本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon DocumentDB:運作方式
Amazon DocumentDB (與 MongoDB 相容) 是全受管、與 MongoDB 相容的資料庫服務。透過 Amazon DocumentDB,您可以執行相同的應用程式程式碼,並使用與 MongoDB 搭配使用的相同驅動程式和工具。Amazon DocumentDB 與 MongoDB 3.6、4.0、5.0 和 8.0 相容。
主題
Amazon DocumentDB 版本
注意
次要版本編號適用於 Amazon DocumentDB 5.0 及更新版本。Amazon DocumentDB 3.6 和 4.0 僅使用具有引擎修補程式的主要版本。
從 Amazon DocumentDB 5.0 開始,引擎版本使用四層編號機制: major.major.minor.patch。
-
主要版本 - 由版本的前兩個號碼識別 (例如 5.0)。主要版本代表 MongoDB 相容性層級。主要版本推出新功能、效能改善和 MongoDB 相容性更新。在主要版本 (例如,從 4.0 升級至 5.0) 之間升級需要主要版本升級 (MVU)。如需詳細資訊,請參閱Amazon DocumentDB 就地主要版本升級。
-
次要版本 - 以版本的第三個號碼識別 (例如 5.0.1
1中的 )。次要版本包括改善,例如相同主要版本中的新功能、安全性修正和錯誤修正。您可以手動升級至新的次要版本。如需詳細資訊,請參閱Amazon DocumentDB 次要版本升級。 -
修補程式版本 - 引擎修補程式會在次要版本中套用,並包含重要的安全性修正和錯誤修正。修補程式版本由引擎修補程式版本 (例如
3.0.17983) 追蹤,您可以透過執行 來檢查db.runCommand({getEngineVersion: 1})。修補程式會在叢集的維護時段套用。如需詳細資訊,請參閱維護 Amazon DocumentDB。
建立新叢集時,您可以指定任何可用的引擎版本。如需可用版本和支援日期的相關資訊,請參閱 Amazon DocumentDB 引擎版本支援日期。
當您使用 Amazon DocumentDB 時,請先建立叢集。資料庫叢集包含零或多個資料庫執行個體,和一個管理這些執行個體資料的叢集磁碟區。Amazon DocumentDB 叢集磁碟 區是跨越多個可用區域的虛擬資料庫儲存磁碟區。每個可用區域具有叢集資料的複本。
Amazon DocumentDB 叢集包含兩個元件:
-
叢集磁碟區 - 使用雲端原生儲存服務跨三個可用區域以六種方式複寫資料,提供高耐用性和可用的儲存。Amazon DocumentDB 叢集只有一個叢集磁碟區,最多可存放 128 TiB 的資料。
-
執行個體 - 提供資料庫的處理能力、將資料寫入叢集儲存磁碟區,以及從中讀取資料。Amazon DocumentDB 叢集可以有 0–16 個執行個體。
執行個體提供以下兩種角色:
-
主要執行個體 - 支援讀取和寫入操作,並對叢集磁碟區執行所有資料修改。每個 Amazon DocumentDB 叢集都有一個主要執行個體。
-
複本執行個體 - 僅支援讀取操作。除了主要執行個體之外,Amazon DocumentDB 叢集最多可以有 15 個複本。擁有多個複本可讓您分配讀取工作負載。此外,透過將複本置於不同可用區域,您也可提高叢集可用性。
下圖說明 Amazon DocumentDB 叢集中叢集磁碟區、主要執行個體和複本之間的關係:
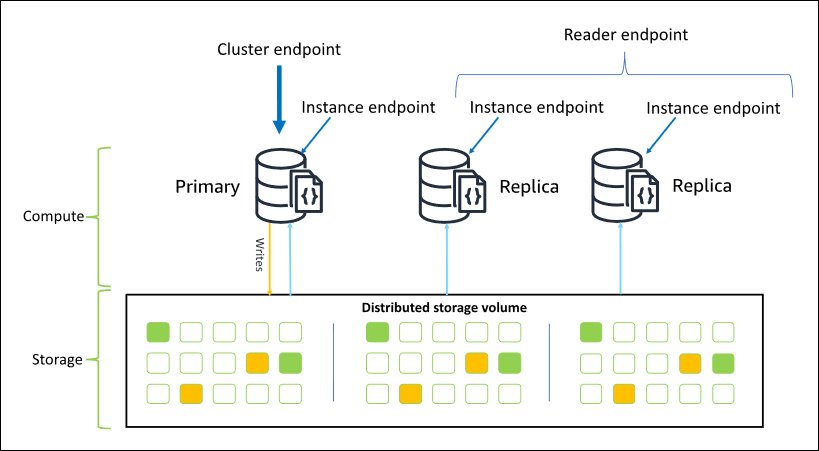
叢集執行個體不需為相同執行個體類別,而您可以隨需要佈建和終止它們。這個架構可讓您擴展叢集的運算容量,而不影響儲存。
當您的應用程式會將資料寫入主執行個體,主執行個體會將耐用資料寫入叢集磁碟區。然後,它會將該寫入的狀態 (而非資料) 複寫到每個作用中的複本。Amazon DocumentDB 複本不參與處理寫入,因此 Amazon DocumentDB 複本有利於讀取擴展。Amazon DocumentDB 複本的讀取最終會與最小複本延遲一致,通常在主要執行個體寫入資料後不到 100 毫秒。從複本的讀取保證會以複本寫入主要執行個體的順序來進行讀取。複本延遲取決於資料變更的速率,以及高寫入活動的期間可能會增加複本延遲。如需詳細資訊,請參閱 Amazon DocumentDB 指標 的 ReplicationLag 指標。
Amazon DocumentDB 端點
Amazon DocumentDB 提供多種連線選項,可處理各種使用案例。若要連線至 Amazon DocumentDB 叢集中的執行個體,請指定執行個體的端點。端點是主機地址和連接埠號碼 (以冒號分隔)。
除非您有連線至讀取器端點或執行個體端點的特定使用案例,否則我們建議使用叢集端點並在複本集模式下 (請參閱 以複本集的形式連線至 Amazon DocumentDB) 連線至叢集。若要將請求路由到您的複本,請選擇驅動程式讀取偏好設定,以發揮最大讀取擴展,同時符合您應用程式的讀取一致性要求。secondaryPreferred 讀取偏好設定會啟用複本讀取,並釋出主要執行個體以進行更多工作。
下列端點可從 Amazon DocumentDB 叢集取得。
叢集端點
叢集端點會連接至叢集目前的主要執行個體。您可以使用叢集端點來執行讀取和寫入操作。Amazon DocumentDB 叢集只有一個叢集端點。
叢集端點可為叢集的讀寫連接提供容錯移轉支援。如果叢集目前的主要執行個體發生故障,您的叢集至少有一個作用中的僅供讀取複本,叢集端點會自動重新導向到新主要執行個體的連線請求。連線至 Amazon DocumentDB 叢集時,建議您使用叢集端點並以複本集模式連線至叢集 (請參閱 以複本集的形式連線至 Amazon DocumentDB)。
以下是 Amazon DocumentDB 叢集端點的範例:
sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
以下是使用此叢集端點的範例連線字串:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
如需尋找叢集端點的詳細資訊,請參閱尋找叢集的端點。
讀取器端點
讀取器端點負載會平衡在叢集中所有可用複本的僅供讀取連線。如果您是透過 replicaSet 模式連線,則叢集讀取器端點將做為叢集端點執行,這表示在連線字串中,複本集參數為 &replicaSet=rs0。在這種情況下,您將能夠在主要 上執行寫入操作。不過,如果您連線到指定 的叢集directConnection=true,則嘗試透過與讀取器端點的連線執行寫入操作會導致錯誤。Amazon DocumentDB 叢集只有一個讀取器端點。
如果叢集僅包含一個 (主要) 執行個體,讀取器端點會連接至主要執行個體。當您將複本執行個體新增至 Amazon DocumentDB 叢集時,讀取器端點會在新複本處於作用中狀態後開啟其唯讀連線。
以下是 Amazon DocumentDB 叢集的範例讀取器端點:
sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
以下是使用此讀取器端點的範例連線字串:
mongodb://username:password@sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
讀取器端點負載會平衡唯讀連線,而不是讀取請求。如果一些讀取器端點連線的使用量較其他連線頻繁,則系統可能無法在叢集中的執行個體間平均地平衡讀取請求。建議連線至做為複本集的叢集端點,並利用 secondaryPreferred 讀取偏好設定選項,來發佈請求。
如需尋找叢集端點的詳細資訊,請參閱尋找叢集的端點。
執行個體端點
執行個體端點會連線到叢集中的特定執行個體。您可以將目前主要執行個體的執行個體端點用於讀取和寫入操作。不過,嘗試對執行個體端點執行讀取複本的寫入操作可能會造成錯誤。Amazon DocumentDB 叢集每個作用中執行個體都有一個執行個體端點。
執行個體端點對特定執行個體的連接提供直接控制,使用叢集端點或讀取器端點的案例可能不適用。範例使用案例佈建的是適用於週期性唯讀分析工作負載。您可以佈建大於一般的複本執行個體、使用其執行個體端點直接連接到新的大型執行個體、執行分析查詢,接著終止執行個體。使用執行個體端點可讓分析流量不會影響到其他叢集執行個體。
以下是 Amazon DocumentDB 叢集中單一執行個體的範例執行個體端點:
sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
以下是使用此執行個體端點的範例連線字串:
mongodb://username:password@sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
注意
做為主要或複本的執行個體角色可以因為容錯移轉事件而變更。應用程式絕不應該假設特定執行個體端點是主執行個體。我們不建議連線至生產應用程式的執行個體端點。我們建議您改為使用叢集端點並在複本集模式下 (請參閱 以複本集的形式連線至 Amazon DocumentDB) 連接至您的叢集。如需執行個體容錯移轉優先順序更進階的控制,請參閱了解 Amazon DocumentDB 叢集容錯能力。
如需尋找叢集端點的詳細資訊,請參閱尋找執行個體的端點。
複本集模式
您可以指定複本集名稱 ,以複本集模式連線至 Amazon DocumentDB 叢集端點rs0。在複本集模式中連接可讓您指定 Read Concern、Write Concern 和 Read Preference 選項。如需詳細資訊,請參閱讀取一致性。
以下是在複本集模式中連接的範例連線字串:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0
當您以複本集模式連線時,Amazon DocumentDB 叢集會以複本集的形式向驅動程式和用戶端顯示。從 Amazon DocumentDB 叢集新增和移除的執行個體會自動反映在複本集組態中。
每個 Amazon DocumentDB 叢集都包含具有預設名稱 的單一複本集rs0。複本集名稱無法修改。
若是一般用途,建議連接到在複本集模式中的叢集端點。
注意
Amazon DocumentDB 叢集中的所有執行個體都會接聽相同的 TCP 連接埠以進行連線。
TLS 支援
如需使用 Transport Layer Security (TLS) 連線至 Amazon DocumentDB 的詳細資訊,請參閱 加密傳輸中的資料。
Amazon DocumentDB 儲存體
Amazon DocumentDB 資料存放在叢集磁碟區中,這是使用固態硬碟 (SSDs的單一虛擬磁碟區。叢集磁碟區包含資料的六個副本,這些副本會在單一可用區域中自動複寫 AWS 區域。此複寫有助於確保您的資料具有高耐用性,同時降低資料遺失的機率。它也有助於確保您的叢集在容錯移轉時提供更高的可用性,因為資料副本已存在於其他可用區域。這些副本可以繼續將資料請求提供給 Amazon DocumentDB 叢集中的執行個體。
資料儲存體的計費方式
隨著資料量增加,Amazon DocumentDB 會自動增加叢集磁碟區的大小。Amazon DocumentDB 叢集磁碟區的大小上限為 128 TiB;不過,您只需支付您在 Amazon DocumentDB 叢集磁碟區中使用的空間費用。從 Amazon DocumentDB 4.0 開始,移除資料時,例如捨棄集合或索引,整體配置的空間會減少相當的數量。因此,您可以透過刪除不再需要的集合、索引和資料庫來降低儲存費用。在 Amazon DocumentDB 3.6 版中,叢集磁碟區可以重複使用移除資料時釋放的空間,但磁碟區本身的大小永遠不會減少。由於使用 3.6 版,即使您捨棄集合或索引,即使已釋放的空間已重複使用,您也可能不會目擊儲存體中的任何變更。
注意
使用 Amazon DocumentDB 3.6 時,儲存成本是根據儲存體「高浮水印」(任何時間點為 Amazon DocumentDB 叢集配置的最大數量)。您可以透過避免建立大量臨時資訊的 ETL 實務,或在移除不需要的舊資料之前載入大量新資料來管理成本。如果從 Amazon DocumentDB 叢集移除資料會產生大量配置但未使用的空間,則重設高浮水印需要執行邏輯資料傾印,並使用 mongodump或 等工具還原至新叢集mongorestore。建立和還原快照不會減少配置的儲存空間,因為基礎儲存的實體配置在還原的快照中保持不變。
注意
使用 mongodump 和 mongorestore 之類的公用程式會根據所讀取和寫入儲存磁碟區的資料大小產生 I/O 費用。
如需 Amazon DocumentDB 資料儲存和 I/O 定價的相關資訊,請參閱 Amazon DocumentDB (具有 MongoDB 相容性) 定價
Amazon DocumentDB 複寫
在 Amazon DocumentDB 叢集中,每個複本執行個體都會公開獨立端點。這些複本端點對叢集磁碟區的資料提供唯讀存取權。它們可讓您隨著多個複寫執行個體擴展資料的讀取工作負載。它們也有助於改善資料讀取的效能,並提高 Amazon DocumentDB 叢集中資料的可用性。Amazon DocumentDB 複本也是容錯移轉目標,如果 Amazon DocumentDB 叢集的主要執行個體失敗,則會快速提升複本。
Amazon DocumentDB 可靠性
Amazon DocumentDB 的設計可靠、耐用且容錯。(為了改善可用性,您應該設定 Amazon DocumentDB 叢集,以便在不同的可用區域中擁有多個複本執行個體。) Amazon DocumentDB 包含數個自動功能,使其成為可靠的資料庫解決方案。
儲存體自動修復
Amazon DocumentDB 會在三個可用區域中維護資料的多個副本,大幅降低因儲存故障而遺失資料的機會。Amazon DocumentDB 會自動偵測叢集磁碟區中的失敗。當叢集磁碟區的區段失敗時,Amazon DocumentDB 會立即修復該區段。它會使用叢集磁碟區組成之其他磁碟區中的資料,以協助確保中修復區段的資料是最新的。因此,Amazon DocumentDB 可避免資料遺失,並減少執行point-in-time還原以從執行個體故障中復原的需求。
可存活的快取預備
Amazon DocumentDB 會在與資料庫不同的程序中管理其頁面快取,以便頁面快取可以獨立於資料庫。在極少的情況下,若資料庫發生故障,頁面快取仍會留在記憶體中。這可確保在資料庫重新啟動時緩衝集區仍是最新狀態。
損毀復原
Amazon DocumentDB 旨在從損毀中幾乎立即復原,並繼續提供應用程式資料。Amazon DocumentDB 會在平行執行緒上以非同步方式執行當機復原,讓您的資料庫在當機後幾乎可立即開啟和使用。
資源控管
Amazon DocumentDB 會保護在服務中執行關鍵程序所需的資源,例如運作狀態檢查。為此,當執行個體遇到高記憶體壓力時,Amazon DocumentDB 會調節請求。因此,某些操作可能會排入佇列,等待記憶體壓力下降。如果記憶體壓力持續,排入佇列的操作可能會逾時。您可以使用下列 CloudWatch 指標監控服務是否因記憶體不足而限流操作:LowMemThrottleQueueDepth、LowMemThrottleMaxQueueDepth、LowMemNumOperationsThrottled、LowMemNumOperationsTimedOut。如需詳細資訊,請參閱使用 CloudWatch 監控 Amazon DocumentDB。如果您因為 LowMem CloudWatch 指標而在執行個體上看到持續的記憶體壓力,我們建議您擴展執行個體,為您的工作負載提供額外的記憶體。
讀取偏好設定選項
Amazon DocumentDB 使用雲端原生共用儲存服務,跨三個可用區域複寫六次資料,以提供高等級的耐用性。Amazon DocumentDB 不依賴將資料複寫至多個執行個體以達到耐久性。無論您的叢集資料包含的是單一執行個體或 15 個執行個體,它都具有耐用性。
寫入耐久性
Amazon DocumentDB 使用唯一、分散式、容錯、自我修復的儲存系統。此系統跨三個 AWS 可用區域複寫六份資料 (V=6),以提供高可用性和耐用性。寫入資料時,Amazon DocumentDB 會確保在大多數節點上持續記錄所有寫入,然後再確認寫入用戶端。如果您執行的是三節點 MongoDB 複本集,使用 的寫入考量{w:3, j:true}會在與 Amazon DocumentDB 比較時產生最佳的可能組態。
Amazon DocumentDB 叢集的寫入必須由叢集的寫入器執行個體處理。嘗試寫入讀取器會導致錯誤。來自 Amazon DocumentDB 主要執行個體的已確認寫入是耐用的,無法復原。Amazon DocumentDB 預設具有高耐用性,且不支援非耐久寫入選項。您無法修改耐用性層級 (即寫入考量)。Amazon DocumentDB 會忽略 w=任何內容,且實際上是 w:3 和 j: true。您無法減少它。
由於儲存和運算在 Amazon DocumentDB 架構中是分開的,因此具有單一執行個體的叢集非常耐用。耐用性會在儲存層處理。因此,具有單一執行個體和具有三個執行個體的 Amazon DocumentDB 叢集可達到相同等級的耐用性。您可以設定您的叢集,以適用於特定使用案例,同時又可為您的資料提供高耐用性。
在單一文件中寫入 Amazon DocumentDB 叢集是原子的。
Amazon DocumentDB 不支援 wtimeout選項,如果指定了值,則不會傳回錯誤。對主要 Amazon DocumentDB 執行個體的寫入保證不會無限期封鎖。
讀取隔離
從 Amazon DocumentDB 執行個體讀取的資料只會在查詢開始之前傳回耐久的資料。讀取永遠不會傳回在查詢開始執行後修改的資料,在任何情況下。也不可能會發生已變更讀取。
讀取一致性
從 Amazon DocumentDB 叢集讀取的資料很耐用,不會復原。您可以指定請求或連線的讀取偏好設定,以修改 Amazon DocumentDB 讀取的讀取一致性。Amazon DocumentDB 不支援非耐久讀取選項。
Amazon DocumentDB 叢集主要執行個體的讀取在正常操作條件下非常一致,且具有read-after-write一致性。如果在寫入和後續讀取之間發生容錯移轉事件,系統可以短暫傳回非極其一致的讀取。所有來自僅供讀取複本的讀取最終皆會一致,並以相同順序傳回資料,複本延遲通常小於 100 毫秒。
Amazon DocumentDB 讀取偏好設定
只有在複本集模式下從叢集端點讀取資料時,Amazon DocumentDB 才支援設定讀取偏好設定選項。設定讀取偏好設定選項會影響 MongoDB 用戶端或驅動程式將讀取請求路由到 Amazon DocumentDB 叢集中執行個體的方式。您可以為特定查詢設定讀取偏好設定選項,或將其設為 MongoDB 驅動程式的一般選項。(請參閱用戶端或驅動程式的文件,以取得如何設定讀取偏好設定選項。)
如果您的用戶端或驅動程式未在複本集模式下連線至 Amazon DocumentDB 叢集端點,則不會定義指定讀取偏好設定的結果。
Amazon DocumentDB 不支援將標籤集設定為讀取偏好設定。
支援讀取偏好設定選項
-
primary—指定primary讀取偏好設定有助於確保所有讀取都路由到叢集的主要執行個體。如果主要執行個體不可用時,讀取操作會失敗。primary讀取偏好設定會產生先寫後讀一致性,且適用於以下使用案例:將先寫後讀一致性的優先順序排在高可用性和讀取擴展之前。以下範例指定
primary讀取偏好設定:db.example.find().readPref('primary') -
primaryPreferred- 在正常操作下指定primaryPreferred讀取偏好設定路由讀取至主要執行個體。如果是主要容錯移轉,用戶端會將請求路由到複本。primaryPreferred讀取偏好會在一般操作期間提供先寫後讀一致性,並在容錯移轉事件期間提供最終一致讀取。primaryPreferred讀取偏好設定適用於以下使用案例:將先寫後讀一致性的優先順序排在讀取擴展之前 (但仍需要高可用性)。以下範例指定
primaryPreferred讀取偏好設定:db.example.find().readPref('primaryPreferred') -
secondary—指定secondary讀取偏好設定可確保讀取只會路由至複本,而不會路由至主要執行個體。如果叢集中沒有複本執行個體,讀取請求會失敗。secondary讀取偏好設定會產生最終一致讀取,且適用於以下使用案例:將主要執行個體寫入傳輸量的優先順序排在高可用性和先寫後讀一致性之前。以下範例指定
secondary讀取偏好設定:db.example.find().readPref('secondary') -
secondaryPreferred- 指定secondaryPreferred讀取偏好設定可確保在一或多個複本處於作用中狀態時,讀取會路由至僅供讀取複本。如果沒有叢集中沒有作用中的複本執行個體,系統會將讀取請求路由到主要執行個體。secondaryPreferred讀取偏好會在僅供讀取複本提供讀取服務時,提供最終一致讀取。它會在主要執行個體提供讀取服務時,提供先寫後讀一致性 (除了容錯移轉事件以外)。secondaryPreferred讀取偏好設定適用於以下使用案例:將先寫後讀一致性的優先順序排在高可用性和讀取擴展之前。以下範例指定
secondaryPreferred讀取偏好設定:db.example.find().readPref('secondaryPreferred') -
nearest- 指定nearest讀取偏好設定路由只會根據用戶端與 Amazon DocumentDB 叢集中所有執行個體之間的測量延遲進行讀取。nearest讀取偏好會在僅供讀取複本提供讀取服務時,提供最終一致讀取。它會在主要執行個體提供讀取服務時,提供先寫後讀一致性 (除了容錯移轉事件以外)。nearest讀取偏好設定適用於以下使用案例:將達到最低可能讀取延遲和高可用性的優先順序排在先寫後讀一致性和讀取擴展之前。以下範例指定
nearest讀取偏好設定:db.example.find().readPref('nearest')
高可用性
Amazon DocumentDB 使用複本做為主要執行個體的容錯移轉目標,以支援高可用性叢集組態。如果主要執行個體失敗,Amazon DocumentDB 複本會提升為新的主要執行個體,並短暫中斷,在此期間對主要執行個體發出的讀取和寫入請求會失敗,但有例外。
如果您的 Amazon DocumentDB 叢集不包含任何複本,則會在失敗期間重新建立主要執行個體。不過,提升 Amazon DocumentDB 複本比重新建立主要執行個體快得多。因此,我們建議您建立一或多個 Amazon DocumentDB 複本做為容錯移轉目標。
做為容錯移轉目標的複本執行個體類別應與主要執行個體的執行個體類別相同。它們應該佈建在與主要執行個體不同的可用區域。您可以控制哪些複本是偏好做為容錯移轉目標。如需設定 Amazon DocumentDB 以獲得高可用性的最佳實務,請參閱 了解 Amazon DocumentDB 叢集容錯能力。
擴展讀取
Amazon DocumentDB 複本非常適合用於讀取擴展。他們完全專用於叢集磁碟區上的讀取操作,也就是說,複本並不會處理寫入。資料複寫發生於叢集磁碟區內,而非執行個體之間。因此,每個複本的資源都專用於處理您的查詢,而非複寫和寫入資料。
如果您的應用程式需要讀取容量,您可以快速將複本新增到您的叢集 (通常少於十分鐘)。如果您的讀取容量需求減少,您可以移除不需要的複本。使用 Amazon DocumentDB 複本時,您只需為所需的讀取容量付費。
Amazon DocumentDB 透過使用讀取偏好設定選項支援用戶端讀取擴展。如需詳細資訊,請參閱Amazon DocumentDB 讀取偏好設定。
TTL 刪除
透過背景程序從 TTL 索引刪除是最佳作法,但無法保證可在特定時間範圍內完成。像是執行個體大小、執行個體資源使用率、文件大小和整體輸送量等因素,都會影響 TTL 刪除的時間。
當 TTL 監控器刪除文件時,每個刪除都會產生 IO 成本,使帳單金額增加。如果輸送量和 TTL 刪除率增加,由於 IO 用量增加,您應該預期帳單會增加。
當您在現有集合上建立 TTL 索引時,您必須先刪除所有過期的文件,再建立索引。目前的 TTL 實作已針對刪除集合中的一小部分文件進行最佳化,這通常是從一開始在集合上啟用 TTL 的情況,如果需要一次刪除大量文件,可能會導致高於必要的 IOPS。
如果您不想建立 TTL 索引來刪除文件,您可以改為根據時間將文件分割為集合,並在不再需要文件時直接捨棄這些集合。例如:您可以每週建立一個集合並捨棄它,而不會產生 IO 成本。這比使用 TTL 索引更具成本效益。
計費資源
識別計費的 Amazon DocumentDB 資源
作為全受管資料庫服務,Amazon DocumentDB 會針對執行個體、儲存體、I/O、備份和資料傳輸收取費用。如需詳細資訊,請參閱 Amazon DocumentDB (與 MongoDB 相容) 定價
若要探索帳戶中的計費資源,並可能刪除資源,您可以使用 AWS 管理主控台 或 AWS CLI。
使用 AWS 管理主控台
使用 AWS 管理主控台,您可以探索已為指定 佈建的 Amazon DocumentDB 叢集、執行個體和快照 AWS 區域。
找出叢集、執行個體和快照
登入 AWS 管理主控台,並在 https://console.aws.amazon.com/docdb
:// 開啟 Amazon DocumentDB 主控台。 -
若要探索預設區域以外的區域中的計費資源,請在畫面右上角選擇要 AWS 區域 搜尋的 。

-
在導覽窗格中,選擇您感興趣的應計費資源類型:Clusters (叢集)、Instances (執行個體) 或 Snapshots (快照)。
-
右窗格會列出您針對該區域佈建的所有叢集、執行個體或快照。您需要支付叢集、執行個體和快照的費用。
使用 AWS CLI
使用 AWS CLI,您可以探索已為指定 佈建的 Amazon DocumentDB 叢集、執行個體和快照 AWS 區域。
找出叢集和執行個體
以下程式碼會列出指定區域的所有叢集和執行個體。如果想要搜尋預設區域中的叢集和執行個體,您可以省略 --region 參數。
範例
針對 Linux、macOS 或 Unix:
aws docdb describe-db-clusters \ --region us-east-1 \ --query 'DBClusters[?Engine==`docdb`]' | \ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
針對 Windows:
aws docdb describe-db-clusters ^ --region us-east-1 ^ --query 'DBClusters[?Engine==`docdb`]' | ^ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
此操作的輸出將會如下所示。
"DBClusterIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-382",
"DBClusterIdentifier": "sample-cluster",
"DBClusterIdentifier": "sample-cluster2",找出快照
以下程式碼會列出指定區域的所有快照。如果想要搜尋預設區域中的快照,您可以省略 --region 參數。
針對 Linux、macOS 或 Unix:
aws docdb describe-db-cluster-snapshots \ --region us-east-1 \ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
針對 Windows:
aws docdb describe-db-cluster-snapshots ^ --region us-east-1 ^ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
此操作的輸出將會如下所示。
[
[
"rds:docdb-2019-01-09-23-55-38-2019-02-13-00-06",
"automated"
],
[
"test-snap",
"manual"
]
]您只需要刪除 manual 快照。當您刪除叢集時,也會刪除 Automated 快照。
刪除不需要的計費資源
若要刪除某個叢集,您必須先刪除該叢集中的所有執行個體。
-
若要刪除執行個體,請參閱刪除 Amazon DocumentDB 執行個體。
重要
即使您刪除叢集中的執行個體,您仍需要支付使用該叢集相關聯儲存和備份的費用。若要停止所有費用,您必須也要刪除您的叢集和手動快照。
-
若要刪除叢集,請參閱刪除 Amazon DocumentDB 叢集。
-
若要刪除手動快照,請參閱刪除叢集快照。
