本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon DocumentDB 彈性叢集:運作方式
本節中的主題提供有關為 Amazon DocumentDB 彈性叢集提供支援的機制和功能的資訊。
Amazon DocumentDB 彈性叢集碎片
Amazon DocumentDB 彈性叢集使用雜湊式碎片,跨分散式儲存系統分割資料。碎片也稱為分割,可將大型資料集分割為跨多個節點的小型資料集,讓您將資料庫擴展到超過垂直擴展限制的範圍。彈性叢集使用 Amazon DocumentDB 中運算和儲存的分離或解耦,可讓您獨立擴展。彈性叢集不會透過在運算節點之間移動少量資料來重新分割集合,而是在分散式儲存系統中有效率地複製資料。

碎片定義
碎片命名法的定義:
碎片 — 碎片提供彈性叢集的運算。它將有一個寫入器執行個體和 0–15 個僅供讀取複本。根據預設,碎片將有兩個執行個體:寫入器和單一僅供讀取複本。您最多可以設定 32 個碎片,每個碎片執行個體最多可以有 64 vCPUs。
碎片索引鍵 — 碎片索引鍵是 JSON 文件中碎片集合的必要欄位,彈性叢集會用來將讀取和寫入流量分散至相符的碎片。
碎片集合 — 碎片集合是一種集合,其資料分散在資料分割區中的彈性叢集。
分割區 — 分割區是碎片資料的邏輯部分。當您建立碎片集合時,資料會根據碎片金鑰自動組織成每個碎片內的分割區。每個碎片都有多個分割區。
在設定的碎片之間分配資料
建立具有許多唯一值的碎片金鑰。良好的碎片金鑰會將資料平均分割到基礎碎片,為您的工作負載提供最佳輸送量和效能。下列範例是使用名為 "user_id" 之碎片索引鍵的員工名稱資料:
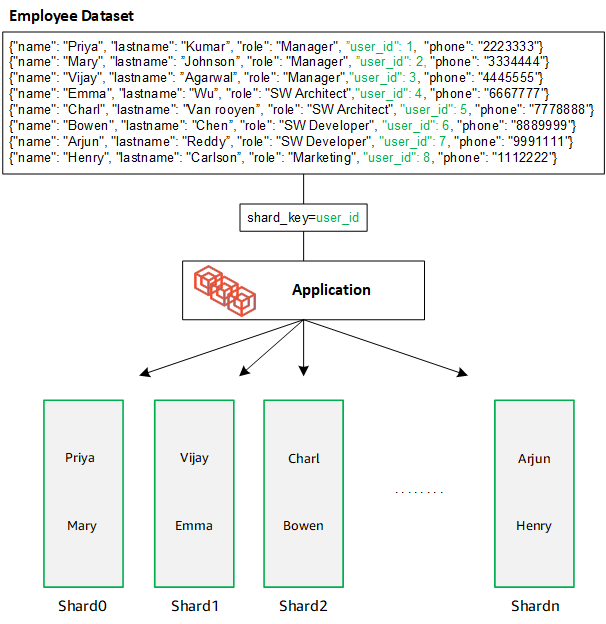
DocumentDB 使用雜湊碎片將資料分割到基礎碎片。插入和分發額外資料的方式相同:
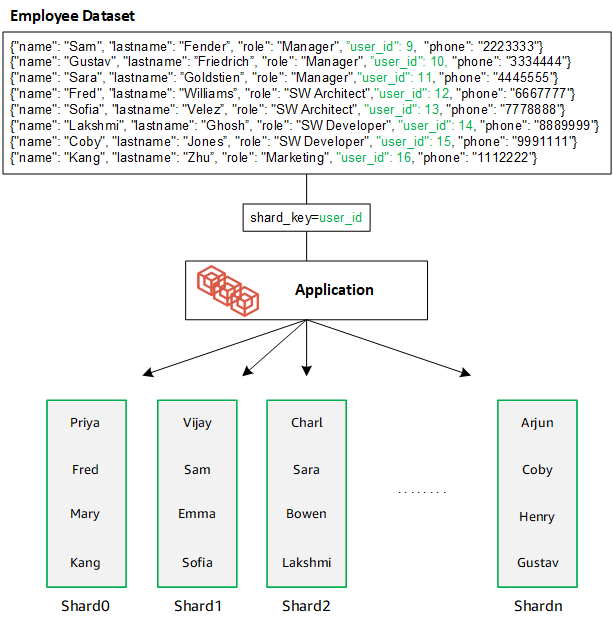
當您透過新增其他碎片來擴展資料庫時,Amazon DocumentDB 會自動重新分配資料:

彈性叢集遷移
Amazon DocumentDB 支援將 MongoDB 碎片資料遷移至彈性叢集。支援離線、線上和混合遷移方法。如需詳細資訊,請參閱遷移至 Amazon DocumentDB。
彈性叢集擴展
Amazon DocumentDB 彈性叢集可讓您增加彈性叢集中的碎片數量 (向外擴展),以及套用至每個碎片的 vCPUs 數量 (向上擴展)。您也可以視需要減少碎片和運算容量 (vCPUs的數量。
如需擴展最佳實務,請參閱 擴展彈性叢集。
注意
也可使用叢集層級擴展。如需詳細資訊,請參閱擴展 Amazon DocumentDB 叢集。
彈性叢集可靠性
Amazon DocumentDB 的設計可靠、耐用且容錯。為了改善可用性,彈性叢集會在不同可用區域的每個碎片部署兩個節點。Amazon DocumentDB 包含數個自動功能,使其成為可靠的資料庫解決方案。如需詳細資訊,請參閱Amazon DocumentDB 可靠性。
彈性叢集儲存和可用性
Amazon DocumentDB 資料存放在叢集磁碟區中,這是使用固態硬碟 (SSDs的單一虛擬磁碟區。叢集磁碟區包含資料的六個副本,這些副本會自動複寫到單一 AWS 區域中的多個可用區域。此複寫有助於確保您的資料具有高耐用性,同時降低資料遺失的機率。它也有助於確保您的叢集在容錯移轉時提供更高的可用性,因為資料副本已存在於其他可用區域。如需儲存、高可用性和複寫的詳細資訊,請參閱Amazon DocumentDB:運作方式。
Amazon DocumentDB 4.0 和彈性叢集之間的功能差異
Amazon DocumentDB 4.0 和彈性叢集之間存在下列功能差異。
來自
top和 的結果collStats會依碎片分割。對於碎片集合,資料會分散在多個分割區中collScans,並從分割區彙總collStats的報告。叢集
collStats碎片計數變更時,會重設碎片集合的top和 集合統計資料。備份內建角色現在支援
serverStatus。動作 - 具有備份角色的開發人員和應用程式可以收集有關 Amazon DocumentDB 叢集狀態的統計資料。SecondaryDelaySecs欄位會在replSetGetConfig輸出slaveDelay中取代 。hello命令會取代isMaster-hello傳回描述彈性叢集角色的文件。彈性叢集中的
$elemMatch運算子僅符合陣列的第一個巢狀層級中的文件。在 Amazon DocumentDB 4.0 中,運算子會先周遊所有層級,再傳回相符的文件。例如:
db.foo.insert( [ {a: {b: 5}}, {a: {b: [5]}}, {a: {b: [3, 7]}}, {a: [{b: 5}]}, {a: [{b: 3}, {b: 7}]}, {a: [{b: [5]}]}, {a: [{b: [3, 7]}]}, {a: [[{b: 5}]]}, {a: [[{b: 3}, {b: 7}]]}, {a: [[{b: [5]}]]}, {a: [[{b: [3, 7]}]]} ]); // Elastic clusters > db.foo.find({a: {$elemMatch: {b: {$elemMatch: {$lt: 6, $gt: 4}}}}}, {_id: 0}) { "a" : [ { "b" : [ 5 ] } ] } // Docdb 4.0: traverse more than one level deep > db.foo.find({a: {$elemMatch: {b: {$elemMatch: {$lt: 6, $gt: 4}}}}}, {_id: 0}) { "a" : [ { "b" : [ 5 ] } ] } { "a" : [ [ { "b" : [ 5 ] } ] ] }
Amazon DocumentDB 4.0 中的「$」投影會傳回包含所有欄位的所有文件。使用彈性叢集時,具有「$」投影的
find命令會傳回符合查詢參數的文件,只包含符合「$」投影的欄位。在彈性叢集中,具有
$regex和$options查詢參數的find命令會傳回錯誤:「無法在 $regex 和 $options 中設定選項」。
使用彈性叢集時,
$indexOfCP現在會在下列情況下傳回 "-1":在 中找不到 子字串
string expression,或start是大於 的數字end,或start是大於字串位元組長度的數字。
在 Amazon DocumentDB 4.0 中,當
start位置的數字大於end或字串的位元組長度時, 會$indexOfCP傳回 "0"。使用彈性叢集時, 中的投影操作
_id fields,例如{"_id.nestedField" : 1},會傳回僅包含投影欄位的文件。同時,在 Amazon DocumentDB 4.0 中,巢狀欄位投影命令不會篩選掉任何文件。
