本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
將 Amazon Aurora Machine Learning 與 Aurora PostgreSQL 搭配使用
透過將 Amazon Aurora 機器學習與 Aurora PostgreSQL 資料庫叢集搭配使用,您可以根據需求使用 Amazon Comprehend 或 Amazon SageMaker AI 或 Amazon Bedrock。這些服務各支援特定的機器學習使用案例。
某些 AWS 區域 和特定版本的 Aurora PostgreSQL 僅支援 Aurora Machine Learning。在嘗試設定 Aurora Machine Learning 之前,請先檢查 Aurora PostgreSQL 版本和區域的可用性。如需詳細資訊,請參閱將機器學習與 Aurora PostgreSQL 搭配使用。
主題
將 Aurora Machine Learning 與 Aurora PostgreSQL 搭配使用的建議
AWS 機器學習服務是在自己的生產環境中設定和執行的受管服務。Aurora 機器學習支援與 Amazon Comprehend、SageMaker AI 和 Amazon Bedrock 的整合。在嘗試設定 Aurora PostgreSQL 資料庫叢集以使用 Aurora Machine Learning 之前,請務必了解下列要求和先決條件。
Amazon Comprehend、SageMaker AI 和 Amazon Bedrock 服務必須在與 Aurora PostgreSQL 資料庫叢集 AWS 區域 相同的 中執行。您無法從不同區域的 Aurora PostgreSQL 資料庫叢集使用 Amazon Comprehend 或 SageMaker AI 或 Amazon Bedrock 服務。
如果 Aurora PostgreSQL 資料庫叢集位於以 Amazon VPC 服務為基礎的虛擬公有雲端 (VPC) (而非 Amazon Comprehend 和 SageMaker AI 服務),則 VPC 的安全群組需要允許目標 Aurora 機器學習服務的輸出連線。如需詳細資訊,請參閱啟用從 Amazon Aurora 到其他服務的網路通訊 AWS。
對於 SageMaker AI,您要用於推論的機器學習元件必須已設定並準備好使用。在設定 Aurora PostgreSQL 資料庫叢集的過程中,您必須具有 SageMaker AI 端點的 Amazon Resource Name (ARN) 可供使用。您團隊中的資料科學家可能最能夠處理如何使用 SageMaker,以準備模型並處理其他這類任務。若要開始使用 Amazon SageMaker AI,請參閱開始使用 Amazon SageMaker AI。如需推論和端點的詳細資訊,請參閱即時推論。
-
對於 Amazon Bedrock,您需要擁有 Bedrock 模型的模型 ID,您想要將此模型用於 Aurora PostgreSQL 資料庫叢集組態程序期間的可用推論。團隊中的資料科學家可能最適合使用 Bedrock 來決定要使用的模型,並視需要微調模型,以及處理其他此類任務。若要開始使用 Amazon Bedrock,請參閱如何設定 Bedrock。
-
Amazon Bedrock 使用者必須先要求模型存取權,才能使用模型。如果您想要新增用於文字、聊天和影像產生的其他模型,則需要請求存取 Amazon Bedrock 中的模型。如需詳細資訊,請參閱模型存取。
Aurora Machine Learning 搭配 Aurora PostgreSQL 支援的功能和限制
Aurora 機器學習支援任何可透過 ContentType 的 text/csv 值讀取和寫入逗號分隔值 (CSV) 格式的 SageMaker AI 端點。目前接受此格式的內建 SageMaker AI 演算法如下。
Linear Learner
Random Cut Forest
XGBoost
若要進一步了解這些演算法,請參閱《Amazon SageMaker AI 開發人員指南》中的選擇演算法。
將 Amazon Bedrock 與 Aurora 機器學習搭配使用時,適用下列限制:
-
使用者定義的函數 (UDF) 提供與 Amazon Bedrock 互動的原生方式。UDF 沒有特定的請求或回應需求,因此可以使用任何模型。
-
您可以使用 UDF 來建置任何所需的工作流程。例如,您可以結合類似
pg_cron的基本概念,來執行查詢、擷取資料、產生推論,以及寫入至資料表以直接提供查詢。 -
UDF 不支援批次或平行呼叫。
-
Aurora 機器學習延伸模組不支援向量界面。作為延伸模組的一部分,函數可用於輸出模型回應的嵌入 (格式為
float8[]),以將這些嵌入存放在 Aurora 中。如需float8[]使用的詳細資訊,請參閱搭配 Aurora PostgreSQL 資料庫叢集使用 Amazon Bedrock。
設定 Aurora PostgreSQL 資料庫叢集來使用 Aurora Machine Learning
若要讓 Aurora Machine Learning 與您的 Aurora PostgreSQL 資料庫叢集搭配使用,您需要為要使用的每個服務建立 AWS Identity and Access Management (IAM) 角色。IAM 角色可讓您的 Aurora PostgreSQL 資料庫叢集代表叢集使用 Aurora Machine Learning 服務。您也需要安裝 Aurora Machine Learning 延伸模組。在下列主題中,您可以找到其中每個 Aurora Machine Learning 服務的設定程序。
主題
設定 Aurora PostgreSQL 來使用 Amazon Bedrock
在以下程序中,您首先建立 IAM 角色和政策,授與 Aurora PostgreSQL 許可來代表叢集使用 Amazon Bedrock。然後,您將此政策連接至 IAM 角色,Aurora PostgreSQL 資料庫叢集會使用此角色來使用 Amazon Bedrock。為了簡單起見,此程序使用 AWS Management Console 來完成所有任務。
設定 Aurora PostgreSQL 資料庫叢集來使用 Amazon Bedrock
登入 AWS Management Console ,並在 https://https://console.aws.amazon.com/iam/
開啟 IAM 主控台。 前往 https://console.aws.amazon.com/iam/
開啟 IAM 主控台。 在 (IAM) 主控台功能表中選擇政策 AWS Identity and Access Management (在存取管理下)。
選擇建立政策。在視覺化編輯器頁面中,選擇服務,然後在選取服務欄位中輸入 Bedrock。展開讀取存取層級。從 Amazon Bedrock 讀取設定中選擇 InvokeModel。
選擇您想要透過政策授予讀取存取權的基礎/佈建模型。
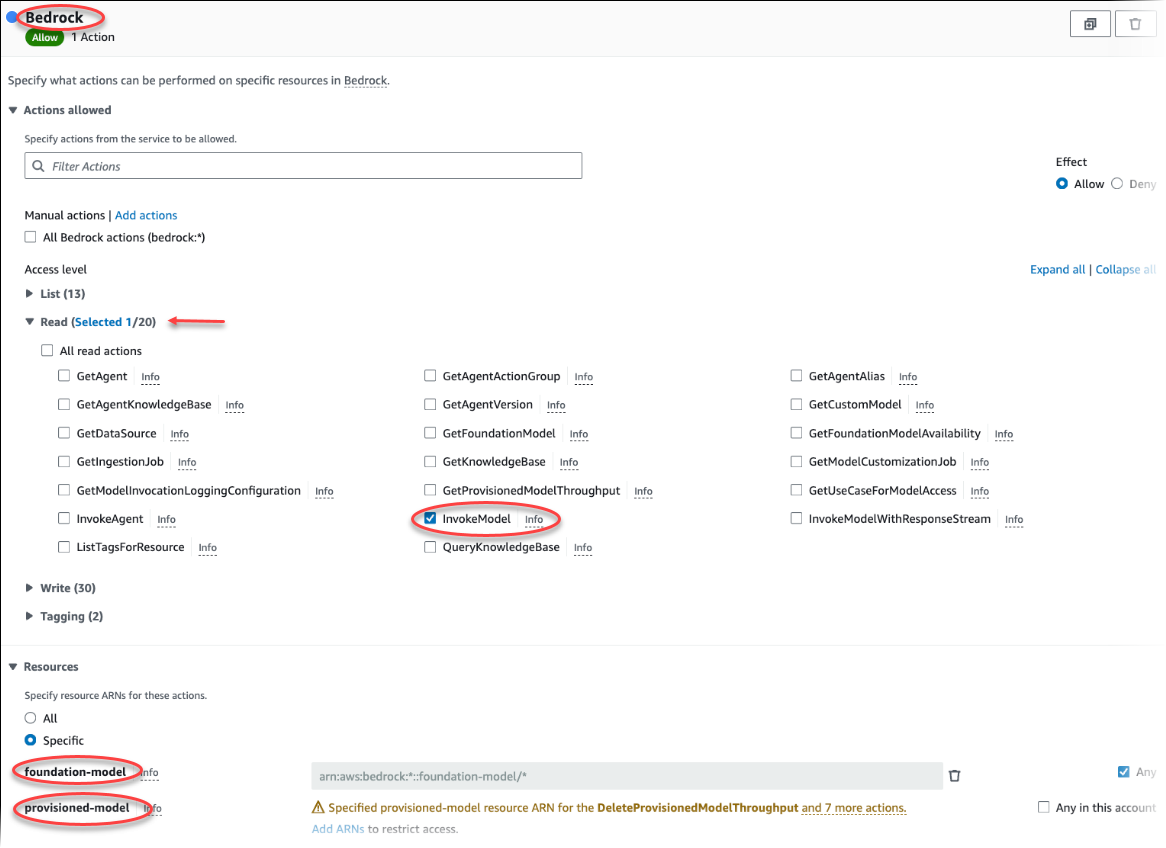
選擇 Next: Tags (下一步:標籤) 並定義任何標籤 (這是選用的)。選擇下一步:檢閱。輸入政策的名稱和描述,如圖所示。
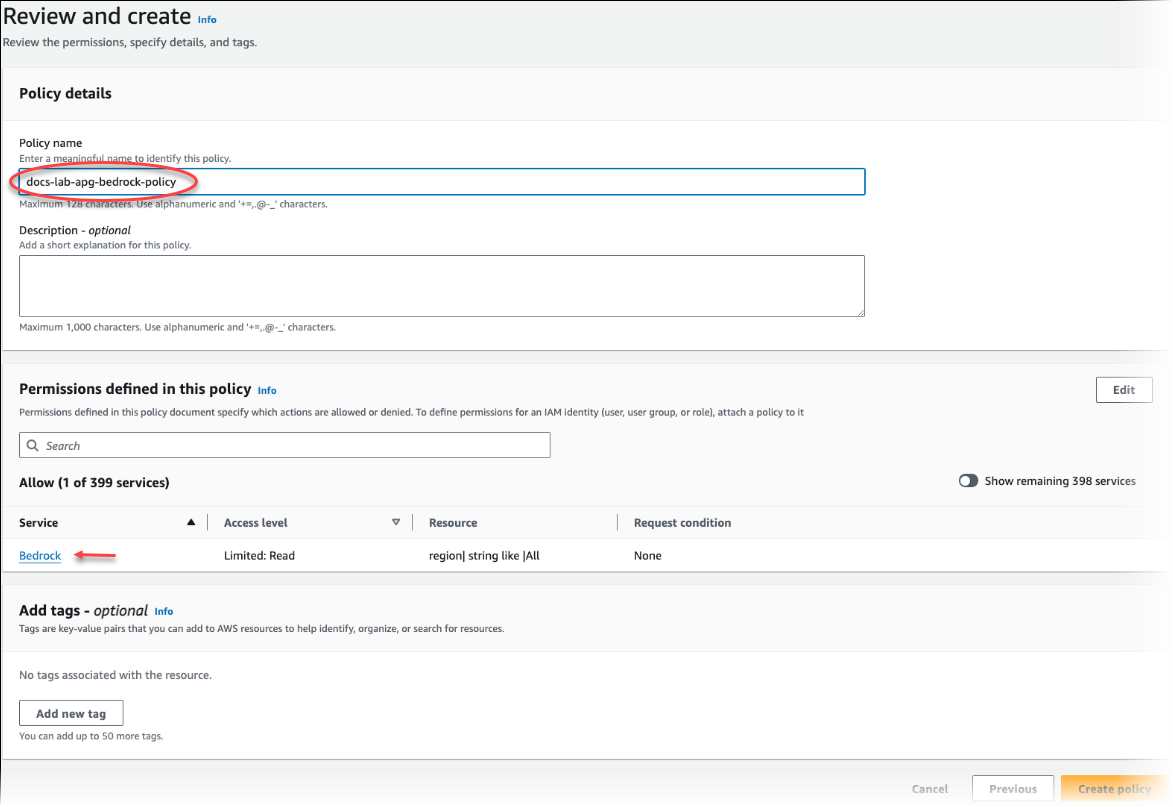
選擇建立政策。儲存策略後,主控台即會顯示警示。您可以在政策清單中找到它。
在 IAM 主控台功能表上選擇 Roles (角色) (在 Access management (存取管理) 之下)。
選擇建立角色。
在 Select trusted entity (選取信任的實體) 頁面上,選擇 AWS service (AWS 服務) 磚,然後選擇 RDS 以開啟選擇器。
選擇 RDS – Add Role to Database (RDS - 將角色新增至資料庫)。
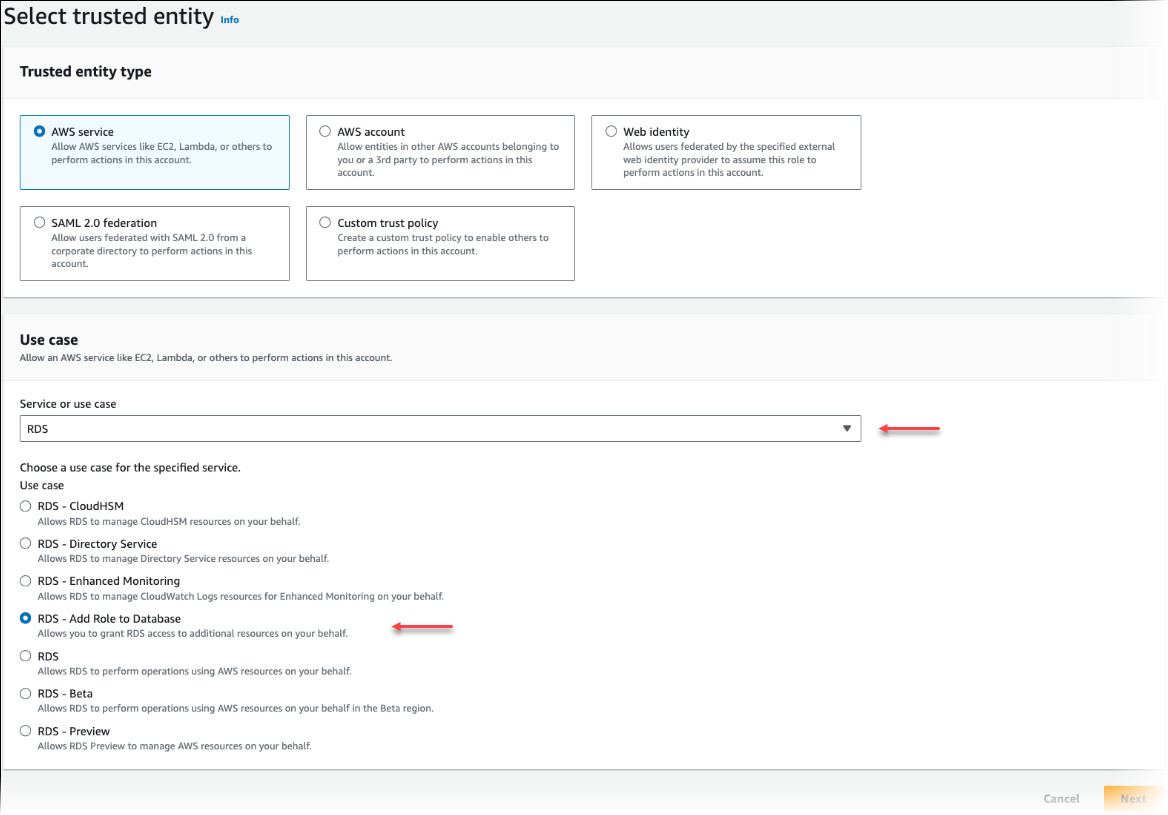
選擇下一步。在 Add permissions (新增許可) 頁面上,尋找您已在先前步驟中建立的政策,並從列出的政策之中進行選擇。選擇下一步。
Next: Review (下一步:檢閱)。輸入 IAM 角色的名稱和描述。
前往 https://console.aws.amazon.com/rds/
,開啟 Amazon RDS 主控台。 導覽至 AWS 區域 Aurora PostgreSQL 資料庫叢集所在的 。
-
在導覽窗格中選擇資料庫,然後選擇您要與 Bedrock 搭配使用的 Aurora PostgreSQL 資料庫叢集。
-
選擇 Connectivity & security (連線和安全) 索引標籤,並捲動至頁面的 Manage IAM roles (管理 IAM 角色) 區段。從 Add IAM roles to this cluster (將 IAM 角色新增至此叢集) 選擇器中,選擇您已在先前步驟中建立的角色。在功能選擇器中,選擇 Bedrock,然後選擇新增角色。
角色 (及其政策) 即會與 Aurora PostgreSQL 資料庫叢集相關聯。程序完成時,角色會列示在此叢集清單的目前 AM 角色中,如下所示。
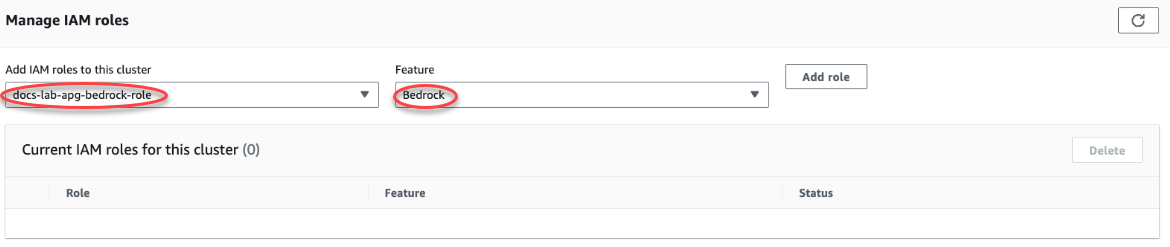
Amazon Bedrock 的 IAM 設定已完成。透過安裝延伸模組,繼續設定 Aurora PostgreSQL 以使用 Aurora Machine Learning,如安裝 Aurora Machine Learning 延伸模組中所述
設定 Aurora PostgreSQL 來使用 Amazon Comprehend
在以下程序中,您首先建立 IAM 角色和政策,授與 Aurora PostgreSQL 許可來代表叢集使用 Amazon Comprehend。然後,您可以將該政策附加到 Aurora PostgreSQL 資料庫叢集用來使用 Amazon Comprehend 的 IAM 角色,為了簡單起見,此程序會使用 AWS Management Console 來完成所有任務。
設定您的 Aurora PostgreSQL 資料庫叢集來使用 Amazon Comprehend
登入 AWS Management Console ,並在 https://https://console.aws.amazon.com/iam/
開啟 IAM 主控台。 前往 https://console.aws.amazon.com/iam/
開啟 IAM 主控台。 在 (IAM) 主控台功能表中選擇政策 AWS Identity and Access Management (在存取管理下)。
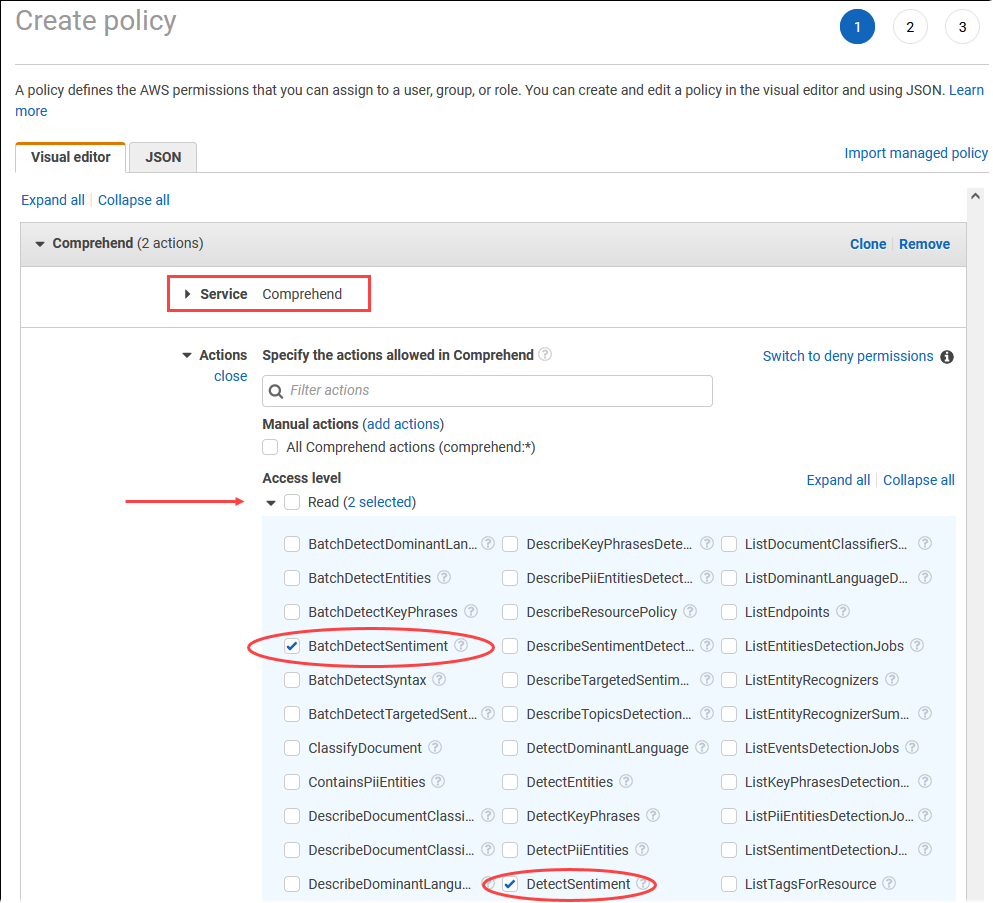
選擇建立政策。在視覺化編輯器頁面中,選擇 Service (服務),然後在 Select a service (選取服務) 欄位中輸入 Comprehend。展開讀取存取層級。從 Amazon Comprehend 讀取設定中選擇 BatchDetectSentiment 和 DetectSentiment 。
選擇 Next: Tags (下一步:標籤) 並定義任何標籤 (這是選用的)。選擇下一步:檢閱。輸入政策的名稱和描述,如圖所示。
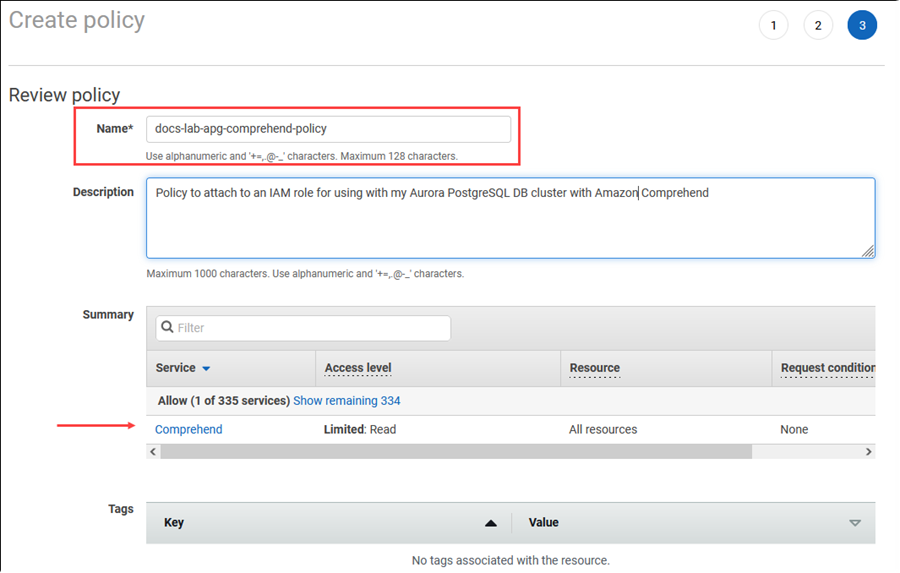
選擇建立政策。儲存策略後,主控台即會顯示警示。您可以在政策清單中找到它。
在 IAM 主控台功能表上選擇 Roles (角色) (在 Access management (存取管理) 之下)。
選擇建立角色。
在 Select trusted entity (選取信任的實體) 頁面上,選擇 AWS service (AWS 服務) 磚,然後選擇 RDS 以開啟選擇器。
選擇 RDS – Add Role to Database (RDS - 將角色新增至資料庫)。
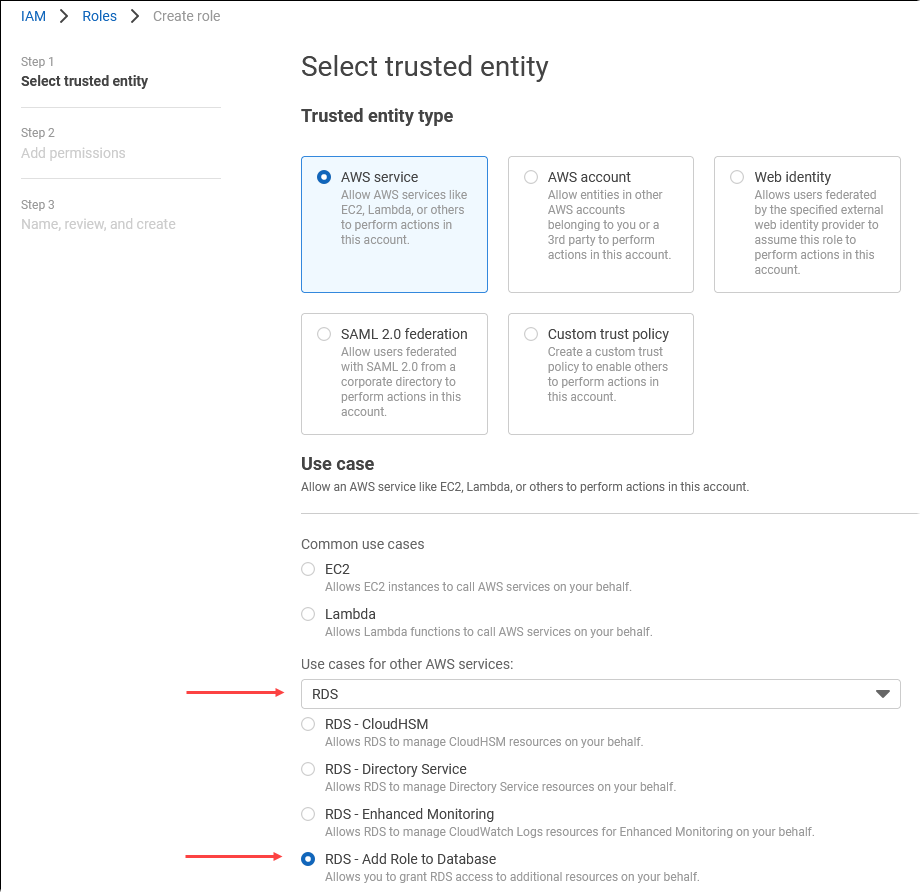
選擇下一步。在 Add permissions (新增許可) 頁面上,尋找您已在先前步驟中建立的政策,並從列出的政策之中進行選擇。選擇 Next (下一步)
Next: Review (下一步:檢閱)。輸入 IAM 角色的名稱和描述。
前往 https://console.aws.amazon.com/rds/
,開啟 Amazon RDS 主控台。 導覽至 AWS 區域 Aurora PostgreSQL 資料庫叢集所在的 。
-
在導覽窗格中選擇 Databases (資料庫),然後選擇您要與 Amazon Comprehend 搭配使用的 Aurora PostgreSQL 資料庫叢集。
-
選擇 Connectivity & security (連線和安全) 索引標籤,並捲動至頁面的 Manage IAM roles (管理 IAM 角色) 區段。從 Add IAM roles to this cluster (將 IAM 角色新增至此叢集) 選擇器中,選擇您已在先前步驟中建立的角色。在功能選擇器中,選擇 Comprehend,然後選擇新增角色。
角色 (及其政策) 即會與 Aurora PostgreSQL 資料庫叢集相關聯。程序完成時,角色會列示在此叢集清單的目前 AM 角色中,如下所示。
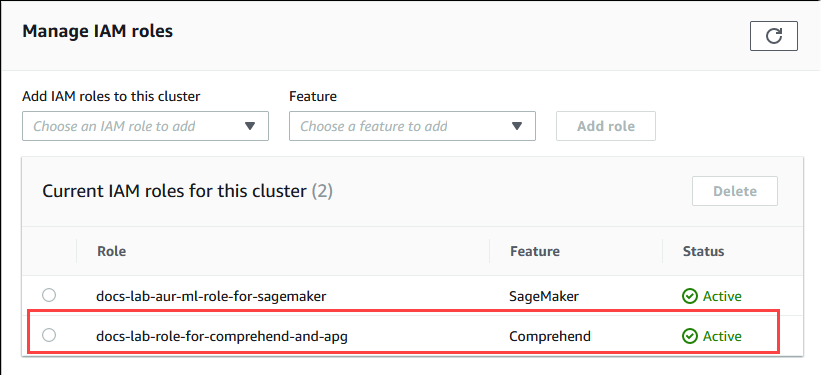
Amazon Comprehend 的 IAM 設定已完成。透過安裝延伸模組,繼續設定 Aurora PostgreSQL 以使用 Aurora Machine Learning,如安裝 Aurora Machine Learning 延伸模組中所述
設定 Aurora PostgreSQL 來使用 Amazon SageMaker AI
在為 Aurora PostgreSQL 資料庫叢集建立 IAM 政策和角色之前,您必須先設定 SageMaker AI 模型,並讓端點可用。
設定 Aurora PostgreSQL 資料庫叢集來使用 SageMaker AI
登入 AWS Management Console ,並在 https://https://console.aws.amazon.com/iam/
開啟 IAM 主控台。 在 (IAM) 主控台功能表中選擇政策 AWS Identity and Access Management (在存取管理下),然後選擇建立政策。在視覺化編輯器中,針對服務選擇 SageMaker。針對動作,開啟讀取選擇器 (在存取層級下),然後選擇 InvokeEndpoint。當執行此操作時,會顯示警告圖示。
開啟資源選擇器,然後在 InvokeEndpoint 動作的 Specify endpoint resource ARN (指定端點資源 ARN) 下選擇Add ARN to restrict access (新增 ARN 以限制存取) 連結。
輸入 AWS 區域 SageMaker AI 資源的 和端點的名稱。 AWS 您的帳戶已預先填入。
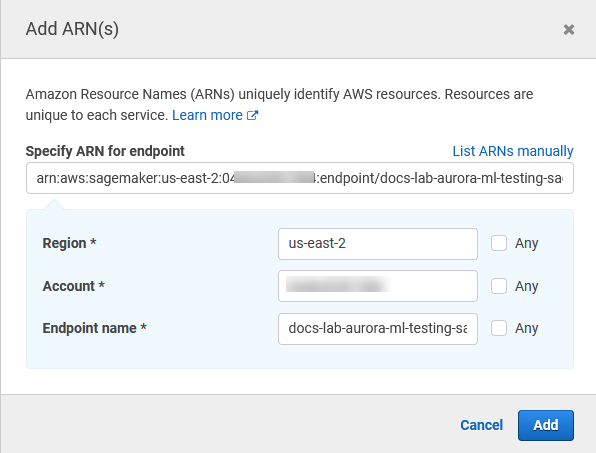
選擇 Add (新增) 以儲存。選擇 Next: Tags (下一步:標籤) 和 Next: Review (下一步:檢閱),以移至原則建立程序的最後一頁。
輸入此政策的名稱和描述,然後選擇 Create policy (建立政策)。即時會建立策略,並將其新增至政策清單。發生這種情況時,您會在主控台中看到警示。
在 IAM 主控台上,選擇 Roles (角色)。
選擇建立角色。
在 Select trusted entity (選取信任的實體) 頁面上,選擇 AWS service (AWS 服務) 磚,然後選擇 RDS 以開啟選擇器。
選擇 RDS – Add Role to Database (RDS - 將角色新增至資料庫)。
選擇下一步。在 Add permissions (新增許可) 頁面上,尋找您已在先前步驟中建立的政策,並從列出的政策之中進行選擇。選擇 Next (下一步)
Next: Review (下一步:檢閱)。輸入 IAM 角色的名稱和描述。
前往 https://console.aws.amazon.com/rds/
,開啟 Amazon RDS 主控台。 導覽至 AWS 區域 Aurora PostgreSQL 資料庫叢集所在的 。
-
在導覽窗格中選擇資料庫,然後選擇您要與 SageMaker AI 搭配使用的 Aurora PostgreSQL 資料庫叢集。
-
選擇 Connectivity & security (連線和安全) 索引標籤,並捲動至頁面的 Manage IAM roles (管理 IAM 角色) 區段。從 Add IAM roles to this cluster (將 IAM 角色新增至此叢集) 選擇器中,選擇您已在先前步驟中建立的角色。在功能選擇器中,選擇 SageMaker AI,然後選擇新增角色。
角色 (及其政策) 即會與 Aurora PostgreSQL 資料庫叢集相關聯。程序完成時,角色會列示在此叢集清單的目前 AM 角色中。
SageMaker AI 的 IAM 設定已完成。透過安裝延伸模組,繼續設定 Aurora PostgreSQL 以使用 Aurora Machine Learning,如安裝 Aurora Machine Learning 延伸模組中所述。
設定 Aurora PostgreSQL 來使用 Amazon S3 for SageMaker AI (進階)
若要搭配您自己的模型使用 SageMaker AI,而不是使用 SageMaker AI 提供的預先建置元件,您需要設定 Amazon Simple Storage Service (Amazon S3) 儲存貯體,供 Aurora PostgreSQL 資料庫叢集使用。這是進階主題,並未在此《Amazon Aurora 使用者指南》中完整記載。一般程序與整合 SageMaker AI 支援相同,如下所示。
為 Amazon S3 建立 IAM 政策和角色。
在 Aurora PostgreSQL 資料庫叢集的 Connectivity & security (連線和安全) 索引標籤上,新增 IAM 角色和 Amazon S3 匯入或匯出做為功能。
將角色的 ARN 新增至 Aurora 資料庫叢集的自訂資料庫叢集參數群組。
如需基本使用方式的資訊,請參閱 將資料匯出至 Amazon S3 進行 SageMaker AI 模型訓練 (進階)。
安裝 Aurora Machine Learning 延伸模組
Aurora 機器學習延伸模組 aws_ml 1.0 提供兩種函數,您可用於調用 Amazon Comprehend、SageMaker AI 服務,且 aws_ml 2.0 並提供兩種額外的函數,您可用於調用 Amazon Bedrock 服務。在 Aurora PostgreSQL 資料庫叢集上安裝這些延伸模組也會建立功能的管理角色。
注意
使用這些功能取決於是否需要 Aurora 機器學習服務 (Amazon Comprehend、SageMaker AI、Amazon Bedrock) 完成 IAM 設定,如設定 Aurora PostgreSQL 資料庫叢集來使用 Aurora Machine Learning中所述。
aws_comprehend.detect_sentiment – 您可以使用此函數,將情緒分析套用至存放在 Aurora PostgreSQL 資料庫叢集上資料庫中的文字。
aws_sagemaker.invoke_endpoint:您可以在 SQL 程式碼中使用此函數,與來自叢集的 SageMaker AI 端點進行通訊。
aws_bedrock.invoke_model:您可以在 SQL 程式碼中使用此函數,與來自叢集的 Bedrock 模型進行通訊。此函數的回應將採用 TEXT 格式,因此,如果模型以 JSON 內文格式回應,則此函數的輸出將以字串格式轉送給最終使用者。
aws_bedrock.invoke_model_get_embeddings:您可以在 SQL 程式碼中使用此函數來調用 Bedrock 模型,以在 JSON 回應中傳回輸出嵌入。當您想要擷取直接與 json-key 相關聯的嵌入,以簡化任何自我管理工作流程的回應時,可以利用此功能。
在 Aurora PostgreSQL 資料庫叢集中安裝 Aurora Machine Learning 延伸模組
使用
psql連線到 Aurora PostgreSQL 資料庫叢集的寫入器執行個體。連線到要在其中安裝aws_ml延伸模組的特定資料庫。psql --host=cluster-instance-1.111122223333.aws-region.rds.amazonaws.com --port=5432 --username=postgres --password --dbname=labdb
labdb=>CREATE EXTENSION IF NOT EXISTS aws_ml CASCADE;NOTICE: installing required extension "aws_commons" CREATE EXTENSIONlabdb=>
安裝 aws_ml 延伸模組也會建立 aws_ml 系統管理角色和三個新結構描述,如下所示。
aws_comprehend– Amazon Comprehend 服務的結構描述和detect_sentiment函數的來源 (aws_comprehend.detect_sentiment)。aws_sagemaker:SageMaker AI 服務的結構描述和invoke_endpoint函數的來源 (aws_sagemaker.invoke_endpoint)。aws_bedrock:Amazon Bedrock 服務的結構描述和invoke_model(aws_bedrock.invoke_model)和invoke_model_get_embeddings(aws_bedrock.invoke_model_get_embeddings)函數的來源。
rds_superuser 角色獲授與 aws_ml 管理角色,並由這三個 Aurora 機器學習結構描述的 OWNER 組成。若要允許其他資料庫使用者存取 Aurora Machine Learning 函數,rds_superuser 需要授與 Aurora Machine Learning 函數的 EXECUTE 權限。根據預設,會在兩個 Aurora Machine Learning 結構描述中的函數上撤銷 PUBLIC 的 EXECUTE 權限。
在多租用戶資料庫組態中,您可以在要保護的特定 Aurora Machine Learning 結構描述上使用 REVOKE USAGE,防止租用戶存取 Aurora Machine Learning 函數。
搭配 Aurora PostgreSQL 資料庫叢集使用 Amazon Bedrock
對於 Aurora PostgreSQL,Aurora 機器學習提供下列 Amazon Bedrock 函數,用於與文字資料搭配使用。只有在您安裝 aws_ml 2.0 延伸模組並完成所有設定程序之後,才能使用此函數。如需詳細資訊,請參閱設定 Aurora PostgreSQL 資料庫叢集來使用 Aurora Machine Learning。
- aws_bedrock.invoke_model
-
此函數採用 JSON 格式的文字作為輸入、處理 Amazon Bedrock 上託管的各種模型,以及從模型傳回 JSON 文字回應。此回應可能包含文字、影像或嵌入。函數文件的摘要如下。
aws_bedrock.invoke_model( IN model_id varchar, IN content_type text, IN accept_type text, IN model_input text, OUT model_output varchar)
此函數的輸入和輸出如下。
-
model_id:模型的識別符。 content_type:Bedrock 模型的請求類型。accept_type:從 Bedrock 模型預期的回應類型。通常適用於大多數模型的應用程式/JSON。model_input:提示;以 content_type 指定的格式對模型輸入的特定集合。如需模型接受之請求格式/結構的詳細資訊,請參閱基礎模型的推論參數。model_output:文字形式的 Bedrock 模型輸出。
下列範例示範如何使用 invoke_model 調用 Bedrock 的 Anthropic Claude 2 模型。
範例範例:使用 Amazon Bedrock 函數的簡單查詢
SELECT aws_bedrock.invoke_model ( model_id := 'anthropic.claude-v2', content_type:= 'application/json', accept_type := 'application/json', model_input := '{"prompt": "\n\nHuman: You are a helpful assistant that answers questions directly and only using the information provided in the context below.\nDescribe the answer in detail.\n\nContext: %s \n\nQuestion: %s \n\nAssistant:","max_tokens_to_sample":4096,"temperature":0.5,"top_k":250,"top_p":0.5,"stop_sequences":[]}' );
- aws_bedrock.invoke_model_get_embeddings
-
在某些情況下,模型輸出可能會指向向量嵌入。由於每個模型的回應有所不同,可以利用另一個函數 invoke_model_get_embeddings,其運作方式與 invoke_model 完全相同,但會透過指定適當的 json-key 來輸出嵌入。
aws_bedrock.invoke_model_get_embeddings( IN model_id varchar, IN content_type text, IN json_key text, IN model_input text, OUT model_output float8[])
此函數的輸入和輸出如下。
-
model_id:模型的識別符。 content_type:Bedrock 模型的請求類型。在這裡,accept_type 會設為預設值application/json。model_input:提示;以 content_type 指定的格式對模型輸入的特定集合。如需模型接受之請求格式/結構的詳細資訊,請參閱基礎模型的推論參數。json_key:參考欄位以從中擷取嵌入。如果嵌入模型有所變更,這可能會不同。-
model_output:Bedrock 模型的輸出,作為具有 16 位元十進位的嵌入陣列。
下列範例顯示如何針對 PostgreSQL I/O 監控檢視一詞使用 Titan 嵌入 G1 (文字嵌入模型) 產生嵌入。
範例範例:使用 Amazon Bedrock 函數的簡單查詢
SELECT aws_bedrock.invoke_model_get_embeddings( model_id := 'amazon.titan-embed-text-v1', content_type := 'application/json', json_key := 'embedding', model_input := '{ "inputText": "PostgreSQL I/O monitoring views"}') AS embedding;
搭配 Aurora PostgreSQL 資料庫叢集使用 Amazon Comprehend
對於 Aurora PostgreSQL,Aurora Machine Learning 提供下列 Amazon Comprehend 函數,用於使用您的文字資料。只有在您安裝 aws_ml 延伸模組並完成所有設定程序之後,才能使用此函數。如需詳細資訊,請參閱設定 Aurora PostgreSQL 資料庫叢集來使用 Aurora Machine Learning。
- aws_comprehend.detect_sentiment
-
此函數會以文字做為輸入,並評估文字是否具有正面、負面、中性或混合的情緒狀態。它會輸出此情緒以及評估的信賴等級。函數文件的摘要如下。
aws_comprehend.detect_sentiment( IN input_text varchar, IN language_code varchar, IN max_rows_per_batch int, OUT sentiment varchar, OUT confidence real)
此函數的輸入和輸出如下。
-
input_text– 要評估和指派情緒 (負面、正面、中性、混合) 的文字。 language_code– 使用 2 字母的 ISO 639-1 識別碼搭配地區子標籤 (視需要) 或 ISO 639-2 三字母代碼 (視情況而定) 所識別之input_text的語言。例如,en是英文代碼,而zh是簡體中文的代碼。如需詳細資訊,請參閱《Amazon 開發人員指南》中的支援的語言。max_rows_per_batch– 批次模式處理中每個批次的資料列數量上限。如需詳細資訊,請參閱了解批次模式和 Aurora Machine Learning 函數。sentiment– 輸入文字的情緒,識別為 POSITIVE、NEGATIVE、NEUTRAL 或 MIXED。confidence– 所在指定sentiment之準確性中的信賴程度。值的範圍從 0.0 到 1.0。
在下列內容中,您可以找到如何使用此函數的範例。
範例範例:使用 Amazon Comprehend 的簡單查詢
以下是簡單查詢的範例,該查詢會叫用此函數,以評估客戶對支援團隊的滿意度。假設您有一個資料庫資料表 (support),其會在每次請求協助之後存放客戶意見回饋。此範例查詢會將 aws_comprehend.detect_sentiment 函數套用至資料表的 feedback 資料欄中的文字,並輸出情緒以及該情緒的信賴等級。此查詢也會以遞減順序輸出結果。
SELECT feedback, s.sentiment,s.confidence FROM support,aws_comprehend.detect_sentiment(feedback, 'en') s ORDER BY s.confidence DESC;feedback | sentiment | confidence ----------------------------------------------------------+-----------+------------ Thank you for the excellent customer support! | POSITIVE | 0.999771 The latest version of this product stinks! | NEGATIVE | 0.999184 Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 Your product is too complex, but your support is great. | MIXED | 0.957958 Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 My problem was never resolved! | NEGATIVE | 0.920644 When will the new version of this product be released? | NEUTRAL | 0.902706 I cannot stand that chatbot. | NEGATIVE | 0.895219 Your support tech talked down to me. | NEGATIVE | 0.868598 It took me way too long to get a real person. | NEGATIVE | 0.481805 (10 rows)
為了避免針對每個資料表資料列的情緒分析產生費用超過一次,您可以將結果具體化。請在您感興趣的資料列上執行此作業。例如,臨床醫師的筆記正在更新,以便只有法文 (fr) 的筆記使用情緒偵測函數。
UPDATE clinician_notes SET sentiment = (aws_comprehend.detect_sentiment (french_notes, 'fr')).sentiment, confidence = (aws_comprehend.detect_sentiment (french_notes, 'fr')).confidence WHERE clinician_notes.french_notes IS NOT NULL AND LENGTH(TRIM(clinician_notes.french_notes)) > 0 AND clinician_notes.sentiment IS NULL;
如需最佳化您函數呼叫的詳細資訊,請參閱 搭配 Aurora PostgreSQL 使用 Aurora Machine Learning 的效能考量。
搭配 Aurora PostgreSQL 資料庫叢集使用 SageMaker AI
如設定 Aurora PostgreSQL 來使用 Amazon SageMaker AI中所述,在設定 SageMaker AI 環境並與 Aurora PostgreSQL 整合之後,您可以使用 aws_sagemaker.invoke_endpoint 函數調用這些操作。aws_sagemaker.invoke_endpoint 函數只會連線到相同 AWS 區域中的模型端點。如果資料庫執行個體具有多個複本, AWS 區域
必須確保您會設定每個 SageMaker AI 模型,並將其部署到每個 AWS 區域。
對 aws_sagemaker.invoke_endpoint 的呼叫進行身分驗證,方法為使用您設定為將 Aurora PostgreSQL 資料庫叢集與 SageMaker AI 服務和您在設定過程中所提供的端點建立關聯的 IAM 角色。SageMaker AI 模型端點的範圍僅限個別帳戶,而非公有。所以 endpoint_name 網址中不包含帳戶 ID。SageMaker AI 會從資料庫執行個體 SageMaker AI IAM 角色提供的身分驗證字符中判斷帳戶 ID。
- aws_sagemaker.invoke_endpoint
此函數會採取 SageMaker AI 端點作為輸入,以及採取應作為批次處理的列數目。其也會作為 SageMaker AI 模型端點所預期之各種參數的輸入。此函數的參考文件如下。
aws_sagemaker.invoke_endpoint( IN endpoint_name varchar, IN max_rows_per_batch int, VARIADIC model_input "any", OUT model_output varchar )
此函數的輸入和輸出如下。
endpoint_name– AWS 區域獨立端點 URL。max_rows_per_batch– 批次模式處理中每個批次的資料列數量上限。如需詳細資訊,請參閱了解批次模式和 Aurora Machine Learning 函數。model_input– 模型的一或多個輸入參數。這些參數可以是 SageMaker AI 模型所需的任何資料類型。PostgreSQL 允許您為函數指定最多 100 個輸入參數。陣列資料類型必須是一維陣列,但可以包含 SageMaker AI 模型預期的任意數量元素。對 SageMaker AI 模型的輸入數僅受限於 SageMaker AI 6 MB 的訊息大小限制。model_output:作為文字的 SageMaker AI 模型輸出。
建立使用者定義函數來調用 SageMaker AI 模型
建立一個單獨的使用者定義函數,呼叫您每個 SageMaker AI 模型的 aws_sagemaker.invoke_endpoint。使用者定義函數代表託管模型的 SageMaker AI 端點。aws_sagemaker.invoke_endpoint 函數會在使用者定義函數內執行。使用者定義函數提供許多優點:
-
您可以自行為 SageMaker AI 模型命名,而非將所有 SageMaker AI 模型稱呼為
aws_sagemaker.invoke_endpoint。 -
您可以在您 SQL 應用程式程式碼中的同一個位置指定模型端點 URL。
-
您可以單獨控制每個 Aurora Machine Learning 函數的
EXECUTE權限。 -
您可以使用 SQL 類型宣告模型輸入和輸出類型。SQL 會強制您傳遞至 SageMaker AI 模型的引數數量和類型,並視需要執行類型轉換。使用 SQL 類型也會將
SQL NULL轉換成 SageMaker AI 模型預期的適當預設值。 -
如果您希望更快地傳回前幾個資料列,您可以減少批次大小上限。
如要指定使用者定義函數,請使用 SQL 資料定義語言 (DDL) 陳述式 CREATE FUNCTION。在您定義函數時,您可以指定以下內容:
-
對模型的輸入參數。
-
要調用的特定 SageMaker AI 端點。
-
傳回類型。
使用者定義函數會在針對輸入參數執行模型後,傳回 SageMaker AI 端點運算的推論。以下範例會為 SageMaker AI 模型建立使用者定義函數,並包含兩個輸入參數。
CREATE FUNCTION classify_event (IN arg1 INT, IN arg2 DATE, OUT category INT)
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', NULL,
arg1, arg2 -- model inputs are separate arguments
)::INT -- cast the output to INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;注意下列事項:
-
aws_sagemaker.invoke_endpoint函數輸入可以是任何資料類型的一或多個參數。 -
此範例使用 INT 輸出類型。如果您將
varchar類型的輸出轉換成不同類型,則必須將其轉換成 PostgreSQL 內建的純量類型,例如INTEGER、REAL、FLOAT或NUMERIC。如需這些類型的詳細資訊,請參閱 PostgreSQL 文件的 Data Types。 -
指定
PARALLEL SAFE來啟用平行查詢處理。如需更多詳細資訊,請參閱 使用平行查詢處理改善回應時間。 -
指定
COST 5000來可預估執行函數的成本。使用正數來表示函數的預估執行成本 (單位為cpu_operator_cost)。
將陣列作為輸入傳遞至 SageMaker AI 模型
aws_sagemaker.invoke_endpoint 函數可以擁有最多 100 個輸入參數。這項限制是 PostgreSQL 函數的限制。如果 SageMaker AI 模型需要超過 100 個相同類型的參數,請將模型參數作為陣列傳遞。
以下範例會定義一個函數,將陣列作為輸入傳遞至 SageMaker AI 迴歸模型。輸出會轉換為 REAL 值。
CREATE FUNCTION regression_model (params REAL[], OUT estimate REAL) AS $$ SELECT aws_sagemaker.invoke_endpoint ( 'sagemaker_model_endpoint_name', NULL, params )::REAL $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
在調用 SageMaker AI 模型時指定批次大小
以下範例會為 SageMaker AI 模型建立使用者定義函數,將批次大小預設值設為 NULL。該函數也允許您在呼叫時提供不同的批次大小。
CREATE FUNCTION classify_event (
IN event_type INT, IN event_day DATE, IN amount REAL, -- model inputs
max_rows_per_batch INT DEFAULT NULL, -- optional batch size limit
OUT category INT) -- model output
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', max_rows_per_batch,
event_type, event_day, COALESCE(amount, 0.0)
)::INT -- casts output to type INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;注意下列事項:
-
使用選用的
max_rows_per_batch參數來控制批次模式函數呼叫的資料列數。如果您使用 NULL 值,則查詢最佳化工具會自動選擇最大的批次大小。如需詳細資訊,請參閱了解批次模式和 Aurora Machine Learning 函數。 -
根據預設,傳遞 NULL 作為參數值會先轉換成空白字串,再傳遞給 SageMaker AI。針對此範例,輸入具有不同的類型。
-
如果您有非文字的輸入,或是需要預設為空白字串以外值的文字輸入,請使用
COALESCE陳述式。在對COALESCE的呼叫中,使用aws_sagemaker.invoke_endpoint將 NULL 轉換成所需的 null 取代值。針對此範例中的amount參數,NULL 值會轉換成 0.0。
呼叫具有多個輸出的 SageMaker AI 模型
以下範例會為 SageMaker AI 模型建立使用者定義函數,傳回多個輸出。您的函數需要將 aws_sagemaker.invoke_endpoint 函數的輸出轉換成對應的資料類型。例如,您可以針對 (x,y) 對使用內建的 PostgreSQL 點類型,或是使用者定義的複合類型。
這個使用者定義函數會針對輸出,使用複合類型從傳回多個輸出的模型傳回值。
CREATE TYPE company_forecasts AS ( six_month_estimated_return real, one_year_bankruptcy_probability float); CREATE FUNCTION analyze_company ( IN free_cash_flow NUMERIC(18, 6), IN debt NUMERIC(18,6), IN max_rows_per_batch INT DEFAULT NULL, OUT prediction company_forecasts) AS $$ SELECT (aws_sagemaker.invoke_endpoint('endpt_name', max_rows_per_batch,free_cash_flow, debt))::company_forecasts; $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
針對複合類型,請根據欄位在模型中的順序,以相同順序使用欄位,並將 aws_sagemaker.invoke_endpoint 的輸出轉換成您的複合類型。發起人可以透過名稱或 PostgreSQL ".*" 表示法擷取個別欄位。
將資料匯出至 Amazon S3 進行 SageMaker AI 模型訓練 (進階)
我們建議您使用提供的演算法和範例,熟悉 Aurora 機器學習和 SageMaker AI,而不是嘗試訓練自己的模型。如需詳細資訊,請參閱開始使用 Amazon SageMaker AI
如要訓練 SageMaker AI 模型,您可以將資料匯出到 Amazon S3 儲存貯體。SageMaker AI 會使用 Amazon S3 儲存貯體來訓練您的模型,之後再進行部署。您可以從 Aurora PostgreSQL 資料庫叢集查詢資料,並直接將這些資料儲存到存放在 Amazon S3 儲存貯體中的文字檔案。SageMaker AI 接著會使用 Amazon S3 儲存貯體的資料進行訓練。如需 SageMaker AI 模型訓練的詳細資訊,請參閱使用 Amazon SageMaker AI 訓練模型。
注意
當您建立 S3 儲存貯體進行 SageMaker AI 模型訓練或批次評分時,請在 S3 儲存貯體名稱中使用 sagemaker。如需詳細資訊,請參閱《Amazon SageMaker AI 開發人員指南》中的指定 Amazon S3 儲存貯體以上傳訓練資料集和存放輸出資料。
如需匯出您資料的詳細資訊,請參閱 將資料從 Aurora PostgreSQL 資料庫叢集匯出至 Amazon S3。
搭配 Aurora PostgreSQL 使用 Aurora Machine Learning 的效能考量
當透過 Aurora 機器學習函數調用時,Amazon Comprehend 和 SageMaker AI 服務會執行大部分工作。這表示您可以視需要獨立擴展這些資源。對於您的 Aurora PostgreSQL 資料庫叢集,您可以盡可能有效地進行函數呼叫。接下來,您可以找到從 Aurora PostgreSQL 使用 Aurora Machine Learning 時需要注意的一些效能考量。
了解批次模式和 Aurora Machine Learning 函數
通常,PostgreSQL 會一次針對單一資料列執行函數。Aurora Machine Learning 可以採用稱為「批次模式執行」的方法,透過將許多資料列對外部 Aurora Machine Learning 服務的呼叫合併成批次,來減少這項額外負荷。在批次模式中,Aurora Machine Learning 會收到輸入資料列批次的回應,然後一次針對單一資料列將回應交付回正在執行的查詢。這項最佳化可以改善您 Aurora 查詢的輸送量,而無須限制 PostgreSQL 查詢最佳化工具。
如果函數是從 SELECT 清單、WHERE 子句或 HAVING 子句進行推論,Aurora 會自動使用批次模式。請注意,最上層的簡易 CASE 表達式適用批次模式執行。如果第一個 CASE 子句是包含批次模式函數呼叫的簡易述詞,則最上層的搜尋 WHEN 表達式也適用批次模式執行。
您的使用者定義函數必須是 LANGUAGE SQL 函數,且應指定 PARALLEL SAFE 和 COST 5000。
從 SELECT 陳述式到 FROM 子句的函數遷移
通常,Aurora 會自動將適用批次模式執行的 aws_ml 函數遷移至 FROM 子句。
您可以透過每個查詢層級,手動檢查適用批次模式函數遷移至 FROM 子句的過程。若要執行此作業,您可以使用 EXPLAIN 陳述式 (以及 ANALYZE 和 VERBOSE) 來在每個批次模式 Function Scan 的下方尋找「批次處理」資訊。您也可以使用 EXPLAIN (搭配 VERBOSE),而無須執行查詢。您接著可以觀察對函數的呼叫在並未於原始陳述式中指定的巢狀迴圈聯結下方,是否顯示為 Function
Scan。
在以下範例中,計劃中的巢狀迴圈聯結運算子會顯示 Aurora 遷移了 anomaly_score 函數。Aurora 會在函數適用批次模式執行時,將此函數從 SELECT 清單遷移至 FROM 子句。
EXPLAIN (VERBOSE, COSTS false)
SELECT anomaly_score(ts.R.description) from ts.R;
QUERY PLAN
-------------------------------------------------------------
Nested Loop
Output: anomaly_score((r.description)::text)
-> Seq Scan on ts.r
Output: r.id, r.description, r.score
-> Function Scan on public.anomaly_score
Output: anomaly_score.anomaly_score
Function Call: anomaly_score((r.description)::text)如要停止批次模式執行,請將 apg_enable_function_migration 參數設為 false。這可以防止將 aws_ml 函數從 SELECT 遷移至 FROM 子句。以下顯示作法。
SET apg_enable_function_migration = false;apg_enable_function_migration 參數是 Grand Unified Configuration (GUC) 參數。Aurora PostgreSQL apg_plan_mgmt 延伸會針對查詢計劃管理識別此參數。如要停用工作階段中的函數遷移,請使用查詢計劃管理來將結果計劃儲存為 approved 計劃。在執行時間,查詢計劃管理會透過其 approved 設定,強制實行 apg_enable_function_migration 計劃。這項強制實行無論 apg_enable_function_migration GUC 參數設定為何都會發生。如需更多詳細資訊,請參閱 管理 Aurora PostgreSQL 的查詢執行計劃。
使用 max_rows_per_batch 參數
aws_comprehend.detect_sentiment 和 aws_sagemaker.invoke_endpoint 函數都有一個 max_rows_per_batch 參數。此參數會指定可傳送至 Aurora Machine Learning 服務的資料列數目。您的函數處理的資料集越大,您的批次大小就越大。
批次模式函數會透過建置資料列批次,將 Aurora Machine Learning 函數呼叫的成本分散到大量的資料列,來改善效率。但是,如果 SELECT 陳述式因為 LIMIT 子句而提前完成,則可以針對比查詢所使用資料列數更多的資料列建構批次。這種方法可能會對您的帳戶產生額外費用 AWS 。如要利用批次模式執行的優點,同時避免建置過大的批次,請在您的函數呼叫中針對 max_rows_per_batch 參數使用較小的值。
如果您執行的查詢 EXPLAIN (VERBOSE、ANALYZE) 使用批次模式執行,您會看到位於巢狀迴圈聯結下方的 FunctionScan 運算子。EXPLAIN 報告的迴圈數等於您從 FunctionScan 運算子擷取資料列的次數。如果陳述式使用 LIMIT 子句,則擷取數將會是一致的。如要最佳化批次大小,請將 max_rows_per_batch 參數設為這個值。但是,如果在 WHERE 子句或 HAVING 子劇中的述詞內參考批次模式函數,您便可能無法事先得知擷取數。在此情況下,請使用迴圈做為準則並針對 max_rows_per_batch 進行實驗,尋找最佳化效能的設定。
驗證批次模式執行
要查看函數是否以批次處理模式執行,請使用 EXPLAIN ANALYZE。如果使用了批次模式執行,則查詢計劃會在「批次處理」區段包含資訊。
EXPLAIN ANALYZE SELECT user-defined-function();
Batch Processing: num batches=1 avg/min/max batch size=3333.000/3333.000/3333.000
avg/min/max batch call time=146.273/146.273/146.273在此範例中,有 1 個包含了 3,333 個資料列的批次,其處理的時間為 146.273 毫秒。「批次處理」區段會顯示以下內容:
-
此函數掃描操作有多少批次
-
批次的平均大小、最小值和最大值
-
批次的平均執行時間、最小值和最大值
通常最後一個批次會比其餘批次小,並且通常會導致比平均小許多的批次大小下限。
如要更快地傳回前幾個資料列,請將 max_rows_per_batch 參數設為較小的值。
如要在您於使用者定義函數中使用 LIMIT 時減少對 ML 服務的批次模式呼叫數,請將 max_rows_per_batch 參數設為較小的值。
使用平行查詢處理改善回應時間
若要從大量資料列中盡快取得結果,您可以將平行查詢處理與批次模式處理結合。您可以針對 SELECT、CREATE TABLE AS SELECT 和 CREATE
MATERIALIZED VIEW 陳述式使用平行查詢處理。
注意
PostgreSQL 尚未支援資料處理語言 (DML) 陳述式的平行查詢。
平行查詢處理會在資料庫和 ML 服務中進行。資料庫執行個體類別中的核心數會限制執行查詢時所能使用的平行處理程度。資料庫伺服器可以建構平行查詢執行計劃,分割一組平行工作者中的任務。然後,這些工作者都可以各自建置批次請求,其中包含了成千上萬個資料列 (或是每個服務允許的最大數量)。
所有平行工作者的批次請求都會傳送到 SageMaker AI 端點。端點可支援的平行處理程度受制於支援它的執行個體數目和類型。對於 K 程度的平行處理,您需要至少具有 K 個核心的資料庫執行個體類別。您也需要設定模型的 SageMaker AI 端點,讓其擁有 K 個效能夠高執行個體類別的初始執行個體。
若要使用平行查詢處理,您可以設定包含您計劃傳遞資料資料表的 parallel_workers 儲存參數。您可以將 parallel_workers 設為批次模式函數,例如 aws_comprehend.detect_sentiment。如果最佳化工具選擇平行查詢計畫,則可以批次和平行呼叫 AWS ML 服務。
您可以搭配 aws_comprehend.detect_sentiment 函數使用下列參數,取得具備四向平行處理的計劃。如果變更下列兩個參數之一,您必須重新啟動資料庫執行個體,變更才會生效
-- SET max_worker_processes to 8; -- default value is 8
-- SET max_parallel_workers to 8; -- not greater than max_worker_processes
SET max_parallel_workers_per_gather to 4; -- not greater than max_parallel_workers
-- You can set the parallel_workers storage parameter on the table that the data
-- for the Aurora machine learning function is coming from in order to manually override the degree of
-- parallelism that would otherwise be chosen by the query optimizer
--
ALTER TABLE yourTable SET (parallel_workers = 4);
-- Example query to exploit both batch-mode execution and parallel query
EXPLAIN (verbose, analyze, buffers, hashes)
SELECT aws_comprehend.detect_sentiment(description, 'en')).*
FROM yourTable
WHERE id < 100;如需控制平行查詢的詳細資訊,請參閱 PostgreSQL 文件中的 Parallel Plans
使用具體化檢視和具體化資料行
當您從資料庫叫用 SageMaker AI 或 Amazon Comprehend 等 AWS 服務時,會根據該服務的定價政策向您的帳戶收費。若要將 帳戶的費用降至最低,您可以將呼叫 AWS 服務的結果具體化為具體化資料欄,以便每個輸入列呼叫 AWS 服務不超過一次。如果需要,您可以新增 materializedAt 時間戳記資料行,記錄具體化資料行的時間。
一般單一資料列 INSERT 陳述式的延遲通常會比呼叫批次模式函數的延遲要小得多。因此,如果您針對您應用程式執行 INSERT 的每個單一資料列呼叫批次模式函數,您便可以無法滿足應用程式的延遲需求。為了具體化將 AWS 服務呼叫具體化資料欄的結果,高效能應用程式通常需要填入具體化資料欄。為了執行此作業,這些應用程式通常會發出 UPDATE 陳述式,同時在大型的資料列批次上運作。
UPDATE 會採用資料列層級鎖定,可能影響正在執行的應用程式。因此,您可能需要使用 SELECT ... FOR UPDATE SKIP LOCKED,或是使用 MATERIALIZED
VIEW。
在大量資料列上即時運作的分析查詢可以將批次模式具體化與即時處理合併。為了執行此作業,這些查詢會將預先具體化結果的 UNION ALL 與尚未包含具體化結果的資料列查詢結合。在某些情況下,許多位置都需要該 UNION ALL,或是由第三方應用程式產生查詢。若是這種情況,您可以建立 VIEW 來封裝 UNION ALL 操作,避免向 SQL 應用程式的其餘部分公開這項詳細資訊。
您可以使用具體化檢視來及時具體化快照中任意 SELECT 陳述式的結果。您也可以使用具體化檢視來在未來隨時重新整理具體化檢視。目前 PostgreSQL 不支援增量重新整理,因此每次重新整理具體化檢視時,都會重新運算具體化檢視。
您可以使用 CONCURRENTLY 選項重新整理具體化檢視,更新具體化檢視的內容,而無須採取獨佔鎖定。這樣做可以讓 SQL 應用程式在重新整理具體化檢視時讀取具體化檢視。
監控 Aurora Machine Learning
您可以將自訂資料庫叢集參數群組中的 track_functions 參數設定為 all 來監控 aws_ml 函數。根據預設,此參數會設定為 pl,表示只會追蹤程序語言函數。藉由將其變更為 all,也會追蹤 aws_ml 函數。如需詳細資訊,請參閱 PostgreSQL 文件中的執行時間統計資料
如需資訊,了解如何監控從 Aurora 機器學習函數呼叫之 SageMaker AI 操作的效能,請參閱《Amazon SageMaker AI 開發人員指南》中的監控 Amazon SageMaker AI。
將 track_functions 設為 all 後,您可以查詢 pg_stat_user_functions 檢視,以取得有關您定義並用來叫用 Aurora Machine Learning 服務之函數的統計資料。對於每個函數,檢視會提供 calls、total_time 和 self_time 的數目。
若要檢視 aws_sagemaker.invoke_endpoint 和 aws_comprehend.detect_sentiment 函數的統計資料,您可以使用下列查詢依結構描述名稱篩選結果。
SELECT * FROM pg_stat_user_functions WHERE schemaname LIKE 'aws_%';
若要清除統計資料,請執行以下操作。
SELECT pg_stat_reset();
您可以查詢 PostgreSQL pg_proc 系統目錄,取得呼叫 aws_sagemaker.invoke_endpoint 函數的 SQL 函數名稱。此目錄存放函數、程序等的相關資訊。如需詳細資訊,請參閱 PostgreSQL 文件中的 pg_procproname) 的名稱,這些名稱的來源 (prosrc) 包括文字 invoke_endpoint。
SELECT proname FROM pg_proc WHERE prosrc LIKE '%invoke_endpoint%';
