本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
將 Amazon S3 Access Grants 與 Amazon EMR 搭配使用
Amazon EMR 的 S3 Access Grants 概觀
在 Amazon EMR 6.15.0 及更高版本中,Amazon S3 Access Grants 提供可擴展的存取控制解決方案,您可以使用該解決方案來增強從 Amazon EMR 對 Amazon S3 資料的存取權限。如果您的 S3 資料有複雜或大型的許可組態,您可以使用 Access Grants 來擴展叢集上使用者、角色和應用程式的 S3 資料許可。
使用 S3 Access Grants 可增強對 Amazon S3 資料的存取權限,超越由執行期角色或連接至有權存取 EMR 叢集之身分的 IAM 角色所授予的許可。如需詳細資訊,請參閱《Amazon S3 使用者指南》中的使用 S3 Access Grants 管理存取。
如需了解透過其他 Amazon EMR 部署來使用 S3 Access Grants 的步驟,請參閱下列文件:
Amazon EMR 如何與 S3 Access Grants 搭配運作
Amazon EMR 6.15.0 及更高版本提供與 S3 Access Grants 的原生整合。您可以在 Amazon EMR 上啟用 S3 Access Grants,並執行 Spark 作業。當 Spark 作業提出 S3 資料請求時,Amazon S3 會提供僅限於特定儲存貯體、字首或物件的臨時憑證。
以下是 Amazon EMR 如何存取受 S3 Access Grants 保護之資料的高階概觀。
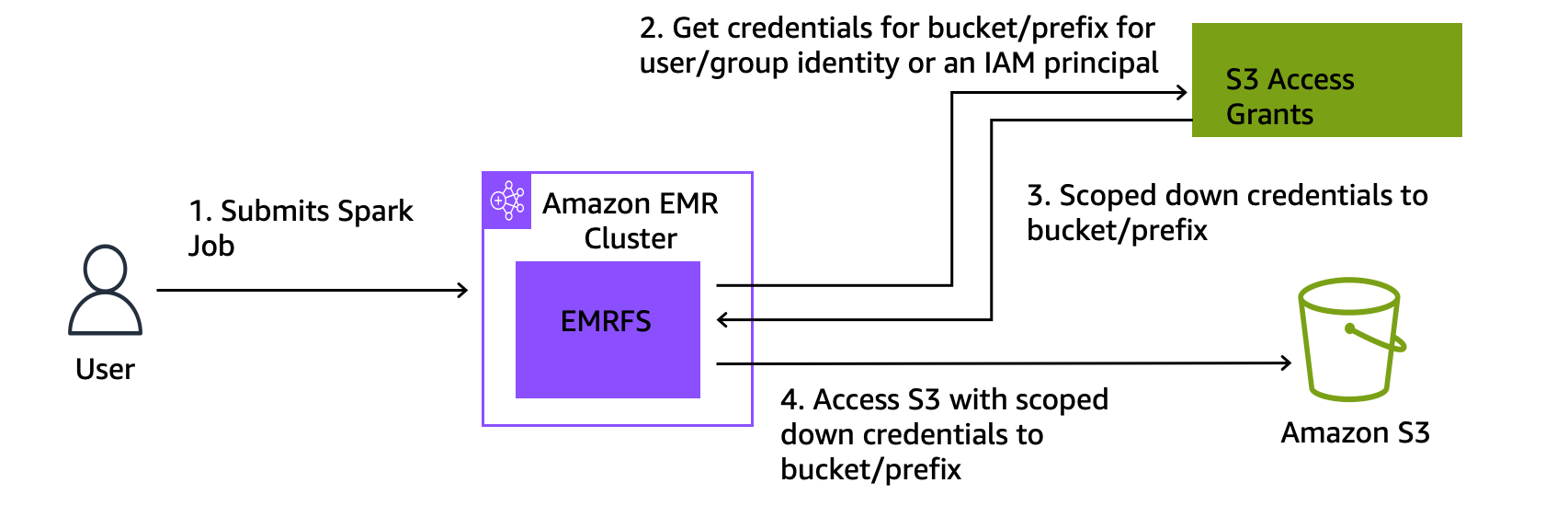
-
使用者會提交使用存放在 Amazon S3 中之資料的 Amazon EMR Spark 作業。
-
Amazon EMR 會提出 S3 Access Grants 請求,以允許代表該使用者存取儲存貯體、字首或物件。
-
Amazon S3 會以 AWS Security Token Service (STS) 權杖的形式傳回使用者的臨時憑證。權杖的範圍設定為存取 S3 儲存貯體、字首或物件。
-
Amazon EMR 會使用 STS 權杖從 S3 擷取資料。
-
Amazon EMR 會從 S3 接收資料,並將結果傳回給使用者。
S3 Access Grants 與 Amazon EMR 搭配的考量事項
將 S3 Access Grants 與 Amazon EMR 搭配使用時,請注意以下行為和限制。
功能支援
-
Amazon EMR 版本 6.15.0 及更高版本支援 S3 Access Grants。
-
當您將 S3 Access Grants 與 Amazon EMR 搭配使用時,Spark 是唯一支援的查詢引擎。
-
當您將 S3 Access Grants 與 Amazon EMR 搭配使用時,支援的開放式資料表格式僅有 Delta Lake 和 Hudi。
-
以下 Amazon EMR 功能不支援與 S3 Access Grants 搭配使用:
-
Apache Iceberg 資料表
-
LDAP 原生身分驗證
-
Apache Ranger 原生身分驗證
-
AWS CLI 對使用 IAM 角色的 Amazon S3 的請求
-
透過開放原始碼 S3A 通訊協定的 S3 存取
-
-
將 Trusted Identity Propagation 與 IAM Identity Center 搭配使用的 EMR 叢集不支援
fallbackToIAM選項。 -
只有在 Amazon EC2 上運作的 Amazon EMR 叢集才支援 S3 Access Grants 搭配 AWS Lake Formation。
行為考量事項
-
與 Amazon EMR 的 Apache Ranger 原生整合會維持符合 S3 Access Grants 的功能,作為 EMRFS S3 Apache Ranger 外掛程式的一部分。如果您使用 Apache Ranger 進行精細存取控制 (FGAC),建議您使用該外掛程式而非使用 S3 Access Grants。
-
Amazon EMR 會在 EMRFS 中提供憑證快取,以確保使用者無需在 Spark 作業中針對相同憑證提出重複請求。因此,Amazon EMR 在請求憑證時一律會請求預設層級權限。如需詳細資訊,請參閱《Amazon S3 使用者指南》中的請求存取 S3 資料。
-
若使用者執行 S3 Access Grants 不支援的動作,Amazon EMR 會設定為使用為作業執行指定的 IAM 角色。如需詳細資訊,請參閱回復為 IAM 角色。
使用 S3 Access Grants 啟動 Amazon EMR 叢集
本節說明如何啟動在 Amazon EC2 上執行的 EMR 叢集,以及如何使用 S3 Access Grants 來管理 Amazon S3 中的資料存取。如需了解透過其他 Amazon EMR 部署來使用 S3 Access Grants 的步驟,請參閱下列文件:
使用以下步驟啟動在 Amazon EC2 上執行的 EMR 叢集,以及使用 S3 Access Grants 來管理 Amazon S3 中的資料存取。
-
為您的 EMR 叢集設定作業執行角色。包括執行 Spark 作業所需的必要 IAM 許可
s3:GetDataAccess及s3:GetAccessGrantsInstanceForPrefix:{ "Effect": "Allow", "Action": [ "s3:GetDataAccess", "s3:GetAccessGrantsInstanceForPrefix" ], "Resource": [ //LIST ALL INSTANCE ARNS THAT THE ROLE IS ALLOWED TO QUERY "arn:aws_partition:s3:Region:account-id1:access-grants/default", "arn:aws_partition:s3:Region:account-id2:access-grants/default" ] }注意
使用 Amazon EMR 時,S3 Access Grants 可增強 IAM 角色中設定的許可。如果您指定用於作業執行的 IAM 角色包含直接存取 S3 的許可,則使用者可能能夠存取比您在 S3 Access Grants 中定義之資料多的資料。
-
接著,使用 AWS CLI 建立具有 Amazon EMR 6.15 或更新版本的叢集,以及啟用 S3 Access Grants 的
emrfs-site分類,類似下列範例:aws emr create-cluster --release-label emr-6.15.0 \ --instance-count 3 \ --instance-type m5.xlarge \ --configurations '[{"Classification":"emrfs-site", "Properties":{"fs.s3.s3AccessGrants.enabled":"true", "fs.s3.s3AccessGrants.fallbackToIAM":"false"}}]'
使用 的 S3 Access Grants AWS Lake Formation
如果您將 Amazon EMR 與 AWS Lake Formation 整合搭配使用,則可使用 Amazon S3 Access Grants 以直接或表格式方式存取 Amazon S3 中的資料。
注意
使用 的 S3 Access Grants AWS Lake Formation 僅支援在 Amazon EC2 上執行的 Amazon EMR 叢集。
- 直接存取
-
直接存取涉及所有存取 S3 資料的呼叫,其不會叫用 Lake Formation AWS 用作 Amazon EMR 中繼存放區的 Glue 服務 API,例如,呼叫
spark.read:spark.read.csv("s3://...")當您在 Amazon EMR AWS Lake Formation 上使用 S3 Access Grants 搭配 時,所有直接存取模式都會經過 S3 Access Grants,以取得臨時 S3 登入資料。
- 表格式存取
-
當 Lake Formation 調用中繼存放區 API 來存取 S3 位置 (例如) 以便查詢資料表資料 時,便會發生表格式存取:
spark.sql("select * from test_tbl")當您在 Amazon EMR AWS Lake Formation 上使用 S3 Access Grants 搭配 時,所有表格式存取模式都會經過 Lake Formation。
回復為 IAM 角色
如果使用者嘗試執行 S3 Access Grants 不支援的動作,則在 fallbackToIAM 組態為 true 時,Amazon EMR 會預設至為作業執行指定的 IAM 角色。這讓使用者可回復其作業執行角色,以在 S3 Access Grants 未涵蓋的案例中,提供 S3 存取憑證。
fallbackToIAM 啟用後,使用者可以存取 Access Grant 允許的資料。如果目標資料沒有 S3 Access Grant 權杖,則 Amazon EMR 會檢查其作業執行角色的許可。
注意
即使您打算停用生產工作負載的選項,我們仍建議您在啟用 fallbackToIAM 組態的情況下測試存取許可。透過 Spark 作業,使用者可能能夠使用其他方式來以其 IAM 憑證存取所有許可集。在 EMR 叢集上啟用時,S3 的授權可讓 Spark 作業存取 S3 位置。您應確保已保護這些 S3 位置,避免受到 EMRFS 以外的存取。例如,您應該保護 S3 位置,避免受到筆記本中使用的 S3 用戶端存取,或受到 S3 Access Grants 不支援的應用程式 (例如 Hive 或 Presto) 存取。
