本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
了解連接器
連接器會將外部系統和 Amazon 服務與 Apache Kafka 整合,方法是持續將資料來源的串流資料複製到 Apache Kafka 叢集中,或持續將叢集中的資料複製到資料目的地中。在將資料傳送至目的地之前,連接器也可執行輕量型邏輯,例如轉換、格式轉換或篩選資料。來源連接器會從資料來源提取資料,並將此資料推送至叢集中,同時,目的地連接器則會從叢集提取資料,並將此資料推送至資料目的地中。
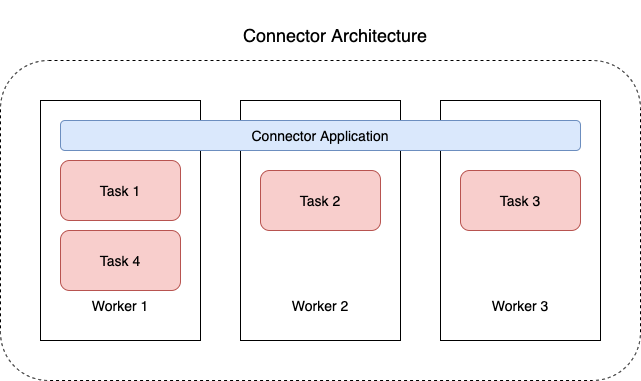
以下圖表說明連接器的架構。工作程序是執行連接器邏輯的 Java 虛擬機器 (JVM) 程序。每個工作程序皆會建立一組在平行執行緒中執行的任務,並執行複製資料的工作。任務不會存放狀態,因此可以隨時啟動、停止或重新啟動,以提供彈性且可擴展的資料管道。