本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
啟用使用者模擬以監視 Spark 使用者和作業活動
注意
EMR筆記本可作為主控台中的 EMR Studio 工作區使用。主控台中的 [建立工作區] 按鈕可讓您建立新的筆記本。若要存取或建立工作區,EMR筆記本使用者需要額外的IAM角色權限。有關詳情,請參閱 Amazon EMR 筆記本是控制台和 Amazon 控制台中的 Amazon EMR 工作EMR室工作區。
EMR筆記本可讓您在 Spark 叢集上設定使用者模擬。此功能可協助您追蹤從筆記本編輯器起始的任務活動。此外,EMR筆記本還有一個內置的 Jupyter 筆記本小部件,可以在筆記本編輯器中查看 Spark 工作詳細信息以及查詢輸出。這項小工具為預設提供,不需要進行特別的設定。但是,若要檢視歷程記錄伺服器,您的用戶端必須設定為檢視主節點上託管的 Amazon EMR Web 界面。
設定 Spark 使用者模擬
根據預設,使用者透過筆記本編輯器所提交的 Spark 任務,似乎源自於模糊的 livy 使用者身分。您可以為該叢集設訂使用者模擬,如此這些作業就會改為和執行程式碼的使用者身分產生關聯。HDFS會針對在筆記本中執行程式碼的每個使用者身分建立主節點上的使用者目錄。例如,如果使用者 NbUser1 從筆記本編輯器執行程式碼,您可以連線到主節點,然後檢視 hadoop fs -ls /user 顯示的目錄 /user/user_NbUser1。
若要啟用這項功能,您可以在 core-site 和 livy-conf 組態分類中設定屬性。當您讓 Amazon 與筆記本一起EMR建立叢集時,預設情況下無法使用此功能。如需使用組態分類自訂應用程式的詳細資訊,請參閱 Amazon EMR 版本指南中的設定應用程式。
使用下列組態分類和值來啟用筆記本的使用者模擬:EMR
[ { "Classification": "core-site", "Properties": { "hadoop.proxyuser.livy.groups": "*", "hadoop.proxyuser.livy.hosts": "*" } }, { "Classification": "livy-conf", "Properties": { "livy.impersonation.enabled": "true" } } ]
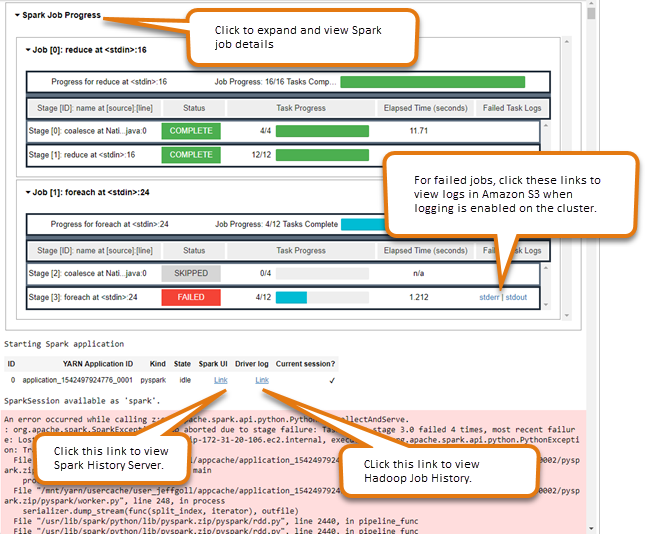
使用 Spark 作業監控小工具
當您在EMR叢集上執行 Spark 工作的筆記本編輯器中執行程式碼時,輸出會包含用於 Spark 工作監視的 Jupyter 筆記本小器具。這項小工具會提供作業詳細資訊和實用的連結 (連結到 Spark 歷史記錄伺服器頁面與 Hadoop 作業歷史記錄頁面),以及便利的連結,可針對任何失敗的作業,連結到 Amazon S3 中的作業日誌。
若要檢視叢集主要節點上的歷史記錄伺服器頁面,您必須視需要設定SSH用戶端和 Proxy。如需詳細資訊,請參閱檢視在 Amazon EMR 叢集上託管的網頁界面。若要檢視 Amazon S3 中的日誌,必須啟用叢集日誌記錄,這是新叢集的預設功能。如需詳細資訊,請參閱檢視封存至 Amazon S3 的日誌檔案。
下列是 Spark 作業監控範例。