本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
檢視反應異常
在深入分析中,您可以檢視 Amazon RDS 資源的異常情況。在反應式分析頁面的「彙總量度」區段中,您可以檢視具有對應時間表的異常清單。還有一些區段會顯示與異常相關的記錄群組和事件的相關資訊。反應洞察中的因果異常,每個都有一個對應的頁面,其中包含有關異常的詳細信息。
檢視 RDS 反應異常的詳細分析
在此階段,請向下鑽研異常情況,以取得適用於 Amazon RDS 資料庫執行個體的詳細分析和建議。
詳細分析僅適用於已開啟 Performance Insights 的 Amazon RDS 資料庫執行個體。
若要向下鑽研至異常詳細資訊頁面
-
在深入解析頁面上,尋找具有資源類型 AWS/ RDS 的彙總指標。
-
請選擇 View Details (查看詳細資訊)。
「異常詳細資訊」頁面隨即出現。標題以資料庫效能異常開頭,並顯示資源的名稱。無論何時發生異常,控制台都預設為嚴重性最高的異常。
-
(選擇性) 如果有多個資源受到影響,請從頁面頂端的清單中選擇不同的資源。
接下來,您可以找到詳細資訊頁面元件的說明。
資源概觀
詳細資訊頁面的頂端區段是資源概觀。本節概述 Amazon RDS 資料庫執行個體所經歷的效能異常情況。
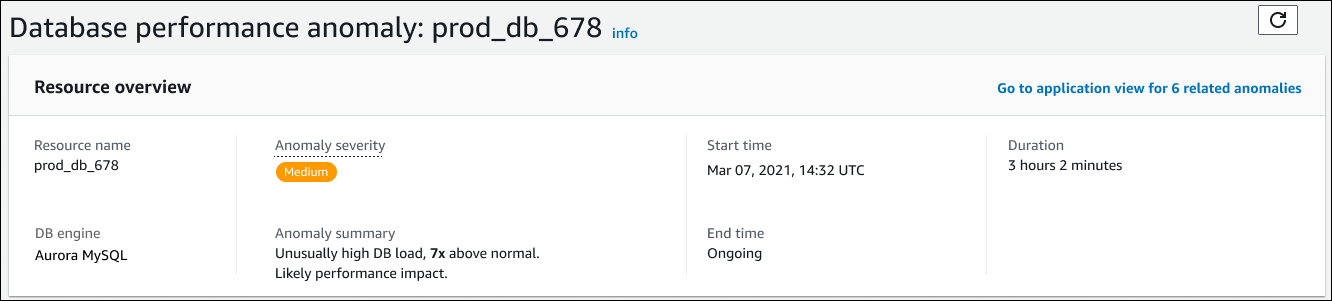
此區段包含下列欄位:
-
資源名稱 — 發生異常的資料庫執行個體名稱。在此範例中,資源的名稱為
-
資料庫引擎 — 發生異常的資料庫執行個體名稱。在這個例子中,引擎是 Aurora MySQL。
-
異常嚴重性 — 異常對執行個體造成負面影響的衡量方式。可能的嚴重性為「高」、「中」和「低」。
-
異常摘要 — 問題的簡短摘要。典型的摘要是非常高的 DB 負載。
-
開始時間和結束時間 — 異常開始和結束的時間。如果結束時間是持續的,則異常仍在發生。
-
持續時間 — 異常行為的持續時間。在此範例中,異常狀況正在進行,並且已經發生了 3 小時又 2 分鐘。
主要量度
「主要量度」區段會摘要顯示偶然異常,也就是深入解析中的最上層異常。您可以將因果異常視為資料庫執行個體所遇到的一般問題。
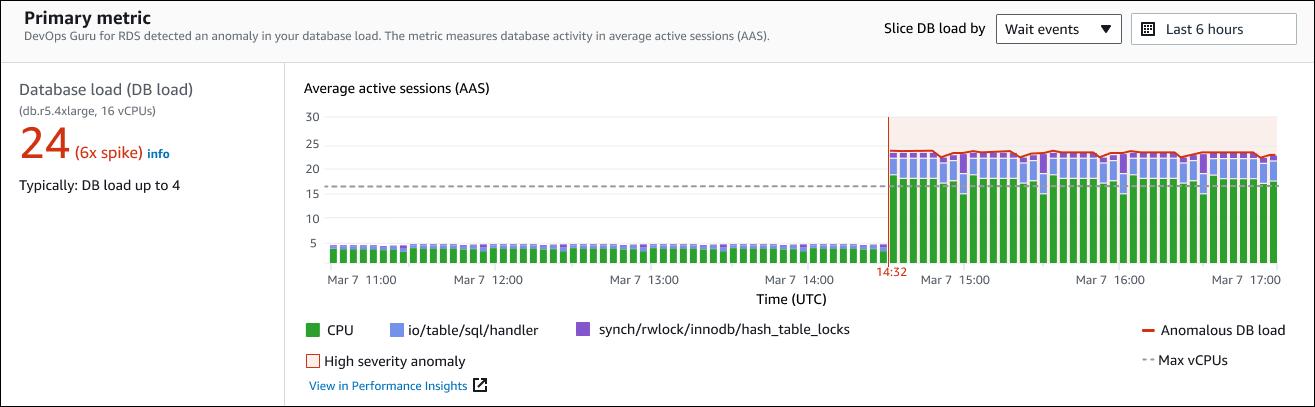
左側面板提供有關此問題的更多詳細資訊。在此範例中,摘要包括下列資訊:
-
資料庫負載 (DB 載入) — 將異常分類為資料庫載入問題。「Performance Insights」中的對應度量為
DBLoad。此指標也會發佈至 Amazon CloudWatch。 -
資料庫執行個體類別 — 資料庫執行個體類別。此範例中的 vCPUs 數目為 16,對應於「平均作用中階段作業 (AAS)」圖表中的虛線。
-
24 (6 倍尖峰) — 資料庫負載,以洞察報告的時間間隔內的平均作用中工作階段 (AAS) 來測量。因此,在異常期間的任何指定時間,資料庫上平均有 24 個工作階段處於作用中狀態。資料庫負載是此執行個體一般資料庫負載的 6 倍。
-
通常:資料庫負載最多 4 — 在一般工作負載期間,資料庫負載的基準線 (以 AAS 測量)。值 4 表示在一般作業期間,資料庫在任何指定時間平均有 4 個或更少的作業階段作用中。
根據預設,負載圖表會由等待事件切割。這表示對於圖表中的每個長條,最大的彩色區域代表對總資料庫負載最大貢獻的等待事件。此圖表顯示問題開始的時間 (以紅色顯示)。將注意力集中在佔用欄中最多空間的等待事件上:
-
CPU -
IO:wait/io/sql/table/handler
對於此 Aurora MySQL 資料庫,先前的等待事件顯示得超過正常情況。若要了解如何使用 Amazon Aurora 中的等待事件調整效能,請參閱亞馬 Amazon Aurora Aurora 使用者指南中的使用等待事件進行調整以及使用 Aurora Postgre SQL MySQL 的等待事件進行調整。若要了解如何使用 RDS 版 PostgreSQL 中的等待事件調整效能,請參閱 Amazon RDS 使用者指南中的使用等待事件進行調整。
相關指標
「相關量度」區段會列出上下文異常,這些異常是因果異常中的特定發現項目。這些發現項目提供有關效能問題的其他資訊。
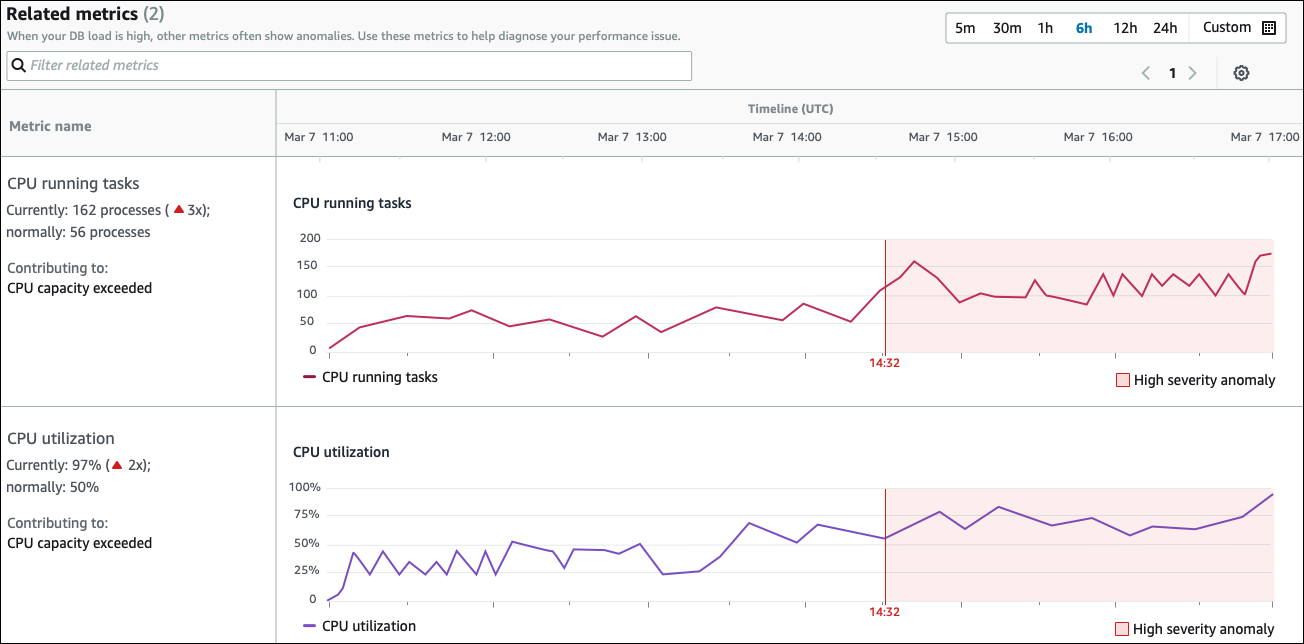
「相關測量結果」表格有兩個資料欄:測量結果名稱和時間軸 (UTC)。表格中的每一列都對應一個特定的量度。
每一列的第一欄包含下列資訊:
-
名稱— 測量結果的名稱。第一列會將測量結果識別為 CPU 執行中的作業。 -
目前 — 測量結果的目前值。在第一行中,當前值為 162 進程(3x)。
-
一般 — 此資料庫正常運作時,此測量結果的基準線。 DevOpsRDS 的大師將基準計算為歷史記錄的第 95 個百分位數值。第一列表示 56 個處理序通常在 CPU 上執行。
-
貢獻給 — 與此測量結果相關聯的發現項目。在第一列中,CPU 執行中的工作量度與超過異常的 CPU 容量相關聯。
「時間軸」欄會顯示量度的折線圖。陰影區域會顯示當 DevOps Guru for RDS 將發現項目指定為高嚴重性時的時間間隔。
分析和建議
因果異常描述了整體問題,上下文異常描述了需要調查的特定發現。每個發現項目都會對應至一組相關量度。
在下列 [分析和建議] 區段的範例中,高資料庫負載異常有兩個發現項目。
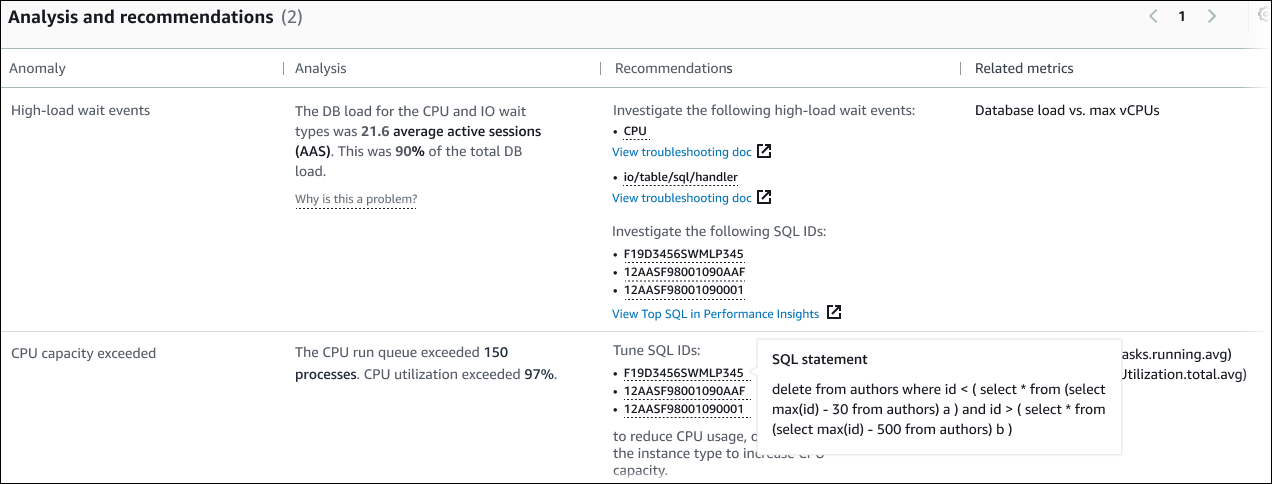
資料表包含以下資料行:
-
異常 — 此上下文異常的一般描述。在此範例中,第一個異常是高負載等待事件,第二個是超過 CPU 容量。
-
分析 — 異常情況的詳細說明。
在第一個異常情況中,三種等待類型有助於 90% 的 DB 負載。在第二個異常情況下,CPU 執行佇列超過 150,這表示在任何指定時間,超過 150 個工作階段正在等待 CPU 時間。CPU 使用率超過 97%,這意味著在問題發生期間,CPU 忙碌了 97% 的時間。因此,CPU 幾乎持續佔用,而平均 150 個工作階段等待在 CPU 上執行。
-
建議 — 建議的使用者對異常的回應。
在第一個異常情況下,RDS 的 DevOps Guru 建議您調查等待事件
cpu和io/table/sql/handler. 若要了解如何根據這些事件調整資料庫效能,請參閱 Amazon Aurora 使用者指南中的 CPU 和 io/表格/sql/處理程式。在第二個異常狀況中,RDS DevOps 專用的 Guru 建議您調整三個 SQL 敘述句,以減少 CPU 耗用量。您可以將鼠標懸停在鏈接上以查看 SQL 文本。
-
相關指標 — 為您提供異常特定測量值的指標。如需有關這些指標的詳細資訊,請參閱 Amazon Aurora 使用者指南中的 Amazon Aurora 指標參考或 Amazon RDS 使用者指南中的 Amazon RDS 指標參考。
在第一個異常狀況中,RDS 的 DevOps Guru 建議將資料庫負載與執行個體的最大 CPU 進行比較。在第二個異常情況下,建議查看 CPU 執行佇列、CPU 使用率和 SQL 執行速率。
