本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
教學課程:Amazon EMR 入門
逐步完成工作流程,以快速設定 Amazon EMR 叢集並執行 Spark 應用程式。
設定 Amazon EMR 叢集
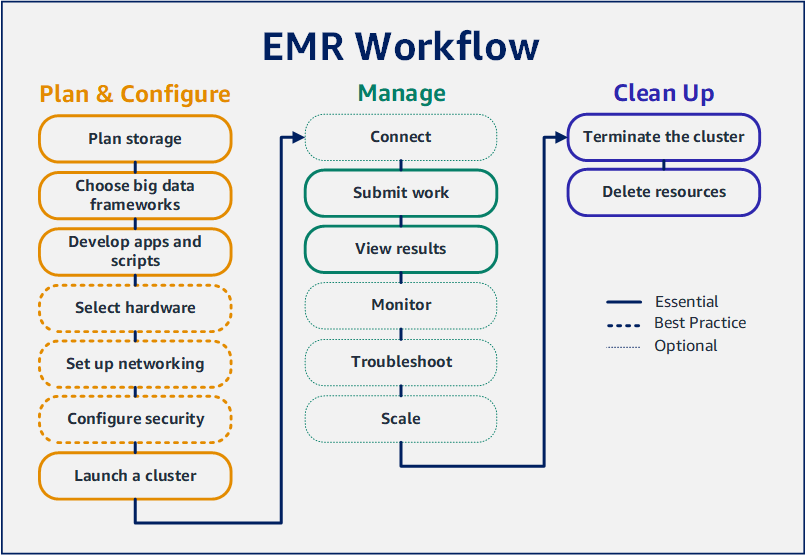
使用 Amazon EMR,您可以在幾分鐘內設定叢集,透過大數據框架來處理和分析資料。本教學課程說明如何使用 Spark 啟動範例叢集,以及如何執行儲存在 Amazon S3 儲存貯體中的簡單 PySpark 指令碼。它涵蓋三個主要工作流程類別的基本 Amazon EMR 任務:規劃和設定、管理以及清理。
循序完成教學課程時可尋找更詳細主題的連結,以及 後續步驟 章節中其他步驟的想法。如果您有任何問題或陷入困境,請聯絡討論論壇
先決條件
-
在啟動 Amazon EMR 叢集之前,請務必完成 在您設定 Amazon EMR 之前 中的任務。
成本
-
您所建立的範例叢集,會在實際環境中執行。叢集會產生最低費用。若要避免其他費用,請務必完成本教學課程最後一個步驟中的清理任務。根據 Amazon EMR 定價,按每秒計算費用。費用亦因區域而異。如需詳細資訊,請參閱 Amazon EMR 定價
。 -
儲存於 Amazon S3 的小型檔案可能會產生最低費用。如果您在AWS免費方案的使用限制內,可能會免除 Amazon S3 的部分或所有費用。如需詳細資訊,請參閱 Amazon S3 定價
和 AWS 免費方案 。
步驟 1:設定資料資源並啟動 Amazon EMR 叢集
為 Amazon EMR 準備儲存體
使用 Amazon EMR 時,可以從各種檔案系統中進行選擇,以儲存輸入資料、輸出資料和日誌檔案。在此教學課程中,可以使用 EMRFS 將資料儲存在 S3 儲存貯體中。EMRFS 是 Hadoop 檔案系統的實作,可讓您在 Amazon S3 讀取和寫入一般檔案。如需詳細資訊,請參閱使用 Amazon EMR 處理儲存和檔案系統。
若要為此教學課程建立儲存貯體,請遵循《Amazon Simple Storage Service 使用者指南》中如何建立 S3 儲存貯體?中的說明。在您計劃啟動 Amazon EMR 叢集的相同AWS區域中建立儲存貯體。例如,美國西部 (奧勒岡) us-west-2。
您搭配 Amazon EMR 使用的儲存貯體和資料夾具有下列限制:
-
名稱可以包含小寫字母、數字、句點 (.) 與連字號 (-)。
-
名稱不能以數字結尾。
-
儲存貯體名稱在所有 AWS 帳戶中必須唯一。
-
輸出資料夾必須為空。
為 Amazon EMR 準備具有輸入資料的應用程式
為 Amazon EMR 準備應用程式的最常見方法是將應用程式及其輸入資料上傳至 Amazon S3。然後,當您將工作提交到叢集時,可以為指令碼和資料指定 Amazon S3 位置。
在此步驟中,可以將範例 PySpark 指令碼上傳到 Amazon S3 儲存貯體。我們已經提供 PySpark 指令碼供您使用。指令碼會處理食品機構檢查資料,並在 S3 儲存貯體中傳回結果檔案。結果檔案會列出「紅色」違規行為最多的十大機構。
也可以將範例輸入資料上傳到 Amazon S3,以便 PySpark 指令碼進行處理。輸入資料是 2006 年至 2020 年華盛頓州金縣衛生部門檢查結果的修改版本。如需詳細資訊,請參閱金縣公開資料:食品機構檢查資料
name,inspection_result,inspection_closed_business,violation_type,violation_points 100 LB CLAM,Unsatisfactory,FALSE,BLUE,5 100 PERCENT NUTRICION,Unsatisfactory,FALSE,BLUE,5 7-ELEVEN #2361-39423A,Complete,FALSE,,0
若要為 EMR 準備範例 PySpark 指令碼
-
將以下範例程式碼複製到您所選編輯器的新檔案中。
import argparse from pyspark.sql import SparkSession def calculate_red_violations(data_source, output_uri): """ Processes sample food establishment inspection data and queries the data to find the top 10 establishments with the most Red violations from 2006 to 2020. :param data_source: The URI of your food establishment data CSV, such as 's3://amzn-s3-demo-bucket/food-establishment-data.csv'. :param output_uri: The URI where output is written, such as 's3://amzn-s3-demo-bucket/restaurant_violation_results'. """ with SparkSession.builder.appName("Calculate Red Health Violations").getOrCreate() as spark: # Load the restaurant violation CSV data if data_source is not None: restaurants_df = spark.read.option("header", "true").csv(data_source) # Create an in-memory DataFrame to query restaurants_df.createOrReplaceTempView("restaurant_violations") # Create a DataFrame of the top 10 restaurants with the most Red violations top_red_violation_restaurants = spark.sql("""SELECT name, count(*) AS total_red_violations FROM restaurant_violations WHERE violation_type = 'RED' GROUP BY name ORDER BY total_red_violations DESC LIMIT 10""") # Write the results to the specified output URI top_red_violation_restaurants.write.option("header", "true").mode("overwrite").csv(output_uri) if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument( '--data_source', help="The URI for you CSV restaurant data, like an S3 bucket location.") parser.add_argument( '--output_uri', help="The URI where output is saved, like an S3 bucket location.") args = parser.parse_args() calculate_red_violations(args.data_source, args.output_uri) -
儲存檔案為
health_violations.py。 -
將
health_violations.py上傳到您為本教學課程建立的 Amazon S3 儲存貯體。如需指示說明,請參閱《Amazon Simple Storage Service 入門指南》中的將物件上傳至儲存貯體。
為 EMR 準備範例輸入資料
-
下載 zip 檔案,food_establishment_data.zip。
-
解壓縮並在您的機器中將
food_establishment_data.zip儲存為food_establishment_data.csv。 -
將 CSV 檔案上傳到您為本教學課程建立的 S3 儲存貯體。如需指示說明,請參閱《Amazon Simple Storage Service 入門指南》中的將物件上傳至儲存貯體。
如需有關為 EMR 設定資料的詳細資訊,請參閱 準備輸入資料以使用 Amazon EMR 進行處理。
啟動 Amazon EMR 叢集
準備儲存位置和應用程式後,您可以啟動範例 Amazon EMR 叢集。在此步驟中,可使用最新的 Amazon EMR 發行版本來啟動 Apache Spark 叢集。
步驟 2:將工作提交到您的 Amazon EMR 叢集
提交工作並檢視結果
啟動叢集之後,可以將工作提交至正在執行的叢集,以處理和分析資料。作為一個步驟,將工作提交至 Amazon EMR 叢集。步驟是由一個或多個動作組成的工作單元。例如,您可以提交一個步驟來計算值,或者傳輸和處理資料。您可以在建立叢集時提交步驟,或者提交至正在執行的叢集。在本教學課程的此部分中,會作為一個步驟將 health_violations.py 提交至正在執行的叢集。若要進一步了解步驟,請參閱 將工作提交至 Amazon EMR 叢集。
如需有關步驟生命週期的詳細資訊,請參閱 執行步驟來處理資料。
檢視結果
步驟成功執行後,可以在 Amazon S3 輸出資料夾中檢視其輸出結果。
若要檢視 health_violations.py 的結果
開啟位於 https://console.aws.amazon.com/s3/
的 Amazon S3 主控台。 -
選擇儲存貯體名稱,然後選擇在提交步驟時指定的輸出資料夾。例如,
amzn-s3-demo-bucket和myOutputFolder。 -
確認輸出資料夾中顯示下列項目:
-
稱為
_SUCCESS的小型物件。 -
以字首
part-開頭的 CSV 檔案,它包含結果。
-
-
選擇包含結果的物件,然後選擇下載,將結果儲存至本機檔案系統。
-
在您選擇的編輯器中開啟結果。輸出檔案會列出紅色違規行為最多的十大食品機構。輸出檔案也會顯示每個機構的紅色違規總數。
以下是
health_violations.py結果範例。name, total_red_violations SUBWAY, 322 T-MOBILE PARK, 315 WHOLE FOODS MARKET, 299 PCC COMMUNITY MARKETS, 251 TACO TIME, 240 MCDONALD'S, 177 THAI GINGER, 153 SAFEWAY INC #1508, 143 TAQUERIA EL RINCONSITO, 134 HIMITSU TERIYAKI, 128
如需有關 Amazon EMR 叢集輸出的詳細資訊,請參閱 設定 Amazon EMR 叢集輸出的位置。
使用 Amazon EMR 時,您可能想要連接到執行中的叢集以讀取日誌檔案、對叢集進行偵錯或者使用諸如 Spark Shell 等 CLI 工具。Amazon EMR 可讓您使用 Secure Shell (SSH) 通訊協定連接到叢集。本章節說明如何設定 SSH、連接至叢集以及檢視 Spark 的日誌檔案。如需有關連接至叢集的詳細資訊,請參閱 對 Amazon EMR 叢集節點進行驗證。
授權叢集的 SSH 連線
在連接到叢集之前,需要修改叢集安全群組以授權傳入 SSH 連線。Amazon EC2 安全群組就像是虛擬防火牆,可控管傳入和傳出叢集的流量。當您為本教學課程建立叢集時,Amazon EMR 會代表您建立下列安全群組:
- ElasticMapReduce-master
-
與主節點關聯的預設 Amazon EMR 受管安全群組。在 Amazon EMR 叢集中,主節點是管理叢集的 Amazon EC2 執行個體。
- ElasticMapReduce-slave
-
與核心節點和任務節點相關聯的預設安全群組。
使用 連線至您的叢集AWS CLI
無論作業系統為何,都可以使用 AWS CLI 來建立叢集的 SSH 連線。
使用 連線至您的叢集並檢視日誌檔案AWS CLI
-
使用以下命令開啟叢集的 SSH 連線。將
<mykeypair.key>取代為金鑰對檔案的完整路徑和檔案名稱。例如C:\Users\<username>\.ssh\mykeypair.pem。aws emr ssh --cluster-id<j-2AL4XXXXXX5T9>--key-pair-file<~/mykeypair.key> -
瀏覽至
/mnt/var/log/spark以存取叢集主節點上的 Spark 日誌。然後檢視該位置中的檔案。如需主節點上其他日誌檔案的清單,請參閱 檢視主節點上的日誌檔案。cd /mnt/var/log/spark ls
Amazon EMR on EC2 也是 Amazon SageMaker AIUnified Studio 支援的運算類型。如需如何在 Amazon SageMaker AIUnified Studio 中使用和管理 ECEC2,請參閱管理 ECEC2 上的 Amazon EMR。
步驟 3:清理 Amazon EMR 資源
終止叢集
既然已將工作提交至叢集,並已檢視 PySpark 應用程式的結果,就可以終止叢集。終止叢集會停止叢集的所有相關聯 Amazon EMR 費用和 Amazon EC2 執行個體。
當您終止叢集時,Amazon EMR 會免費將有關叢集的中繼資料保留兩個月。封存的中繼資料可協助您為新作業複製叢集,或重新檢視叢集組態以供參考。中繼資料不包含叢集寫入到 S3 的資料,或儲存在叢集 HDFS 中的資料。
注意
終止叢集後,Amazon EMR 主控台不允許您從清單檢視中刪除叢集。當 Amazon EMR 清除其中繼資料時,終止的叢集會從主控台中消失。
刪除 S3 資源
為避免額外費用,應刪除 Amazon S3 儲存貯體。刪除儲存貯體會移除本教學課程的所有 Amazon S3 資源。您的儲存貯體應包含:
-
PySpark 指令碼
-
輸入資料集
-
輸出結果資料夾
-
日誌檔案資料夾
如果將 PySpark 指令碼或輸出儲存在不同位置,則可能需要採取額外的步驟來刪除已儲存的檔案。
注意
在刪除儲存貯體之前,必須終止叢集。否則,可能不允許您清空儲存貯體。
若要刪除儲存貯體,請依照《Amazon Simple Storage Service 使用者指南》中如何刪除 S3 儲存貯體?提供的說明進行操作。
後續步驟
您現在已從頭到尾啟動了您的第一個 Amazon EMR 叢集。您也已完成必要的 EMR 任務,例如準備和提交大數據應用程式、檢視結果以及終止叢集。
使用以下主題,進一步了解如何自訂 Amazon EMR 工作流程。
探索適用於 Amazon EMR 的大數據應用程式
在 Amazon EMR 版本指南中探索並比較可在叢集上安裝的大數據應用程式。《版本指南》詳細說明了每個 EMR 發行版本,並包含在 Amazon EMR 上使用 Spark 和 Hadoop 等框架的提示。
規劃叢集硬體、聯網和安全性
在本教學課程中,您建立了一個簡單的 EMR 叢集,而沒有設定進階選項。進階選項可讓您指定 Amazon EC2 執行個體類型、叢集聯網和叢集安全性。如需有關規劃和啟動符合您要求的叢集的詳細資訊,請參閱 規劃、設定和啟動 Amazon EMR 叢集 和 Amazon EMR 中的安全。
管理叢集
深入了解如何在 管理 Amazon EMR 叢集 中使用正在執行的叢集。若要管理叢集,可以連線至叢集,對步驟進行偵錯,以及追蹤叢集活動和運作狀態。也可以使用 EMR 受管擴展來調整叢集資源,以回應工作負載需求。
使用不同的介面
除了 Amazon EMR 主控台之外,您還可以使用 AWS Command Line Interface、Web 服務 API 或許多支援的 AWSSDKs 之一來管理 Amazon EMR。如需詳細資訊,請參閱管理介面。
也可以透過多種方式與 Amazon EMR 叢集上安裝的應用程式互動。一些應用程式,例如 Apache Hadoop,會發布您可檢視的 Web 介面。如需詳細資訊,請參閱檢視 Amazon EMR 叢集上託管的 Web 介面。
瀏覽 EMR 技術部落格
如需 Amazon EMR 新功能的範例逐步解說和深入的技術討論,請參閱 AWS 大數據部落格
