本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Multi-model 端点
Multi-model 端点为部署大量模型提供了一种可扩展且经济实惠的解决方案。它们使用相同的资源实例集和共享的服务容器来托管您的所有模型。与使用单模型端点相比,这可以提高端点利用率,从而降低托管成本。它还可以减少部署开销,因为 Amazon SageMaker AI 可以管理在内存中加载模型,并根据终端节点的流量模式对其进行扩展。
下图显示多模型端点与单模型端点相比的工作原理。
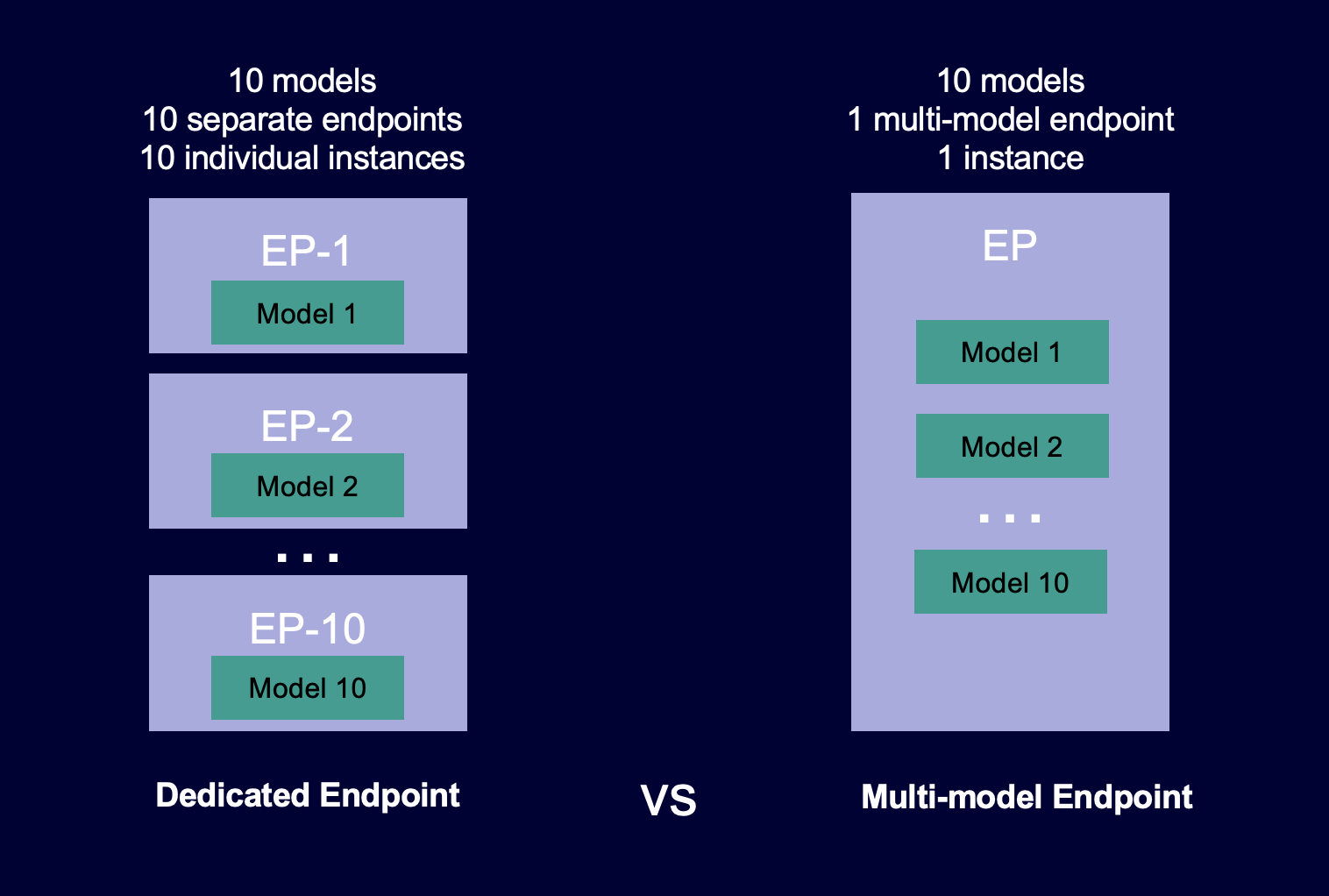
Multi-model 端点非常适合在共享服务容器上托管大量使用相同机器学习框架的模型。如果您的模型中包括经常访问和不经常访问的模型,则多模型端点可以在使用更少资源并节约更高成本的同时高效地为对应流量提供服务。您的应用程序应容忍在调用不常使用的模型时偶尔出现的、与冷启动相关的延迟损失。
Multi-model 端点支持托管 CPU 和 GPU 支持的模型。通过使用 GPU 支持的模型,您可以通过提高端点及其底层加速型计算实例的使用率来降低模型部署成本。
Multi-model 端点还支持在模型之间分时共享内存资源。当模型的大小和调用延迟非常相似时,这种方法效果最佳。在这种情况下,多模型端点可以有效地在所有模型中使用实例。如果模型具有明显较高的每秒事务数 (TPS) 或延迟要求,我们建议在专用端点上托管这些模型。
您可以使用具有以下特征的多模型端点:
-
AWS PrivateLink和 VPC
-
串行推理管线(但推理管线中只能包含一个启用多模型的容器)
-
A/B 测试
您可以使用 AWS SDK for Python (Boto) 或 SageMaker AI 控制台创建多模型终端节点。对于 CPU 支持的多模型端点,可以通过集成多模型服务器
主题
多模型端点的工作原理
SageMaker AI 管理容器内存中多模型端点上托管的模型的生命周期。当您创建终端节点时,A SageMaker I 不会将所有模型从 Amazon S3 存储桶下载到容器,而是在您调用它们时动态加载和缓存它们。当 SageMaker AI 收到特定模型的调用请求时,它会执行以下操作:
-
将请求路由到端点后面的实例。
-
将模型从 S3 存储桶下载到该实例的存储卷中。
-
将模型加载到该加速计算实例上的容器内存(CPU 或 GPU,具体取决于您拥有 CPU 还是 GPU 支持的实例)。如果模型已加载到容器的内存中,则调用速度会更快,因为 SageMaker AI 不需要下载和加载它。
SageMaker AI 继续将模型请求路由到已加载模型的实例。但是,如果模型收到许多调用请求,并且多模型终端节点还有其他实例, SageMaker AI 会将一些请求路由到另一个实例以容纳流量。如果尚未在第二个实例上加载模型,则模型将下载到该实例的存储卷中,并加载到容器的内存中。
当一个实例的内存利用率很高且 SageMaker AI 需要将另一个模型加载到内存中时,它会从该实例的容器中卸载未使用的模型,以确保有足够的内存来加载模型。卸载的模型将保留在实例的存储卷上,并且稍后可加载到容器的内存中,而无需再次从 S3 存储桶进行下载。如果实例的存储卷达到其容量, SageMaker AI 会从存储卷中删除所有未使用的模型。
要删除模型,请停止发送请求并将其从 S3 存储桶中删除。 SageMaker AI 在服务容器中提供多模型端点功能。在多模型端点中添加和删除模型不需要更新端点本身。要添加一个模型,请将该模型上传到 S3 存储桶并调用它。无需更改代码即可使用它。
注意
更新多模型端点时,由于多模型端点中的智能路由会适应您的流量模式,因此端点上的初始调用请求可能会遇到更高的延迟。但在它了解您的流量模式后,您就会体验到最常用模型的延迟较低。由于模型是动态加载到实例的,因此不常使用的模型可能会发生一定的冷启动延迟。
用于多模型端点的示例笔记本
要了解有关如何使用多模型端点的更多信息,您可以参阅以下示例笔记本:
-
使用 CPU 支持的实例的多模型端点示例:
-
Multi-Model Endpoint xgBoost 示例笔记本 — 本笔记本展示了如何将多个 XGBoost 模型部署到端点
。 -
Multi-Model 端点 BYOC 示例笔记
本 — 本笔记本展示了如何设置和部署支持 AI 中 SageMaker 多模型端点的客户容器。
-
-
使用 GPU 支持的实例的多模型端点示例:
-
使用 Amazon A SageMaker I Multi-model 终端节点 (MME) 在 GPU 上运行多个深度学习模型
— 本笔记本展示了如何使用 NVIDIA Triton Inference 容器将 ResNet-50 模型部署到多模型终端节点。
-
有关如何创建和访问可用于在 SageMaker AI 中运行前面示例的 Jupyter 笔记本实例的说明,请参阅。Amazon SageMaker 笔记本实例创建并打开笔记本实例后,选择 “SageMaker AI 示例” 选项卡以查看所有 SageMaker AI 示例的列表。多模型端点笔记本位于高级功能部分。要打开笔记本,请选择其使用选项卡,然后选择创建副本。
有关多模型端点使用案例的更多信息,请参阅以下博客和资源:
