本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
简介
几十年来,SAP 客户通过两种常见模式在内部保护 SAP 工作负载:高可用性和灾难恢复。云计算的出现为使用现代架构和技术重新思考 SAP 的 HADR 功能提供了机会。
让我们回顾一下作为 SAP n 层架构一部分的 SAP 系统设计和单点故障。
SAP NetWeaver 架构单点故障
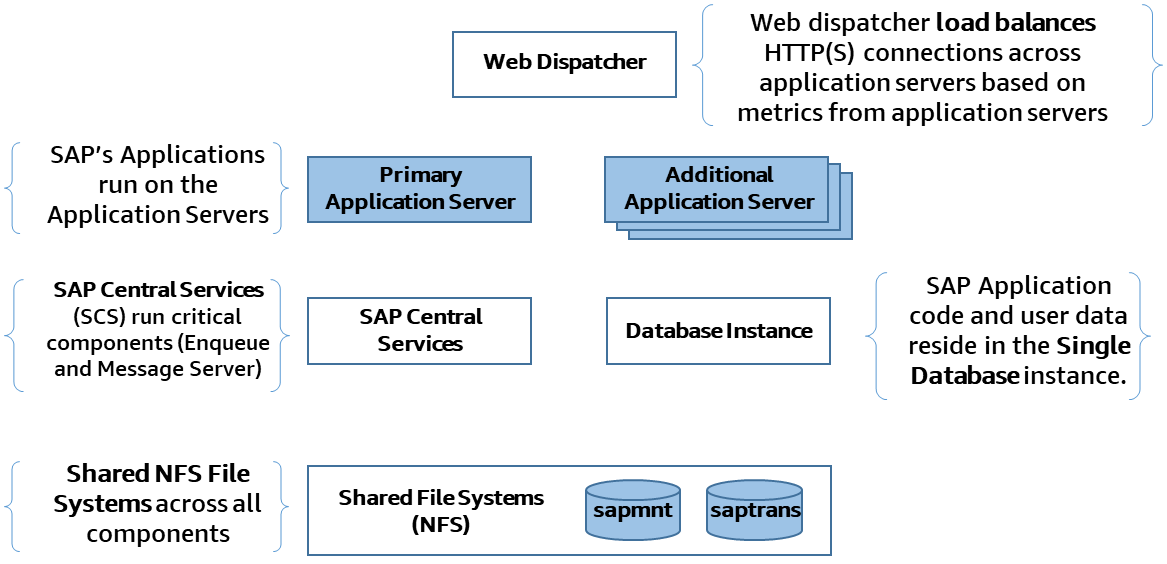
图 1:SAP 单点故障
图 1 显示了典型的 SAP NetWeaver 架构,它有几个单点故障,如下所示:
-
SAP 中央服务(消息服务器和入队进程)
-
SAP 应用程序服务器
-
NFS(共享存储)
-
数据库
-
SAP 网络调度器
对于 SAP 中央服务和数据库,可以通过部署更多主机来增加保护。例如,另一台运行 SAP 复制入队的主机可以防止应用程序级锁定(入队锁)丢失,而另一台运行辅助数据库实例的主机可以防止数据丢失。
但是,这些单点故障的固有设计限制了轻松利用云原生功能来提供高可用性和可靠性的能力。
Amazon 弹性文件服务 (Amazon EFS) 是一项高度可用且持久的托管 NFS 服务,可在多个物理位置(AWS可用区)主动运行。此服务可以帮助保护 SAP 的其中一个单点故障。
高可用性和灾难恢复
高可用性 (HA) 是系统的属性,它可以在定义的时间段内以可接受或商定的水平提供服务,并掩盖最终用户的计划外中断。这通常是通过使用群集服务器来实现的。这些服务器提供自动故障检测、恢复或高弹性硬件、强大的测试以及问题和变更管理。
灾难恢复 (DR) 通过在不同的硬件和/或物理位置进行可靠且可预测的恢复,防止计划外重大中断(例如站点灾难)。由于损坏或恶意软件导致的数据丢失被视为逻辑灾难事件。它通常在单独的解决方案中解决,例如从最新的备份或存储快照中恢复。逻辑灾难恢复并不一定意味着故障转移到另一个设施。
从记录在案和可测量的数据点的角度来看,HADR 要求通常按以下方式定义:
-
正常运行时间百分比是给定时段(每月或每年)内正常运行时间的百分比。
-
平均恢复时间 (MTTR) 是从故障中恢复所需的平均时间。
-
恢复服务 (RTS) 是指为用户恢复系统服务所花费的时间。
-
恢复时间目标 (RTO) 是系统或服务可能停机的最长时间、解决方案恢复所需的时间以及服务重新可用所需的时间。
-
恢复点目标 (RPO) 是指企业愿意丢失多少数据,用时间表示。这是从故障到恢复点之间的最长时间。
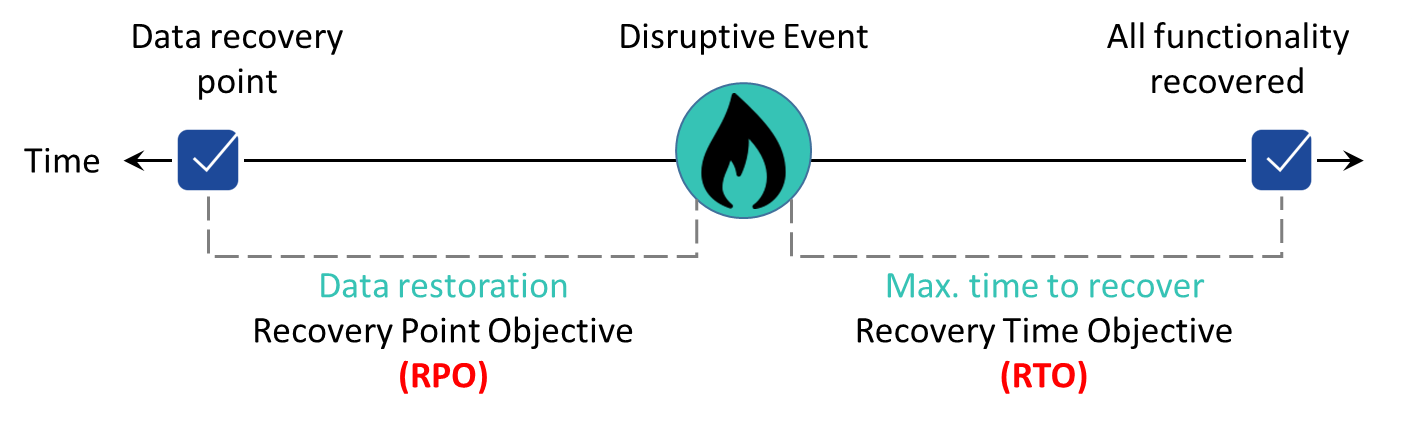
图 2:从中断事件中恢复
本地部署模式与云部署模式
传统上,具有高可用性要求的客户会将其主要计算能力部署在单个数据中心或托管设施中,通常是在两个独立的房间或数据中心大厅中,这些房间或数据中心大厅具有不同的冷却和电源以及高速网络连接。有些客户会近距离运行两个托管设施,计算能力是分开的,但又足够近,不会受到网络延迟的影响。
为了满足灾难恢复需求(前面的情景意味着不可预见的位置故障风险更高),许多客户会扩展其架构,将数据副本所在的辅助位置包括在内,并增加空闲计算容量。主位置和辅助位置之间的距离常常导致需要异步传输数据,这会影响恢复点目标。对于许多运行 SAP 的行业和公司来说,这是用于高可用性和灾难恢复的标准且普遍接受的架构模式。

图 3:本地灾难恢复
在图 3 中,我们举例说明了客户经常在内部使用的方法。在 L ocation 1 中,客户有两个托管设施,通常将房间或大厅分隔在同一个数据中心中,他们在那里为 SAP 单点故障部署高可用性架构。地点 2 是灾难恢复地点,在地点 1 的两个托管设施都出现严重故障时,SAP 系统将在其中恢复。
将 SAP 工作负载迁移到云提供商的客户仍会恢复到该架构,并将其映射到AWS区域和可用区 (AZ),如图 4 所示。虽然这种架构可以在您的环境中运行,但它不遵循Well-Architecte AWSd Framework,该框架可帮助云架构

图 4:本地到AWS区域映射方法
AWS按地理位置隔离区域和可用区中的设施。多可用区方法提供距离,同时保持主计算容量的性能。这种方法(图 5)大大降低了定位故障的风险。

图 5:本地与AWS区域映射的替代方法
由于主计算容量的位置故障风险显著降低,因此可以根据业务需求评估第二个区域的需求。您可以使用在相同或不同的区域快速部署所需的容量AWS。闲置硬件不再是问题。利用跨区域复制,数据备份可以存储在亚马逊简单存储服务 (Amazon S3) 的AWS单个区域或AWS多个区域中。这种架构可以简化并随时可用(图 6)。
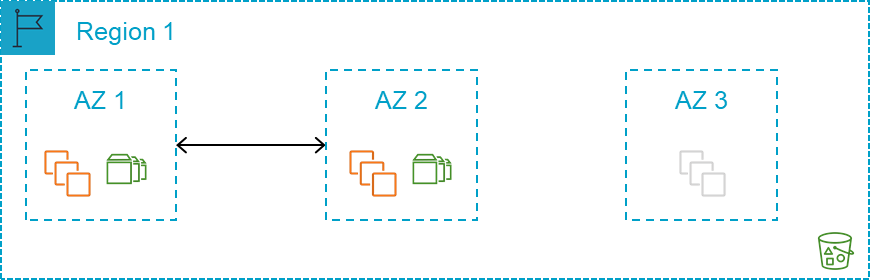
图 6:单AWS区域方法
除了考虑基础设施或托管设施故障的影响外,还需要考虑的另一种情况是由于意外或恶意的技术活动而导致业务数据丢失。
意外或恶意技术活动导致的业务数据丢失称为逻辑灾难恢复。它需要决定从一个好的本地副本恢复业务数据。为此,需要就数据的存储位置以及逻辑灾难恢复时如何使用数据做出决定。
在本指南中,我们将详细介绍关键架构指南、架构模式以及为满足可用性和可靠性要求而需要考虑的决策。
