本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 DynamoDB 中查詢與掃描資料的最佳實務
本節會介紹在 Amazon DynamoDB 中使用 Query 和 Scan 操作的一些最佳實務。
掃描的效能考量
一般而言,Scan 操作效率低於 DynamoDB 中的其他操作。Scan 操作會一律掃描整個資料表或次要索引。然後它會篩選數值來提供您想要的結果,基本上增加了從結果集刪除資料的額外步驟。
如果可行,您應該避免在大型資料表上或能移除許多結果的篩選條件上使用 Scan 操作。此外,隨著資料表或索引的增長,Scan 操作會變慢。所以此 Scan 操作會檢查每個項目的請求數值,並且可能會在單一操作中耗用大型資料表或索引的佈建輸送量。為了能擁有更快的回應時間,請設計資料表和索引,讓您的應用程式可以使用 Query 而非 Scan。(對於資料表,您也可以考慮使用 GetItem 和 BatchGetItem API。)
您也可以設計應用程式來使用 Scan 操作,最大限度地減少對請求率的影響。這可能包括比起 Scan 操作,使用全域次要索引更有效率的建模。有關此流程的更多資訊,請參閱以下影片。
避免讀取活動突發尖峰
建立資料表時,您可以設定其讀取和寫入容量單位需求。針對讀取,容量單位會以每秒強烈一致的 4 KB 資料讀取請求數來表示。對於最終一致讀取,讀取容量單位為每秒兩個 4 KB 讀取請求。Scan 操作預設會執行最終一致讀取,而且最多可傳回 1 MB (一頁) 的資料。因此,單一 Scan 請求可能會消耗 (1 MB 頁面大小/4 KB 項目大小)/2 (最終一致讀取) = 128 個讀取操作。相對地,如果您請求高度一致性讀取,則 Scan 操作會耗用兩倍的佈建輸送量:256 個讀取操作。
與資料表設定的讀取容量相比,這代表在使用時突發尖峰。此掃描使用容量單位可防止同一資料表的其他可能更重要的請求使用可用容量單位。因此對於那些請求,您可能會得到一個 ProvisionedThroughputExceeded 例外狀況。
問題不僅僅是 Scan 使用的容量單位突然增加。掃描也可能會耗用相同分割區的所有容量單位,因為掃描會請求讀取該分割區上彼此相鄰的項目。這表示請求會落在相同的分割區上,造成其所有容量單位被消耗,並限流對該分割區的其他請求。如果讀取資料的請求分散在多個分割區,則操作不會限流特定的分割區。
下圖說明 Query 和 Scan 操作的容量單位使用量激增的影響,以及其對同一資料表的其他請求的影響。
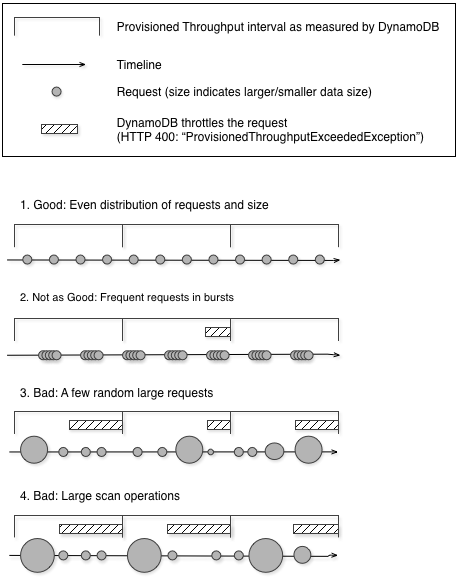
如此處所示,使用量激增會以數種方式影響資料表的佈建輸送量:
-
良好:請求和大小分配均勻
-
不太好:頻繁的突發請求
-
不良:幾個隨機的大型請求
-
不良:大型掃瞄操作
除了使用大型 Scan 操作,您可以使用下列技巧,將該操作對資料表佈建輸送量的影響降至最低。
-
縮減頁面大小
由於掃描操作會讀取整個頁面 (預設為 1 MB),您可以設定較小的頁面大小來降低掃描操作的影響。
Scan操作提供了 Limit 參數,可讓您用來設定請求的頁面大小。每個擁有較小頁面大小的Query或Scan請求都會使用較少的讀取操作,並會在各請求之間建立「暫停」。例如,假設每個項目是 4 KB,而且您將頁面大小設定為 40 個項目。Query請求將僅消耗 20 個最終一致讀取操作或 40 個高度一致性讀取操作。較大數量的較小Query或Scan操作會允許您的其他關鍵請求在不受限流的情況下成功進行。 -
隔離掃描操作
DynamoDB 旨在輕鬆實現可擴展性。因此,應用程式可以為不同的目的建立資料表,甚至可能會跨多個資料表複製內容。您想要在未採用「任務關鍵型」流量的資料表上執行掃描。某些應用程式處理此負載的方式為每小時在兩個資料表 (一個用於關鍵流量,另一個則用於簿記) 之間輪換流量。其他應用程式可以透過在兩個資料表 (「任務關鍵型」和「陰影」資料表) 上執行每次寫入來處理負載。
將您的應用程式設定為重試接收表示您已超過佈建輸送量的回應代碼的任何請求。您也可以使用 UpdateTable 操作為資料表增加佈建的輸送量。如果工作負載有暫時的激增,導致輸送量偶爾超出佈建層級,則使用指數退避重試請求。如需實作指數退避的詳細資訊,請參閱 錯誤重試和指數退避。
利用平行掃描
許多應用程式可以從使用平行 Scan 操作而非循序掃描中獲益。例如,處理大型歷史資料表的應用程式,執行平行掃描的速度會比循序掃描的速度要快得多。背景「掃描程式」程序中的多個工作者執行緒,可以低優先順序掃描資料表,而不會影響生產流量。在每個這些例子中,平行 Scan 的使用方式使其不會剝奪佈建輸送量資源的其他應用程式。
雖然平行掃描可能很有幫助,但它們可能會對佈建輸送量造成大量需求。使用平行掃描時,您的應用程式有多個工作者都在同時執行 Scan 操作。這會快速消耗資料表的佈建讀取容量。在這種情況下,其他需要存取資料表的應用程式可能會受到限流。
如果符合下列條件,則平行掃描會是正確的選擇:
資料表大小為 20 GB 或更大。
該資料表的佈建讀取輸送量尚未完全使用。
循序
Scan操作太慢。
選擇 TotalSegments
TotalSegments 的最佳設定取決於您的特定資料、資料表的佈建輸送量設定以及您的效能需求。您可能需要進行實驗,才能正確設定。我們建議您從簡單的比率開始,例如每 2 GB 資料一個區段。例如,對於 30 GB 的資料表,您可以設定 TotalSegments 為 15 個區段 (30 GB/2 GB)。您的應用程式將使用 15 個工作者,每個工作者掃描不同的區段。
您也可以根據用戶端資源為 TotalSegments 選擇一個數值。您可以將 TotalSegments 設定為 1 到 1000000 之間的任何數字,而 DynamoDB 則可讓您掃描該數目的區段。例如,如果用戶端限制可以同時運行的執行緒數量,您就可以逐漸增加 TotalSegments,直到應用程式得到最佳 Scan 效能。
監控平行掃描以最佳化佈建輸送量的使用,同時確保其他應用程式不會耗盡資源。如果您沒有消耗所有佈建的輸送量,但仍然在 Scan 請求中經歷限流,則增加 TotalSegments 的數值。如果 Scan 請求所耗用的佈建輸送量超過您想使用的量,則減少 TotalSegments 的數值。
