本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
可用性是我们定量衡量韧性的主要方法之一。我们将可用性 A 定义为工作负载可供使用的时间百分比。这是其预期“正常运行时间”(可用时间)与衡量的总时间(预期“正常运行时间”加上预期“停机时间”)的比率。
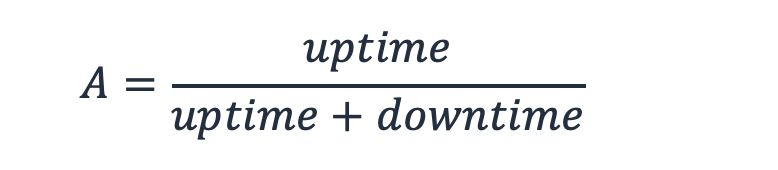
公式 1 - 可用性
为了更好地理解这个公式,我们来分析一下如何衡量正常运行时间和停机时间。首先,我们需要知道工作负载能持续多长时间不出现故障。我们称之为平均故障间隔时间 (MTBF),即工作负载开始正常运行与下一次故障之间的平均时间。然后,我们需要知道发生故障后需要多长时间才能恢复。
我们称之为平均修复(或恢复)时间 (MTTR),即在发生故障的子系统被修复或恢复服务时,工作负载不可用的时长。MTTR 中的一个重要时间段是平均检测时间 (MTTD),即从故障发生到修复操作开始之间的时间长度。下图显示了所有这些指标之间的关联。
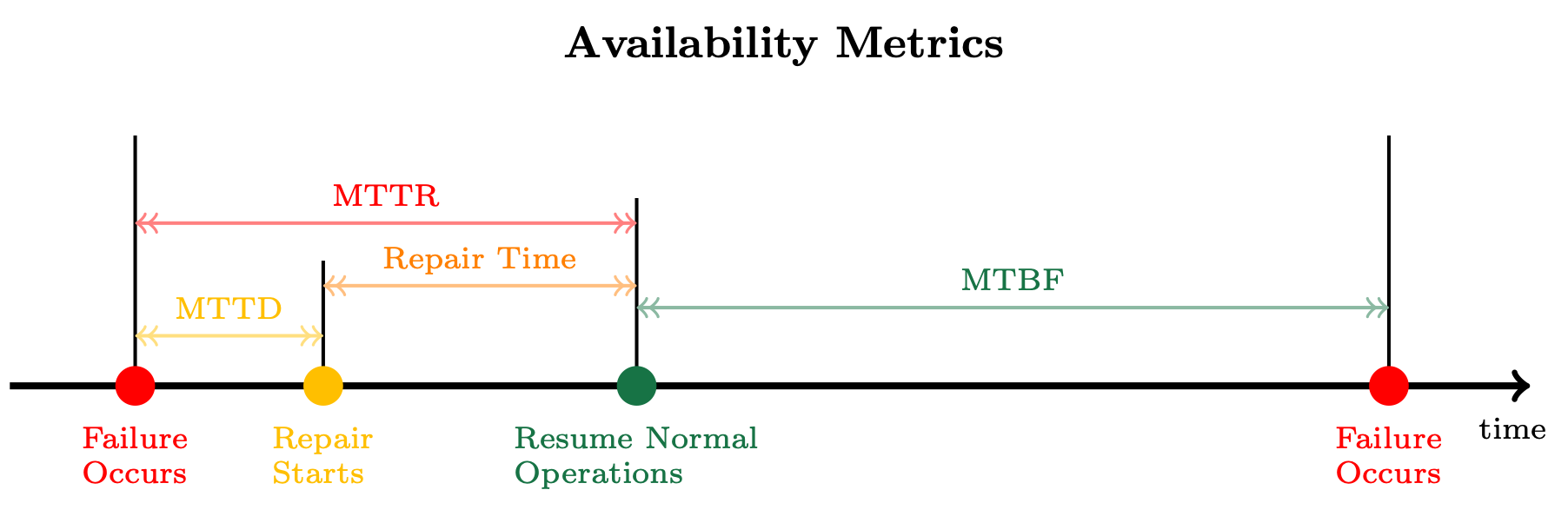
MTTD、MTTR 和 MTBF 之间的关系
因此,我们可以使用 MTBF(工作负载运行的时间)和 MTTR (工作负载关闭的时间)来表示可用性 A。
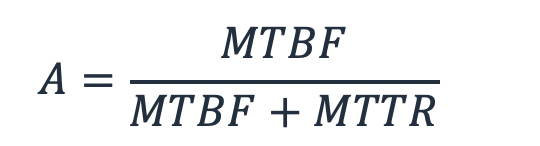
公式 2 - MTBF 和 MTTR之间的关系
而工作负载“停机”(即不可用)的概率就是发生故障的概率 F。
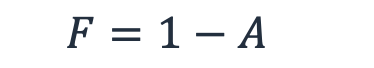
公式 3 - 故障概率
可靠性是指工作负载收到请求后在指定响应时间内执行正确操作的能力。这是可用性衡量的对象。降低工作负载故障频率(提高 MTBF)或缩短修复时间(缩短 MTTR)都可以提高可用性。
规则 1
降低故障频率(提高 MTBF)、缩短故障检测时间(缩短 MTTD)和缩短修复时间(缩短 MTTR)是提高分布式系统可用性的三项因素。
