一个 Data Wrangler 流文件,其中包含用于创建串行推理管道的附加元数据。您正导出的节点包含来自前面节点的所有转换。
重要
Data Wrangler 需要推理流构件来运行推理管道。您不能将自己的流文件用作构件。您必须使用前面的步骤创建构件。
导出到 Python Code
要将数据流中的所有步骤导出到可手动集成到任何数据处理工作流的 Python 文件,请使用以下步骤。
使用以下过程生成 Jupyter 笔记本并运行,将您的 Data Wrangler 流导出到 Python Code。
-
选择要导出的节点旁边的 +。
-
选择导出目标。
-
选择 Python 代码。
-
运行 Jupyter 笔记本。
您可能需要配置 Python 脚本才能在管道中运行。例如,如果您运行的是 Spark 环境,请确保在有权访问 AWS 资源的环境中运行脚本。
导出到 Amazon SageMaker 特色商店
您可以使用 Data Wrangler 将您创建的功能导出到亚马逊 SageMaker 功能商店。特征是数据集内的一列。Feature Store 是特征及其相关元数据的集中存储位置。您可以使用 Feature Store 创建、共享和管理用于机器学习 (ML) 开发的精选数据。集中式存储能够让您的数据更易于发现和重复使用。有关功能商店的更多信息,请参阅 Amazon F SageMaker eature Store。
Feature Store 中的一个核心概念是特征组。特征组是特征及其记录(观测值)和关联元数据的集合。它类似于数据库中的表。
可以使用 Data Wrangler 执行下列操作之一:
-
使用新记录更新现有特征组。记录是数据集内的观测值。
-
从您的 Data Wrangler 流中的节点创建新的特征组。Data Wrangler 会将数据集内的观测值作为记录添加到特征组中。
如果要更新现有特征组,则数据集的架构必须与该特征组的架构相匹配。特征组中的所有记录都将替换为数据集内的观测值。
可以通过 Jupyter 笔记本或目标节点,使用数据集内的观测值更新您的特征组。
如果您采用 Iceberg 表格式的功能组具有自定义的离线商店加密密钥,请务必向用于亚马逊 SageMaker Processing 任务的 IAM 授予使用该密钥的权限。必须至少向其授予对正写入 Amazon S3 的数据进行加密的权限。要授予权限,请让 IAM 角色能够使用GenerateDataKey。有关授予 IAM 角色使用 AWS KMS 密钥的权限的更多信息,请参阅 https://docs.aws.amazon.com/kms/latest/developerguide/key-policies.html
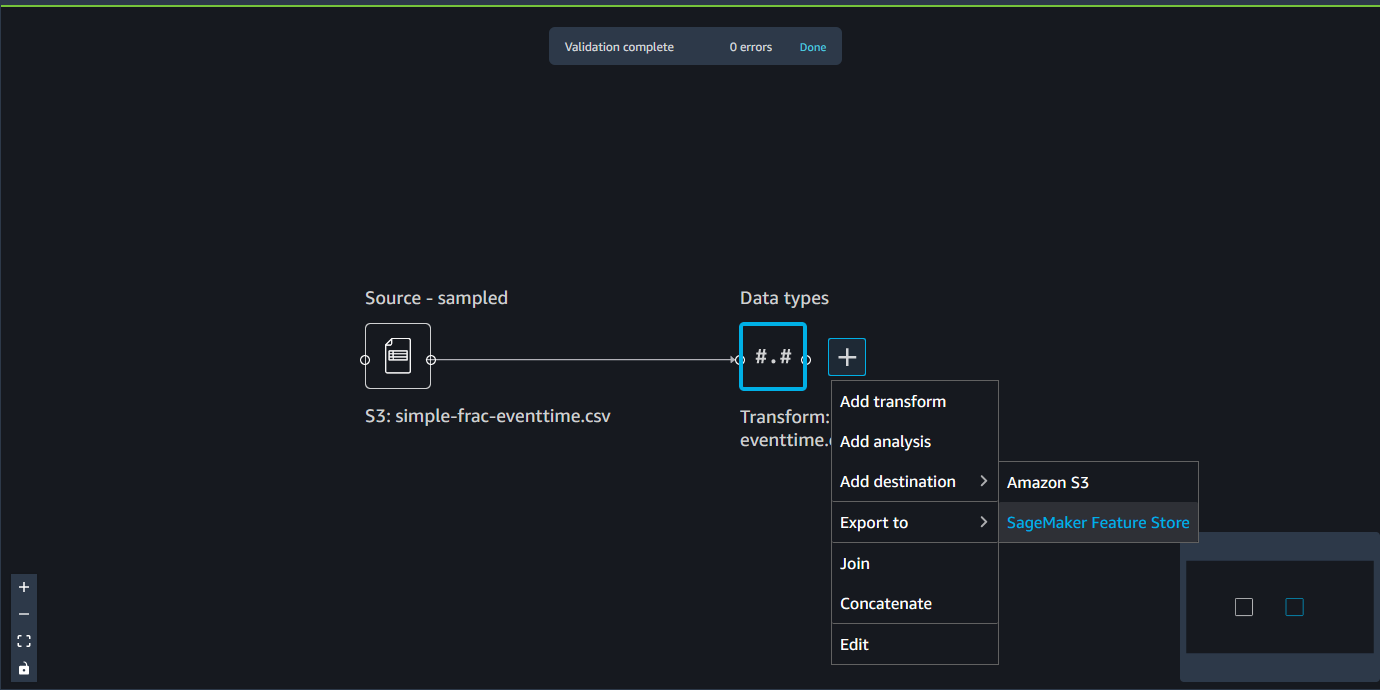
笔记本使用这些配置来创建特征组,大规模处理您的数据,然后将处理后的数据提取到您的在线和离线特征存放区中。要了解更多信息,请参阅数据来源和摄取。
重新拟合整个数据集的转换并导出
导入数据时,Data Wrangler 会使用数据样本来应用编码。默认情况下,Data Wrangler 使用前 50000 行作为样本,不过您可以导入整个数据集或使用不同的采样方法。有关更多信息,请参阅 导入。
以下转换使用您的数据,在数据集内创建列:
如果您已使用采样来导入数据,则前面的转换仅使用样本中的数据来创建列。转换可能没有使用所有相关数据。例如,如果您使用对分类进行编码转换,则整个数据集内可能存在样本中不存在的类别。
您可以使用目标节点或 Jupyter 笔记本重新拟合整个数据集的转换。当 Data Wrangler 在流程中导出转换时,它会创建一个 SageMaker 处理作业。当处理作业完成后,Data Wrangler 会将以下文件保存到默认 Amazon S3 位置或您指定的 S3 位置:
-
Data Wrangler 流文件,用于指定要为数据集重新拟合的转换
-
已应用了重新拟合转换的数据集
您可以在 Data Wrangler 中打开 Data Wrangler 流文件,然后将转换应用于不同的数据集。例如,如果您已将转换应用于训练数据集,则可以打开并使用 Data Wrangler 流文件将转换应用于用于推理的数据集。
有关使用目标节点重新拟合转换和导出的信息,请参阅以下页面:
使用以下步骤运行 Jupyter 笔记本来重新拟合转换并导出数据。
要运行 Jupyter 笔记本并重新拟合转换并导出 Data Wrangler 流,请执行以下操作。
-
选择要导出的节点旁边的 +。
-
选择导出目标。
-
选择要将数据导出到的位置。
-
对于
refit_trained_params对象,将refit设置为True。 -
对于
output_flow字段,指定带有重新拟合转换的输出流文件的名称。 -
运行 Jupyter 笔记本。
创建自动处理新数据的计划
如果您要定期处理数据,则可以创建一个计划来自动运行处理作业。例如,您可以创建一个计划,该计划在获得新数据时自动运行处理作业。有关处理作业的更多信息,请参阅 导出到 Amazon S3 和 导出到 Amazon SageMaker 特色商店。
创建作业时,必须指定有权创建该作业的 IAM 角色。默认情况下,您访问 Data Wrangler 所使用的 IAM 角色是 SageMakerExecutionRole。
以下权限允许 Data Wrangler 访问 EventBridge 和运行处理作业: EventBridge
-
将以下 AWS 托管策略添加到 Amazon SageMaker Studio Classic 执行角色中,该角色为 Data Wrangler 提供使用权限: EventBridge
arn:aws:iam::aws:policy/AmazonEventBridgeFullAccess有关该策略的更多信息,请参阅的AWS 托管策略 EventBridge。
-
将以下策略添加到您在 Data Wrangler 中创建作业时指定的 IAM 角色:
如果您使用的是默认 IAM 角色,则可以将上述策略添加到 Amazon SageMaker Studio Classic 执行角色中。
将以下信任策略添加到角色中 EventBridge 以允许代入该角色。
{ "Effect": "Allow", "Principal": { "Service": "events.amazonaws.com" }, "Action": "sts:AssumeRole" }
重要
当您创建计划时,Data Wrangler 会创建一个输入。eventRule EventBridge您需要为创建的事件规则以及用于运行处理作业的实例都支付费用。
有关 EventBridge 定价的信息,请参阅 Amazon EventBridge 定价
使用以下方法之一设置计划:
以下各个部分提供了作业创建过程。
您可以使用 Amazon SageMaker Studio Classic 查看计划运行的作业。处理作业在 Pipelines 中运行。每个处理作业都有各自的管道。作业作为管道中的一个处理步骤运行。您可以查看已在管道中创建的计划。有关查看管道的信息,请参阅 查看管道详情。
通过以下过程查看您已计划的作业。
要查看您已计划的作业,请执行以下操作。
-
打开 Amazon SageMaker Studio 经典版。
-
打开 Pipelines
-
查看用于您已创建的作业的管道。
运行作业的管道使用作业名称作为前缀。例如,如果您创建了一个名为
housing-data-feature-enginnering的作业,则管道的名称为data-wrangler-housing-data-feature-engineering。 -
选择包含您的作业的管道。
-
查看管道的状态。管道状态为成功时表示已成功运行处理作业。
要停止运行处理作业,请执行以下操作:
要停止运行处理作业,请删除指定计划的事件规则。删除事件规则时,会使与该计划关联的所有作业停止运行。有关删除规则的信息,请参阅禁用或删除 Amazon EventBridge 规则。
您还可以停止和删除与计划关联的管道。有关停止管道的信息,请参见StopPipelineExecution。有关删除管道的信息,请参阅DeletePipeline。
