本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
檢查點
檢查點是 Flink 用於確保應用程式狀態具有容錯能力的機制。該機制允許 Flink 在作業失敗時恢復運算子的狀態,並為應用程式提供與無故障執行相同的語義。使用 Managed Service for Apache Flink,應用程式的狀態會儲存在 RocksDB 中,這是一個內嵌式索引鍵/值存放區,可將其工作狀態保留在磁碟上。取得檢查點時,狀態也會上傳至 Amazon S3,這樣即使磁碟遺失,也可以使用檢查點來還原應用程式狀態。
如需詳細資訊,請參閱狀態快照如何運作
檢查點階段
對於 Flink 中的檢查點運算子子任務,有 5 個主要階段:
等待 [開始延遲]:Flink 使用插入串流的檢查點障礙,因此在此階段的時間是運算子等待檢查點障礙到達它的時間。
對齊 [對齊持續時間]:在此階段,子任務已到達一個障礙,但它正在等待來自其他輸入串流的障礙。
同步檢查點 [同步持續時間]:在此階段,子任務會實際拍攝運算子狀態快照,並阻止該子任務上的所有其他活動。
非同步檢查點 [非同步持續時間]:此階段的主要操作是子任務將狀態上傳到 Amazon S3。在此階段,子任務不再被阻止,可以處理記錄。
確認:這通常是一個短暫的階段,只是子任務發送確認給 JobManager 並執行任何遞交訊息 (例如,使用 Kafka 接收器)。
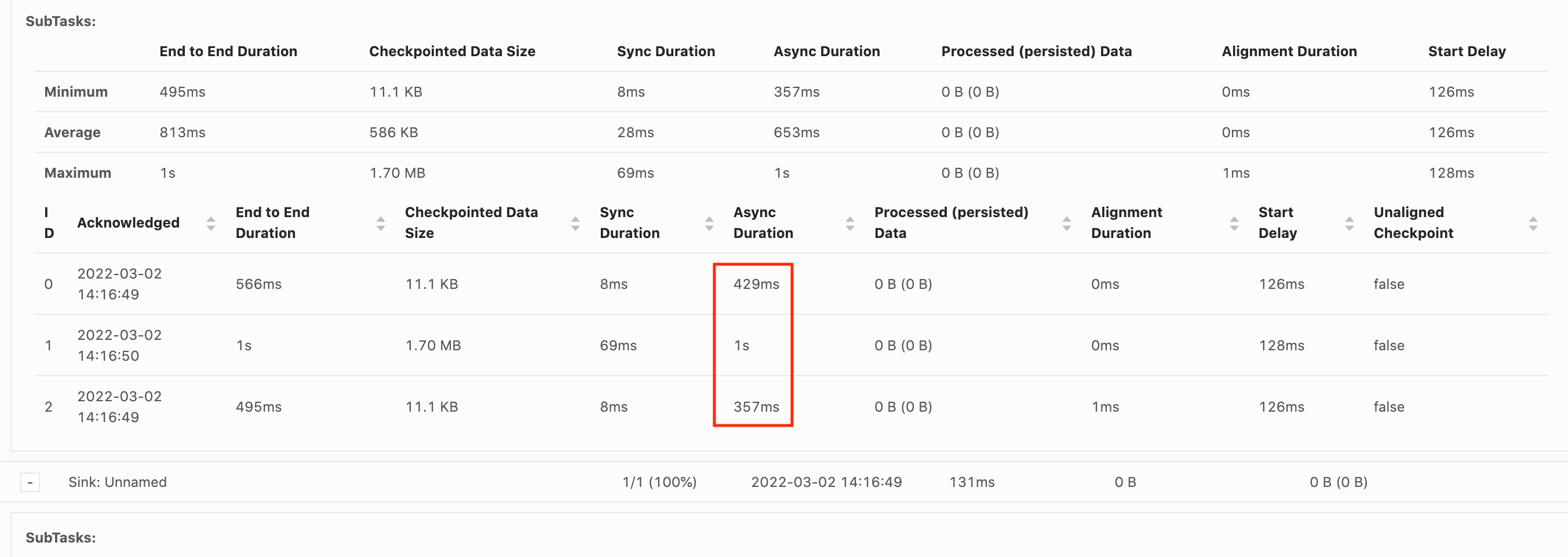
上述每個階段 (除了「確認」) 都對應到 Flink WebUI 中可用檢查點的持續時間指標,這可以幫助隔離長檢查點的原因。
要查看檢查點上每個可用指標的確切定義,請轉到歷史記錄
調查
調查長檢查點的持續時間時,最重要的是要確定檢查點的瓶頸,也就是說,什麼運算子和子任務正在採用最長檢查點,該子任務的哪個階段正在花費較長的時間。這可以使用作業檢查點任務下的 Flink WebUI 來確定。Flink 的 Web 介面提供了可協助調查檢查點問題的資料和資訊。如需完整明細,請參閱監控檢查點
首先要注意的是作業圖表中每個運算子的端對端持續時間,以確定哪個運算子需要較長時間才能到達檢查點,需要進一步調查。根據 Flink 文件,持續時間的定義如下:
從觸發時間戳記到最近確認為止的持續時間 (如果尚未收到確認,則為 n/a)。完整檢查點的端對端持續時間由確認檢查點的最後一個子任務決定。此時間通常大於單個子任務對狀態實際執行檢查點需要的時間。
檢查點的其他持續時間還提供了有關花費時間的更精細資訊。
如果同步持續時間很高,則表示快照過程中發生了問題。在這個階段,為實作 snapshotState 介面的類別呼叫 snapshotState();這可以是使用者程式碼,所以執行緒傾印對於調查這一點會有幫助。
非同步持續時間長表明將狀態上傳到 Amazon S3 花費了大量時間。如果狀態很大,或者有許多狀態檔案正在上傳,就會發生這種情況。如果是這種情況,則值得調查應用程式如何使用狀態,並確保在可能的情況下使用 Flink 本機資料結構 (使用具有索引鍵的狀態
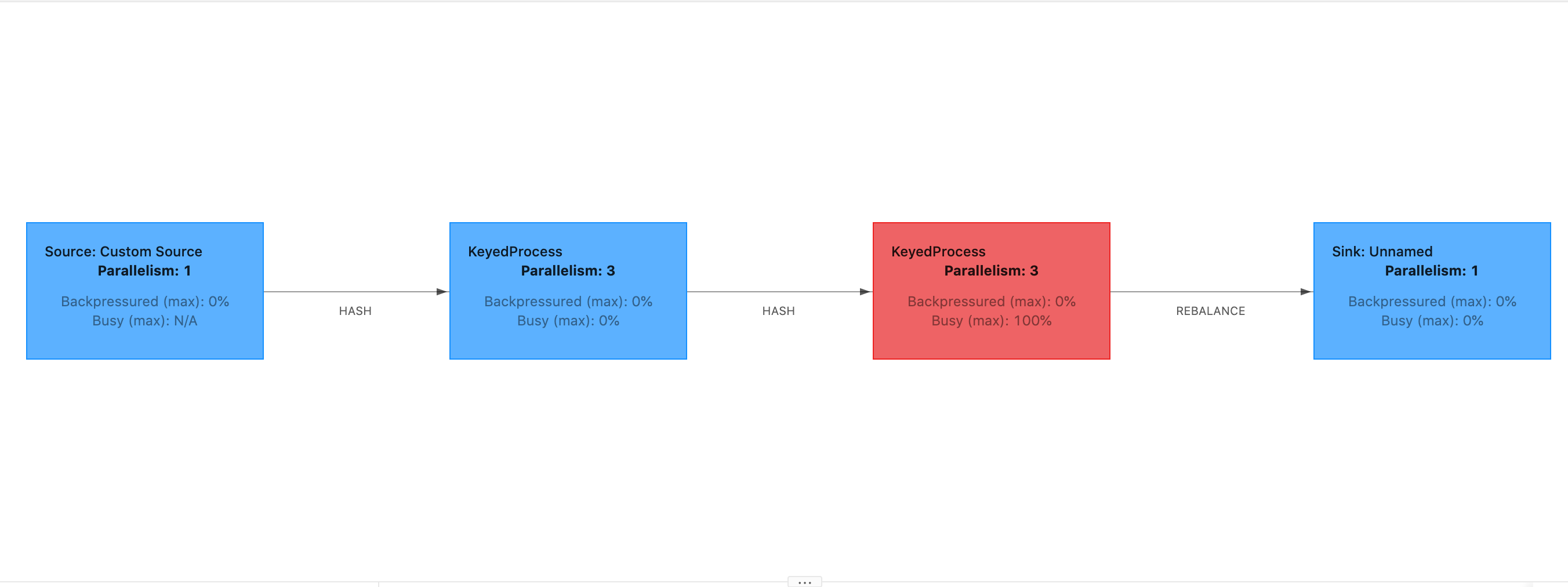
開始延遲高將表明等待檢查點障礙到達運算子花費了大部分時間。這表明應用程式正在花時間處理記錄,意味著障礙正在緩慢流經作業圖表。如果作業受到背壓或運算子經常處於忙碌狀態,通常就會發生這種情況。以下是作業圖表範例,其中第二個 KeyedProcess 運算子處於忙碌狀態。
您可以使用 Flink 火焰圖或 TaskManager 執行緒傾印來調查是什麼需要這麼長時間。一旦確定了瓶頸,就可以使用火焰圖或執行緒傾印進一步調查。
執行緒傾印
執行緒傾印是比火焰圖層級略低的另一種偵錯工具。執行緒傾印會在某個時間點輸出所有執行緒的執行狀態。Flink 接受 JVM 執行緒傾印,這是 Flink 處理序中所有執行緒的執行狀態。執行緒狀態由執行緒的堆疊追蹤以及一些附加資訊來表示。火焰圖實際上是使用快速連續採取的多個堆疊追蹤所建置。該圖形是由這些追蹤構成的可視化呈現,可讓您輕鬆地識別常見程式碼路徑。
"KeyedProcess (1/3)#0" prio=5 Id=1423 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:154) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>>19) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
以上是從 Flink UI 為單個執行緒取得的執行緒傾印的片段。第一行包含有關此執行緒的一些一般資訊,包括:
執行緒名稱 KeyedProcess (1/3)#0
執行緒優先順序 prio=5
唯一的執行緒 ID Id=1423
執行緒狀態 RUNNABLE
執行緒名稱通常會提供執行緒一般用途的資訊。運算子執行緒可以通過其名稱來識別,因為運算子執行緒與運算子具有相同的名稱,並且會指出其相關子任務,例如,KeyedProcess (1/3)#0 執行緒來自 KeyedProcess 運算子,並且來自第 1 個子任務 (共 3 個)。
執行緒可以是下列幾種狀態之一:
NEW:執行緒已建立,但尚未得到處理
RUNNABLE:執行緒正在 CPU 上執行
BLOCKED:執行緒正在等待另一個執行緒釋放其鎖定
WAITING:執行緒正在使用
wait()、join()或park()方法等待TIMED_WAITING:執行緒正在使用睡眠、等待、聯結或駐留方法等待,但等待時間最長。
注意
在 Flink 1.13 中,執行緒傾印中單一堆疊追蹤的最大深度限制為 8。
注意
執行緒傾印必須是 Flink 應用程式中偵錯效能問題的最後手段,因為它們可能難以讀取,需要擷取和手動分析多個樣本。如果有可能,最好使用火焰圖。
Flink 中的執行緒傾印
在 Flink 中,透過選擇 Flink UI 左側導覽列上的任務管理員選項,選取特定任務管理員,然後瀏覽至執行緒傾印標籤,即可取得執行緒傾印。您可以下載執行緒傾印、複製到喜愛的文字編輯器 (或執行緒傾印分析器),或直接在 Flink Web UI 的文字檢視中進行分析 (不過最後一個選項可能有點繁瑣)。
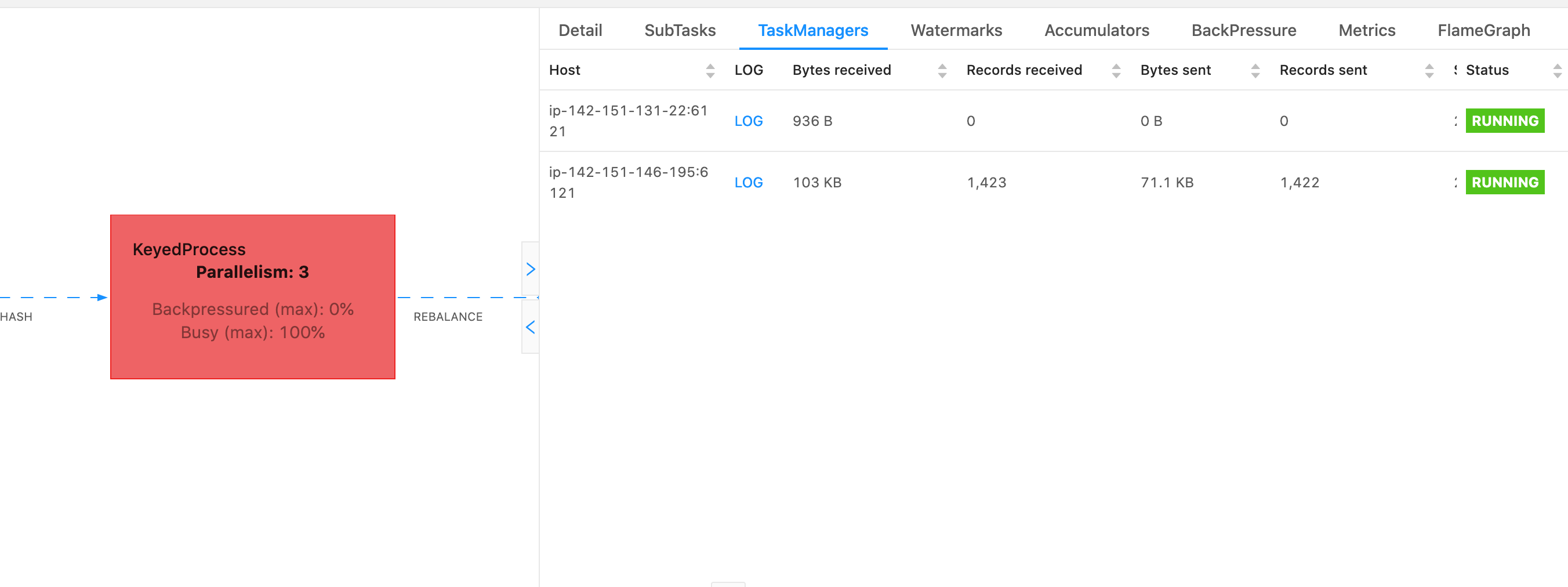
為了確定在選擇特定運算子後,要用來取得 TaskManager 選項卡執行緒傾印的任務管理員。這表明運算子正在運算子的不同子任務上執行,並且可以在不同的任務管理員上執行。
傾印將由多個堆疊追蹤組成。但是,在調查傾印時,與運算子關聯的傾印最重要。這些很容易找到,因為運算子執行緒與運算子具有相同的名稱,並且會指出與哪個子任務相關聯。例如,以下堆疊追蹤來自 KeyedProcess 運算子,並且是第 1 個子任務。
"KeyedProcess (1/3)#0" prio=5 Id=595 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:155) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:19) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
如果有多個運算子具有相同名稱,則可能會造成混淆,但我們可以透過命名運算子來解決這個問題。例如:
.... .process(new ExpensiveFunction).name("Expensive function")
火焰圖
火焰圖是一款有用的偵錯工具,它可以可視化目標程式碼的堆疊追蹤,從而允許識別最常見的程式碼路徑。它們透過對堆疊追蹤進行多次取樣來建立。火焰圖的 x 軸顯示不同的堆疊設定檔,y 軸顯示堆疊深度,以及堆疊追蹤中的呼叫。火焰圖中的單個矩形顯示在堆疊框架上,框架的寬度顯示它在堆疊中出現的頻率。如需火焰圖表及其用法的詳細資訊,請參閱火焰圖
在 Flink 中,運算子的火焰圖可以透過 Web UI 存取,方法是選取運算子,然後選擇火焰圖標籤。一旦收集到足夠的樣本,火焰圖即會顯示。以下是花費了大量時間執行檢查點的 ProcessFunction 的火焰圖。
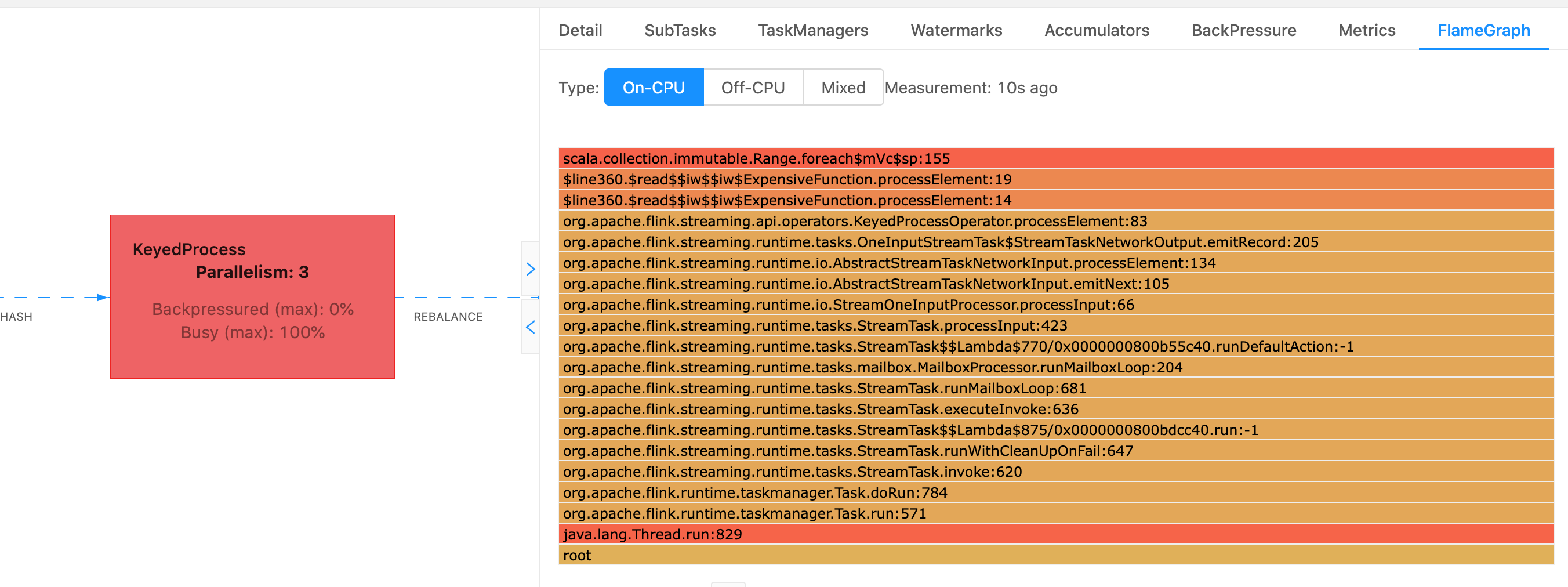
這是一個非常簡單的火焰圖,其中顯示了所有 CPU 時間都花費在一個 foreach 迴圈內的 ExpensiveFunction 運算子的 processElement 內。您還可以取得行號,以幫助確定程式碼的執行位置。
