本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
仪器化 AWS Lambda 函数
注意
X-Ray SDK/Daemon 维护通知 — 2026 年 2 月 25 日 AWS X-Ray SDKs/Daemon 将进入维护模式, AWS 将限制 X-Ray SDK 和 Daemon 版本仅用于解决安全问题。有关支持时间表的更多信息,请参阅 X-Ray SDK 和 Daemon Support 时间表。我们建议迁移到 OpenTelemetry。有关迁移到仪器的更多信息 OpenTelemetry,请参阅从 X-Ray 仪器迁移到 OpenTelemetry 仪器。
Scorekeep 使用两个 AWS Lambda 函数。第一个是lambda分支中的一个 Node.js 函数,它为新用户生成随机名称。如果用户在创建会话时未输入名称,则该应用程序将通过 适用于 Java 的 AWS SDK调用名为 random-name 的函数。 X-Ray 适用于 Java 的 SDK 在子分段中记录有关 Lambda 调用的信息,就像使用仪器 AWS 化的 SDK 客户端进行的任何其他调用一样。
注意
运行 random-name Lambda 函数需要在 Elastic Beanstalk 环境外创建其他资源。有关详细信息和说明,请参阅自述文件:AWS
Lambda 集成
第二个函数为 scorekeep-worker,它是一个独立于 Scorekeep API 运行的 Python 函数。当游戏结束时,API 将会话 ID 和游戏 ID 写入 SQS 队列。工作线程函数将从队列中读取项目,然后调用 Scorekeep API 来为 Amazon S3 中的存储构建每个游戏会话的完整记录。
Scorekeep 包括用于创建这两个函数的 CloudFormation 模板和脚本。由于您需要将 X-Ray SDK 与函数代码捆绑在一起,因此模板无需任何代码即可创建函数。在部署 Scorekeep 时,.ebextensions 文件夹中包含的配置文件将创建一个包含 SDK 的源包并使用 AWS Command Line Interface更新函数代码和配置。
随机名称
当用户在没有登录或指定用户名的情况下启动游戏会话时,Scorekeep 将调用随机名称函数。当 Lambda 处理对的调用时random-name,它会读取跟踪标头,其中包含由 Java X-Ray SDK 编写的跟踪 ID 和采样决策。
对于每个采样请求,Lambda 都会运行守护程序并 X-Ray 写入两个分段。第一个分段记录有关调用函数的 Lambda 调用的信息。但从 Lambda 的角度看,该分段包含与 Scorekeep 记录的子分段相同的信息。第二个分段表示函数所做的工作。
Lambda 通过函数上下文将函数段传递给 X-Ray 软件开发工具包。在检测 Lambda 函数时,您不使用 SDK 为传入请求创建分段。Lambda 将提供分段,并且您将使用 SDK 检测客户端和写入子分段。
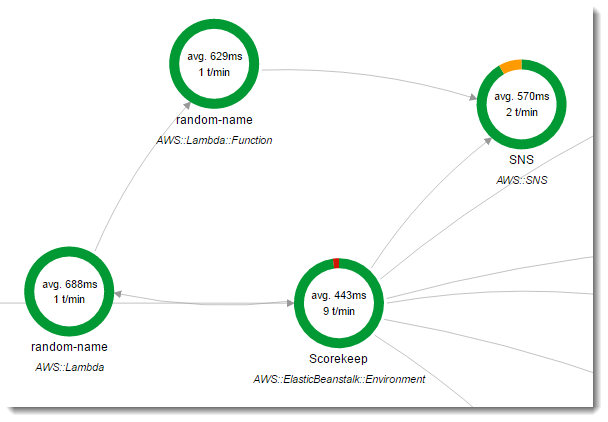
该random-name函数是在中实现的 Node.js。它使用的 SDK 通过 JavaScript Amazon SNS 发送通知,使用的 S X-Ray DK Node.js 来检测 SD AWS K 客户端。 Node.js 为了写入注释,该函数利用 AWSXRay.captureFunc 创建一个自定义子分段,并在经过检测的函数中写入注释。在 Lambda 中,您无法直接将注释写入函数分段,而只能将其写入您创建的子分段。
例 function/index.js
var AWSXRay = require('aws-xray-sdk-core');
var AWS = AWSXRay.captureAWS(require('aws-sdk'));
AWS.config.update({region: process.env.AWS_REGION});
var Chance = require('chance');
var myFunction = function(event, context, callback) {
var sns = new AWS.SNS();
var chance = new Chance();
var userid = event.userid;
var name = chance.first();
AWSXRay.captureFunc('annotations', function(subsegment){
subsegment.addAnnotation('Name', name);
subsegment.addAnnotation('UserID', event.userid);
});
// Notify
var params = {
Message: 'Created randon name "' + name + '"" for user "' + userid + '".',
Subject: 'New user: ' + name,
TopicArn: process.env.TOPIC_ARN
};
sns.publish(params, function(err, data) {
if (err) {
console.log(err, err.stack);
callback(err);
}
else {
console.log(data);
callback(null, {"name": name});
}
});
};
exports.handler = myFunction;在您将示例应用程序部署到 Elastic Beanstalk 时,将自动创建此函数。xray 分支包括一个用于创建空白 Lambda 函数的脚本。.ebextensions文件夹中的配置文件在部署npm install期间使用构建函数包,然后使用 CLI AWS 更新 Lambda 函数。
工作线程
经过检测的工作线程函数在自己的分支 xray-worker 中提供,这是因为,除非您先创建工作线程函数和相关资源,否则该函数无法运行。有关说明,请参阅分支自述文件
该函数由每 5 分钟一次捆绑的 Amazon Events CloudWatch 事件触发。当该函数运行时,它会从 Scorekeep 管理的 Amazon SQS 队列中拉取项目。每条消息均包含有关已完成游戏的信息。
工作线程将从游戏记录引用的其他表中拉取游戏记录和文档。例如,DynamoDB 中的游戏记录包含在游戏期间执行的移动的列表。该列表不包含移动本身,而是包含存储在单独的表中的移动 ID。
会话和状态也将存储为引用。虽然这可阻止游戏表中的条目过大,但需要额外调用来获取有关游戏的所有信息。工作线程会取消引用所有这些条目,并将游戏的完整记录构建为 Amazon S3 中的单一文档。当您要对数据进行分析时,您可以利用 Amazon Athena 直接在 Amazon S3 中对数据运行查询,而无需运行读取密集型数据迁移来拉取 DynamoDB 中的数据。
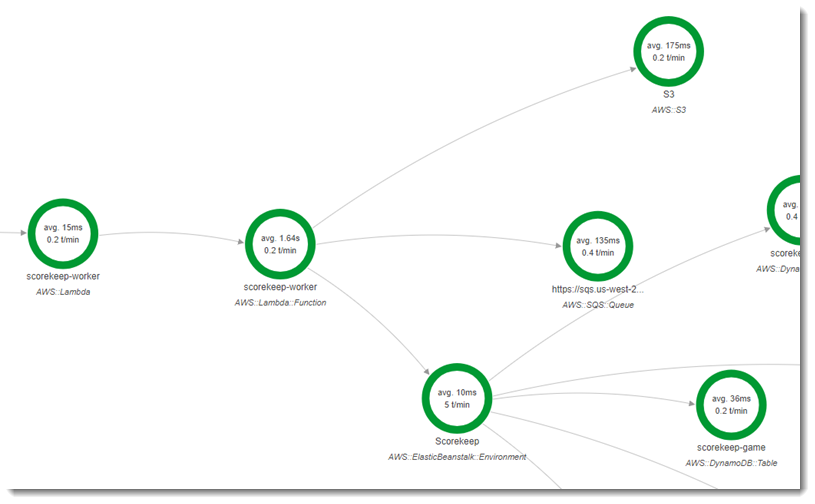
工作线程函数已在自身在 AWS Lambda的配置中启用活动跟踪。与随机命名函数不同,worker 不会收到来自已检测应用程序的请求,因此 AWS Lambda 不会收到跟踪标头。利用活动跟踪,Lambda 将创建跟踪 ID 并制定采样决策。
适用于 Python 的 X-Ray 软件开发工具包只是函数顶部的几行,用于导入软件开发工具包并运行其patch_all函数来修补它用来调用 Amazon SQS AWS SDK for Python (Boto) 和 Amazon S3 的 httClients 和 HttClients。当工作线程调用 Scorekeep API 时,SDK 会将跟踪标头添加到通过 API 跟踪调用的请求中。
例_lambda/scorekeep-worker/scorekeep-worker.py
import os
import boto3
import json
import requests
import time
from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.core import patch_all
patch_all()
queue_url = os.environ['WORKER_QUEUE']
def lambda_handler(event, context):
# Create SQS client
sqs = boto3.client('sqs')
s3client = boto3.client('s3')
# Receive message from SQS queue
response = sqs.receive_message(
QueueUrl=queue_url,
AttributeNames=[
'SentTimestamp'
],
MaxNumberOfMessages=1,
MessageAttributeNames=[
'All'
],
VisibilityTimeout=0,
WaitTimeSeconds=0
)
...