本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
什麼是 Amazon Managed Service for Apache Flink?
透過 Amazon Managed Service for Apache Flink,您可以使用 Java、Scala、Python 或 SQL 來處理和分析串流資料。此服務可讓您針對串流來源和靜態來源撰寫和執行程式碼,以執行時間序列分析、饋送即時儀表板和指標。
您可以使用以 Apache Flink 為基礎的開放原始碼程式庫,在 Managed Service for Apache Flink
Managed Service for Apache Flink 可為 Apache Flink 應用程式提供基礎設施。它處理核心功能,例如佈建運算資源、AZ 容錯移轉彈性、平行運算、自動擴展和應用程式備份 (實作為檢查點和快照)。您可以使用高階 Flink 程式設計功能 (例如運算子、函數、來源和接收器),使用方式與您自行託管 Flink 基礎架構時相同。
決定使用 Managed Service for Apache Flink 或 Managed Service for Apache Flink Studio
您有兩個選項可以使用 Amazon Managed Service for Apache Flink 執行 Flink 任務。使用 Managed Service for Apache Flink,您可以使用您選擇的 IDE 和 Apache Flink Datastream 或 Table APIs,在 Java、Scala 或 Python (和內嵌 SQL) 中建置 Flink 應用程式。使用 Managed Service for Apache Flink Studio,您可以即時以互動方式查詢資料串流,並使用標準 SQL、Python 和 Scala 輕鬆建置和執行串流處理應用程式。
您可以選取最適合您的使用案例的方法。如果您不確定,本節將提供高階指引來協助您。
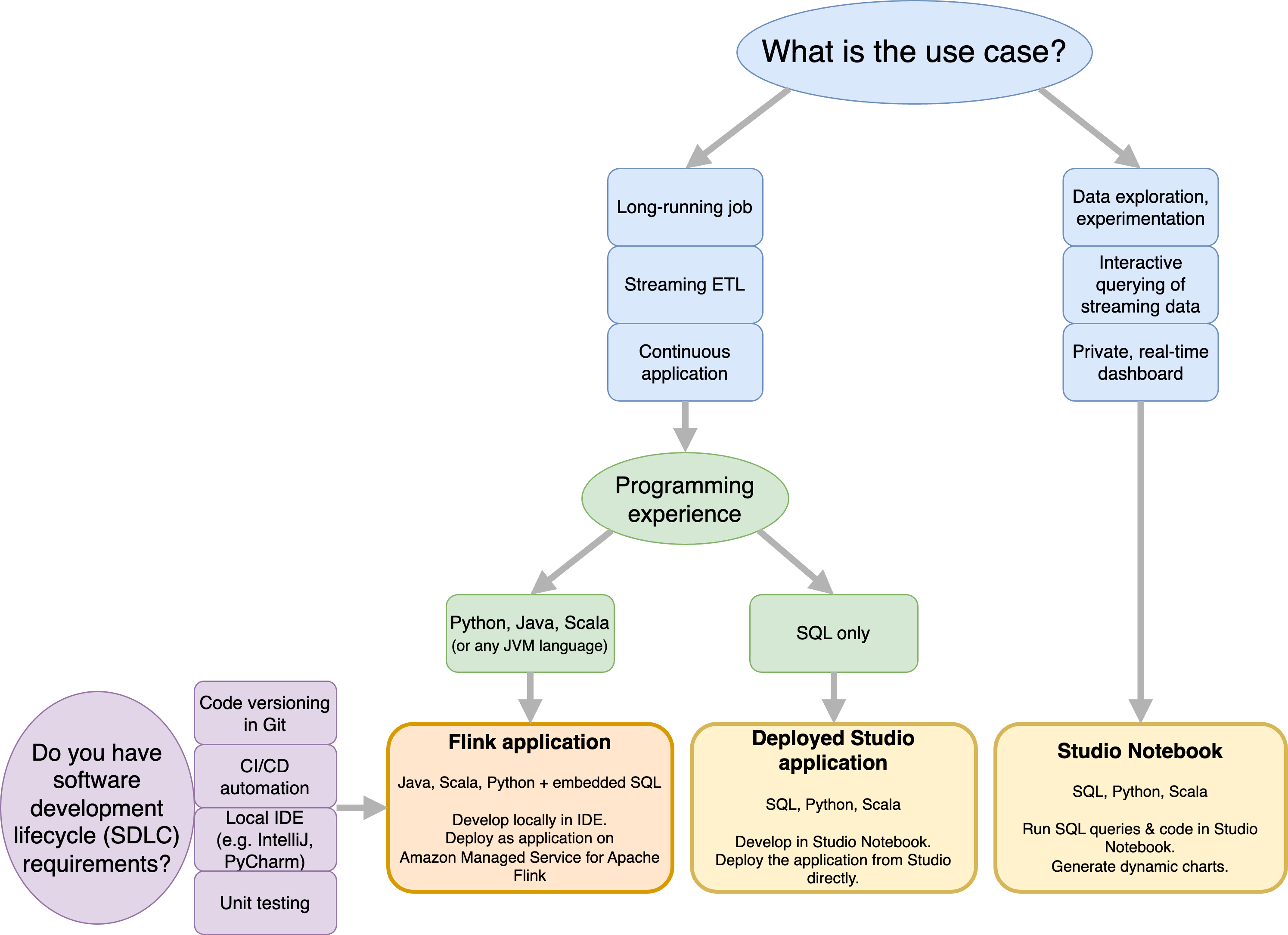
在決定是否使用 Amazon Managed Service for Apache Flink 或 Amazon Managed Service for Apache Flink Studio 之前,您應該考慮您的使用案例。
如果您計劃操作會處理串流 ETL 或持續應用程式等工作負載的長時間執行應用程式,您應該考慮使用 Managed Service for Apache Flink。這是因為您可以直接在您選擇的 IDE 中使用 Flink APIs 建立 Flink 應用程式。使用 IDE 在本機進行開發也可確保您可以利用軟體開發生命週期 (SDLC) 常見程序和工具,例如 Git 中的程式碼版本控制、CI/CD 自動化或單元測試。
如果您對臨機操作資料探索感興趣、想要以互動方式查詢串流資料,或建立私有即時儀表板,Managed Service for Apache Flink Studio 只需按幾下滑鼠就能協助您達成這些目標。熟悉 SQL 的使用者可以考慮直接從 Studio 部署長時間執行的應用程式。
注意
您可以將 Studio 筆記本提升為長時間執行的應用程式。不過,如果您想要與 SDLC 工具整合,例如 Git 和 CI/CD 自動化上的程式碼版本控制,或是單元測試等技術,建議您使用所選的 IDE 來 Managed Service for Apache Flink。
選擇要在 Managed Service for Apache Flink 中使用的 Apache Flink APIs
您可以在 Managed Service for Apache Flink 中使用 Java、Python 和 Scala,在您選擇的 IDE 中使用 Apache Flink APIs 來建置應用程式。您可以在 文件中找到如何使用 Flink Datastream 和資料表 API 建置應用程式的指引。您可以選擇您在 中建立 Flink 應用程式的語言,以及您用來最符合應用程式和操作需求的 APIs。如果您不確定,本節提供高階指引來協助您。
選擇 Flink API
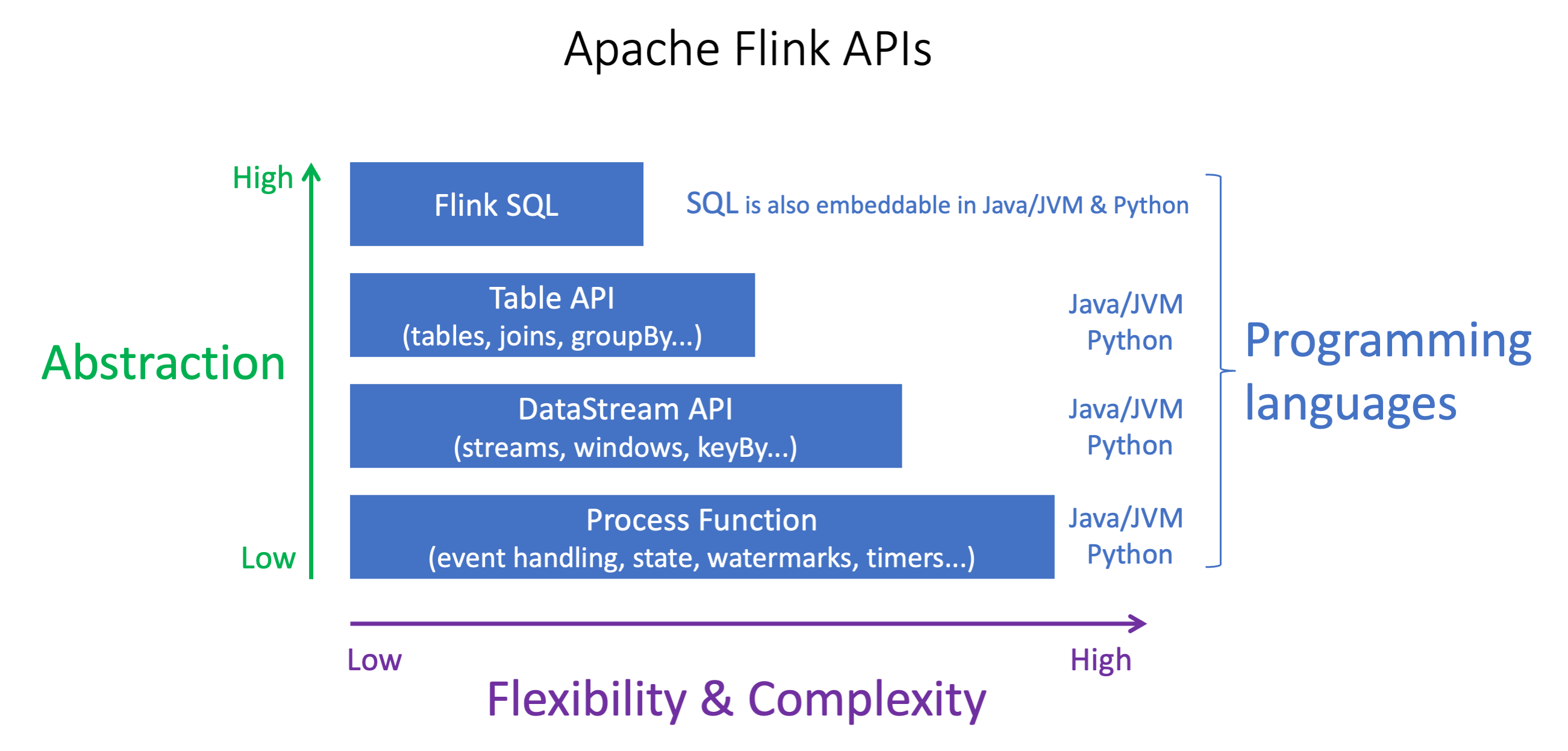
Apache Flink APIs 具有不同層級的抽象,可能會影響您決定建置應用程式的方式。它們具有表達性和彈性,可以一起使用來建置您的應用程式。您不需要僅使用一個 Flink API。您可以在 Apache Flink 文件中進一步了解 Flink
Flink 提供四個 API 抽象層級:Flink SQL、資料表 API、DataStream API 和 Process Function,可與 DataStream API 搭配使用。這些都支援 Amazon Managed Service for Apache Flink。建議您盡可能從更高層級的抽象開始,但某些 Flink 功能僅適用於 Datastream API,您可以在其中以 Java、Python 或 Scala 建立應用程式。在以下情況下,您應該考慮使用 Datastream API:
您需要精細控制狀態
您想要利用非同步呼叫外部資料庫或端點的能力 (例如推論)
您想要使用自訂計時器 (例如實作自訂視窗或延遲事件處理)
-
您希望能夠在不重設狀態的情況下修改應用程式的流程
注意
使用 DataStream API 選擇語言:
SQL 可以內嵌在任何 Flink 應用程式中,無論選擇何種程式設計語言。
如果您打算使用 DataStream API,則 Python 不支援所有連接器。
如果您需要低延遲/高輸送量,無論 API 為何,都應考慮 Java/Scala。
如果您計劃在 Process Functions API 中使用非同步 IO,則需要使用 Java。
API 的選擇也可能影響您發展應用程式邏輯的能力,而不必重設狀態。這取決於特定功能,即在運算子上設定 UID 的功能,僅適用於 Java 和 Python 的 DataStream API。如需詳細資訊,請參閱 Apache Flink 文件中的為所有運算子設定 UUIDs
開始使用串流資料應用程式
您可以先建立可持續讀取和處理串流資料的 Managed Service for Apache Flink 應用程式。然後,使用您選擇的 IDE 編寫程式碼,並使用即時串流資料對其進行測試。您也可以設定希望 Managed Service for Apache Flink 傳送結果的目的地。
建議您閱讀下列章節入門:
或者,您可以先建立 Managed Service for Apache Flink Studio 筆記本,讓您以互動方式即時查詢資料串流,並使用標準 SQL、Python 和 Scala 輕鬆建置和執行串流處理應用程式。只要在 中按幾下滑鼠 AWS Management Console,您就可以啟動無伺服器筆記本來查詢資料串流,並在幾秒鐘內取得結果。建議您閱讀下列章節入門:
